vit专题

使用 VisionTransformer(VIT) FineTune 训练驾驶员行为状态识别模型
一、VisionTransformer(VIT) 介绍 大模型已经成为人工智能领域的热门话题。在这股热潮中,大模型的核心结构 Transformer 也再次脱颖而出证明了其强大的能力和广泛的应用前景。Transformer 自 2017年由Google提出以来,便在NLP领域掀起了一场革命。相较于传统的循环神经网络(RNN)和长短时记忆网络(LSTM), Transformer 凭借自注意力机制

Vision Transformer (ViT) + 代码【详解】
文章目录 1、Vision Transformer (ViT) 介绍2、patch embedding3、代码3.1 class embedding + Positional Embedding3.2 Transformer Encoder3.3 classifier3.4 ViT总代码 1、Vision Transformer (ViT) 介绍 VIT论文的摘要如下,谷歌

【王树森】Vision Transformer (ViT) 用于图片分类(个人向笔记)
图片分类任务 给定一张图片,现在要求神经网络能够输出它对这个图片的分类结果。下图表示神经网络有40%的信心认定这个图片是狗 ResNet(CNN)曾经是是图像分类的最好模型在有足够大数据做预训练的情况下,ViT要强于ResNetViT 就是Transformer Encoder网络 Split Image into Patches 在划分图片的时候,需要指定两个超参数 patch siz

YoloV8改进策略:主干网络改进|CAS-ViT在YoloV8中的创新应用与显著性能提升
摘要 在深度学习与计算机视觉领域,模型效率与性能之间的平衡一直是研究者和开发者关注的焦点。特别是在实时检测与识别任务中,如YoloV8这类高效的目标检测模型,其主干网络的选择对整体性能具有决定性作用。近期,我们通过将CAS-ViT(卷积加性自注意力视觉Transformer)创新性地引入到YoloV8中,替换其原有的主干网络,实现了令人瞩目的性能提升,这一改进不仅彰显了CAS-ViT的强大潜力,
![[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇](https://i-blog.csdnimg.cn/direct/5cd8f3334ae74386b28c9736370a95f2.jpeg#pic_center)
[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇
[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇 前情提要源码阅读导包逐行讲解 dataclass部分整体含义逐行解读 模型微调整体含义逐行解读 MultiModal类整体含义逐行解读 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 前情提要 有关多模态大模型架构中的语言模型部分
![[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - 语言模型篇(1)](/front/images/it_default2.jpg)
[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - 语言模型篇(1)
多模态大模型源码阅读 - 语言模型篇(1) 吐槽今日心得MQwen.py 吐槽 想要做一个以Qwen-7B-Insturct为language decoder, 以CLIP-VIT-14为vision encoder的image captioning模型,找了很多文章和库的源码,但是无奈都不怎么看得懂,刚开始打算直接给language decoder加上cross attent

CAS-ViT实战:使用CAS-ViT实现图像分类任务(二)
文章目录 训练部分导入项目使用的库设置随机因子设置全局参数图像预处理与增强读取数据设置Loss设置模型设置优化器和学习率调整策略设置混合精度,DP多卡,EMA定义训练和验证函数训练函数验证函数调用训练和验证方法 运行以及结果查看测试完整的代码 在上一篇文章中完成了前期的准备工作,见链接: CAS-ViT实战:使用CAS-ViT实现图像分类任务(一) 前期的工作主要是数据的准备,安
[CLIP-VIT-L + Qwen] 多模态大模型学习笔记 - 5
[CLIP-VIT-L + Qwen] 多模态大模型学习笔记 - 5 前情提要源码解读(visualModel类)init函数整体含义逐行解读 get_image_features函数(重构)整体含义逐行解读 main函数整体含义逐行解读 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 前情提要 有关多模态大模型架

CAS-ViT实战:使用CAS-ViT实现图像分类任务(一)
摘要 在视觉转换器(Vision Transformers, ViTs)领域,随着技术的不断发展,研究者们不断探索如何在保持高效性能的同时,降低模型的计算复杂度,以满足资源受限场景(如移动设备)的需求。近期,一种名为CAS-ViT(卷积加性自注意力视觉转换器)的模型横空出世,它以其出色的效率和性能平衡,被誉为“最快的ViT模型”,吸引了广泛的关注。 一、CAS-ViT的背景与动机 视觉转换
CLIP-VIT-L + Qwen 多模态学习笔记 -3
多模态学习笔记 - 3 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 吐槽 今天接着昨天的源码继续看,黑神话:悟空正好今天发售,希望广大coder能玩的开心~ 学习心得 前情提要 详情请看多模态学习笔记 - 2 上次我们讲到利用view()函数对token_type_ids、position_ids进行重新塑形,确保这些张量的最后

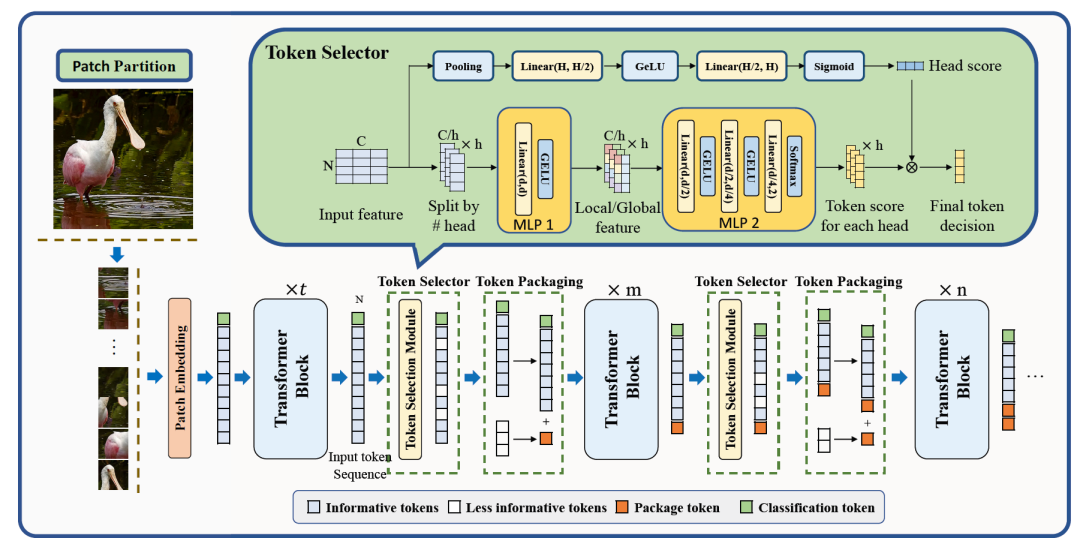
ViT:4 Pruning
实时了解业内动态,论文是最好的桥梁,专栏精选论文重点解读热点论文,围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。 视觉转换器(ViT)架构已经广受欢迎,并广泛用于计算机视觉应用。然而,随着 Vi
基于VIT获取天气信息的RT语音识别系统
基于VIT获取天气信息的RT语音识别系统 一, 文档简介二, 相关准备2.1 天气API平台2.2 postman测试天气API2.3 VIT自定义命令 三, 代码讲解3.1 LWIP socket 客户端代码获取天气API3.2 VIT识别自定义代码添加3.3 语音识别天气信息 四, 测试结果五, 问题总结5.1 LWIP获取天气失败5.2 VIT LWIP融合内存不足5.3 中文打印
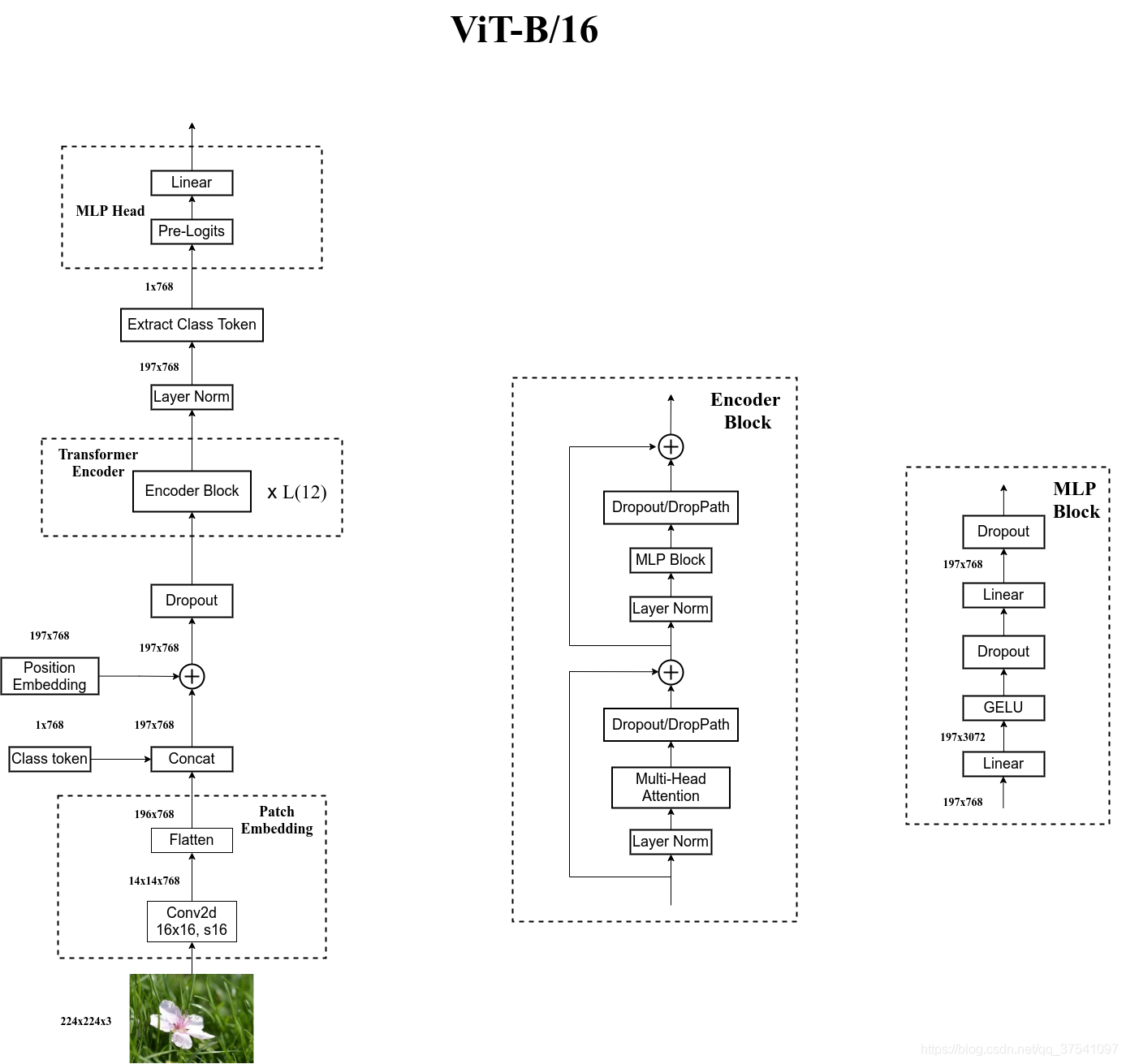
【深度学习】解析Vision Transformer (ViT): 从基础到实现与训练
之前介绍: https://qq742971636.blog.csdn.net/article/details/132061304 文章目录 背景实现代码示例解释 训练数据准备模型定义训练和评估总结 Vision Transformer(ViT)是一种基于transformer架构的视觉模型,它最初是由谷歌研究团队在论文《An Image is Worth 16x
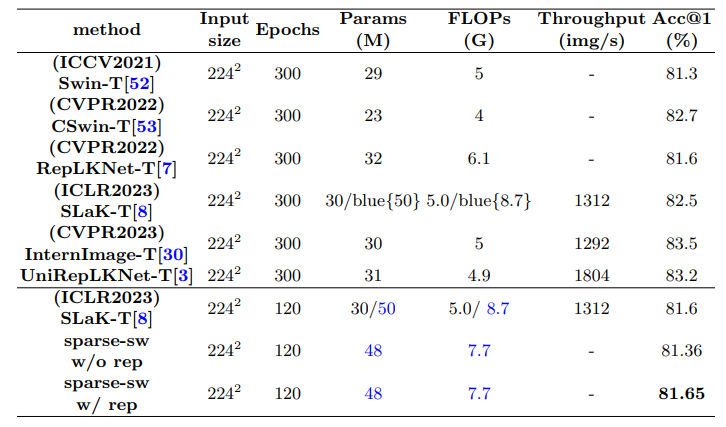
新一代大核卷积反超ViT和ConvNet!同参数量下性能、精度、速度完胜
大核卷积网络是CNN的一种变体,也是深度学习领域的一种重要技术,它使用较大的卷积核来处理图像数据,以提高模型对视觉信息的理解和处理能力。 这种类型的网络能够捕捉到更多的空间信息,因为它的大步长和大感受野可以一次性覆盖图像的更多区域。比如美团提出的PeLK网络,内核大小可以达到101x101,同参数量下性能反超 ViT,目前已被CVPR 2024收录。 更值得一提的,大核卷积网络不仅在性能上有所

论文阅读:H-ViT,一种用于医学图像配准的层级化ViT
来自CVPR的一篇文章,https://openaccess.thecvf.com/content/CVPR2024/papers/Ghahremani_H-ViT_A_Hierarchical_Vision_Transformer_for_Deformable_Image_Registration_CVPR_2024_paper.pdf 用CNN+Transformer混合模型做图像配准。可变

Python深度学习基于Tensorflow(17)基于Transformer的图像处理实例VIT和Swin-T
文章目录 VIT 模型搭建Swin-T 模型搭建参考 这里使用 VIT 和 Swin-T 在数据集 cifar10 上进行训练 VIT 模型搭建 导入需要的外部库 import numpy as npimport tensorflow as tfimport matplotlib.pyplot as pltimport matplotlib.gridspec as
ViT:2 理解CLIP
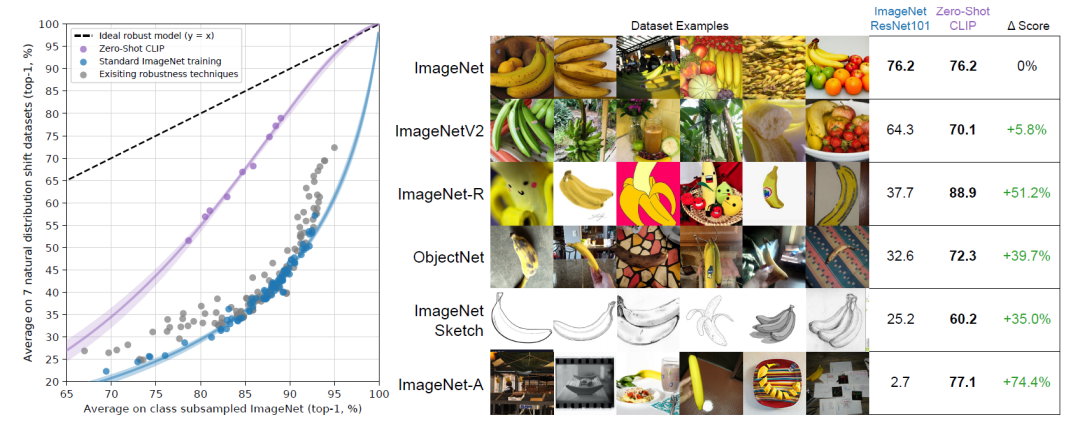
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。 语言-图像对比的预训练模型(CLIP)是由OpenAI开发的多模态学习架构

LeMeViT:具有可学习元令牌的高效ViT
本文提出使用可学习的元令牌来制定稀疏令牌,这有效地学习了关键信息,同时提高了推理速度。从技术上讲,主题标记首先通过交叉关注从图像标记中初始化。提出了双交叉注意(DCA)来促进图像令牌和元令牌之间的信息交换,其中它们在双分支结构中交替充当查询和密钥(值)令牌,与自注意相比,显著降低了计算复杂度。通过在具有密集视觉标记的早期阶段使用DCA,获得了不同大小的分层结构LeMeViT。在分类和密集预测任

(2024,Vision-LSTM,ViL,xLSTM,ViT,ViM,双向扫描)xLSTM 作为通用视觉骨干
Vision-LSTM: xLSTM as Generic Vision Backbone 公和众与号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0. 摘要 2 方法 3 实验 3.1 分类设计 4 结论 0. 摘要 Transformer 被广泛用作计算机视觉中的通用骨干网络,尽管它最初是为自然语言处理引入的。

(2024,ViT,小波变换,图像标记器,稀疏张量)基于小波的 ViT 图像标记器
Wavelet-Based Image Tokenizer for Vision Transformers 公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0 摘要 1 引言 3 基于小波的图像压缩简介 4 图像标记器 4.1 像素空间标记嵌入 4.2 语义标记嵌入 4.3 Transformer 层的操作计数

Stable Diffusion——U-ViT用于扩散建模的 ViT 主干网
1.概述 扩散模型是最近出现的强大的深度生成模型,可用于生成高质量图像。扩散模型发展迅速,可应用于文本到图像生成、图像到图像生成、视频生成、语音合成和 3D 合成。 除了算法的改进,骨干网的改进在扩散建模中也发挥着重要作用。一个典型的例子是基于卷积神经网络(CNN)的 U-Net,它已被用于之前的研究中。 基于 CNN 的 UNet 的特点是一系列下采样块、一系列上采样块以及这些组之间的长跳接
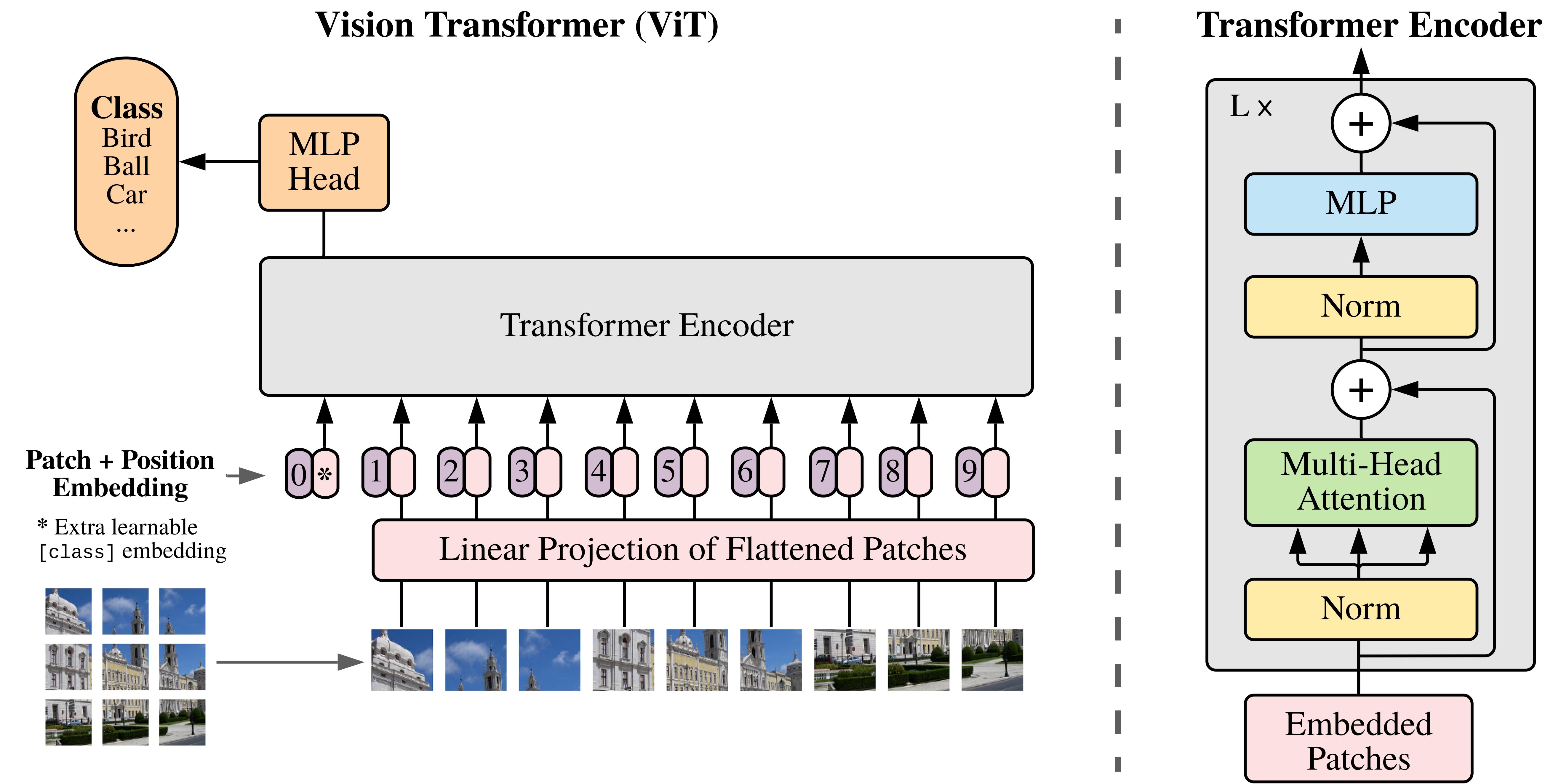
Vision Transformer (ViT)浅析
Vision Transformer (ViT) 概述 为了将Transformer引入视觉任务,Google团队开发出了Vision Transformer (ViT),其中ViT模型以及变种在图像分类任务上一骑绝尘 ViT的结构 ViT首先将图像( R H × W × C \mathbb{R}^{H\times W\times C} RH×W×C)划分为多个Patch( P ×
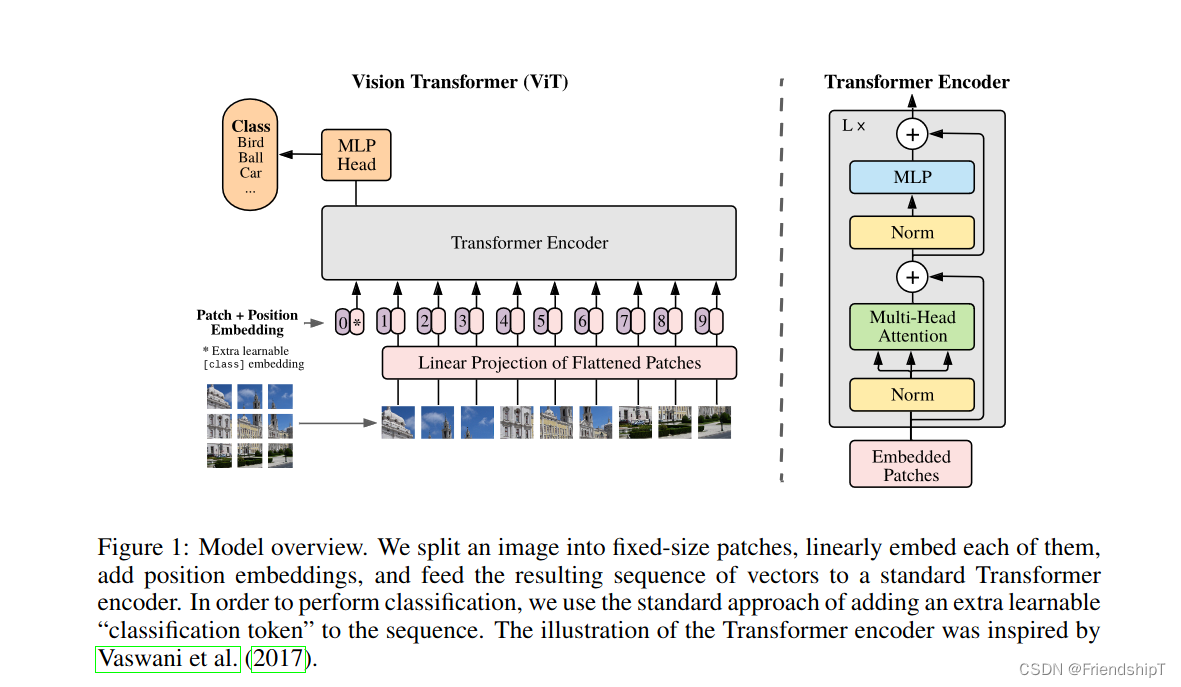
图像分类:Pytorch实现Vision Transformer(ViT)进行图像分类
图像分类:Pytorch实现Vision Transformer(ViT)进行图像分类 前言相关介绍ViT模型的基本原理:ViT的特点与优势:ViT的缺点:应用与拓展: 项目结构具体步骤准备数据集读取数据集设置并解析相关参数定义网络模型定义损失函数定义优化器训练 参考 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容,可点击进入人工智能知识点专栏、Pyth

YOLOv5算法进阶改进(20)— 更换主干网络之RepViT | 从ViT视角重新审视移动CNN
前言:Hello大家好,我是小哥谈。RepViT是一种基于Transformer的视觉模型,它的全称是Representation Learning with Visual Tokens。与传统的卷积神经网络不同,RepViT使用了Transformer的自注意力机制来提取图像中的特征。具体来说,RepViT将图像分成若干个视觉标记(visual tokens),然后将这些标记作为Trans

ViT:拉开Trasnformer在图像领域正式挑战CNN的序幕 | ICLR 2021
论文直接将纯Trasnformer应用于图像识别,是Trasnformer在图像领域正式挑战CNN的开山之作。这种简单的可扩展结构在与大型数据集的预训练相结合时,效果出奇的好。在许多图像分类数据集上都符合或超过了SOTA,同时预训练的成本也相对较低 来源:晓飞的算法工程笔记 公众号 论文: An Image is Worth 16x16 Words: Transformers for