本文主要是介绍ViT:拉开Trasnformer在图像领域正式挑战CNN的序幕 | ICLR 2021,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文直接将纯Trasnformer应用于图像识别,是Trasnformer在图像领域正式挑战CNN的开山之作。这种简单的可扩展结构在与大型数据集的预训练相结合时,效果出奇的好。在许多图像分类数据集上都符合或超过了SOTA,同时预训练的成本也相对较低
来源:晓飞的算法工程笔记 公众号
论文: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale

- 论文地址:https://arxiv.org/abs/2010.11929
- 论文代码:https://github.com/google-research/vision_transformer
Introduction
基于自注意力的架构,尤其是Transformers,已成为NLP任务的首选模型。通常的用法是先在大型文本语料库上进行预训练,然后在较小的特定任务数据集上fine-tuning。得益于Transformers的计算效率和可扩展性,训练超过100B参数的模型成为了可能。而且随着模型和数据集的继续增长,模型仍然没有性能饱和的迹象。
在计算机视觉中,卷积网络仍然占主导地位。受NLP的启发,多项工作尝试将CNN的结构与self-attention进行结合(比如DETR:Facebook提出基于Transformer的目标检测新范式 | ECCV 2020 Oral),其中一些则尝试完全替换卷积(比如实战级Stand-Alone Self-Attention in CV,快加入到你的trick包吧 | NeurIPS 2019)。 完全替换卷积的模型虽然理论上有效,但由于使用了特殊的注意力结构,尚未能在现代硬件加速器上有效地使用。因此,在大规模图像识别中,经典的ResNet类型仍然是最主流的。
为此,论文打算不绕弯子,直接将标准Transformer应用于图像。先将图像拆分为图像块,块等同于NLP中的token,然后将图像块映射为embedding序列作为Transformer的输入,最后以有监督的方式训练模型进行图像分类。
但论文通过实验发现,不加强正则化策略在ImageNet等中型数据集上进行训练时,这些模型的准确率比同等大小的ResNet低几个百分点。这个结果是意料之中的,因为Transformers缺乏CNN固有的归纳偏置能力,例如平移不变性和局部性。在数据量不足的情况下,训练难以很好地泛化。但如果模型在更大的数据集(14M-300M图像)上训练时,情况则发生了反转,大规模训练要好于归纳偏置。为此,论文将在规模足够的数据集上预训练的Vision Transformer(ViT)迁移到数据较少的任务,得到很不错的结果。
在公开的ImageNet-21k数据集或内部的JFT-300M数据集上进行预训练后,ViT在多个图像识别任务上接近或超过了SOTA。其中,最好的模型在ImageNet上达到88.55%,在ImageNet-ReaL上达到90.72%,在CIFAR-100上达到94.55%,在包含19个视觉任务的VTAB标准上达到77.63%。
Method
在模型设计中,论文尽可能地遵循原生的Transformer结构。这样做的好处在于原生的Transformer结构已经被高效地实现,可以开箱即用的。
Vision Transformer(ViT)

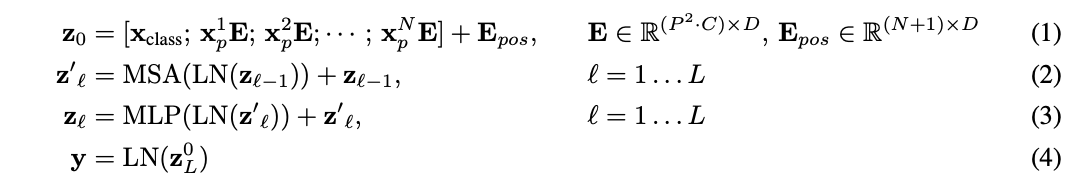
模型的整体结构如图1所示,计算流程如公式1-4所示,主要有以下几个要点:
- 输入处理:标准Transformer接收一维embedding序列作为输入,为了处理二维图像,先将图像 x ∈ R H × W × C x\in R^{H\times W\times C} x∈RH×W×C重排为二维块序列 x p ∈ R N × ( P 2 × C ) x_p\in R^{N\times (P^2\times C)} xp∈RN×(P2×C),其中 ( H , W ) (H, W) (H,W)为原图像的分辨率, C C C是通道数, ( P , P ) (P, P) (P,P)是每个图像块的分辨率, N = H W / P 2 N=HW/P^2 N=HW/P2是生成的块数量,也是Transformer的有效输入序列长度。Transformer所有层使用向量的维度均为 D D D,需要先使用可训练的公式1将二维图像块线性映射到 D D D维,映射的输出称为图像块embedding。
- class token:类似于BERT在输入序列开头插入[class]token,论文同样在图像块embedding序列中预先添加一个可学习的class token( z 0 0 = x c l a s s z^0_0=x_{class} z00=xclass),并将其在Transformer encoder中的对应输出( z L 0 z^0_L zL0)经公式4转换为图像特征 y y y。在预训练和fine-tuning期间,分类head都接到 z L 0 z^0_L zL0上。分类head在预训练时由仅有单隐藏层的MLP实现,而在fine-tuning时由单线性层实现。
- position embedding:添加position embedding到图像块embedding中可以增加位置信息,用合并的embedding序列用作encoder的输入。论文使用标准的可学习1D position embedding,使用更复杂的2D-aware position embedding并没有带来的显着性能提升。
- Transformer encoder:Transformer encoder是主要的特征提取模块,由multiheaded self-attention模块和MLP模块组成,每个模块前面都添加Layernorm(LN)层以及应用残差连接。MLP包含两个具有GELU非线性激活的全连接层,这是point-wise的,不是对整个token输出。self-attention的介绍可以看看附录A或公众号的实战级Stand-Alone Self-Attention in CV,快加入到你的trick包吧 | NeurIPS 2019)文章。
Inductive bias
论文注意到,在Vision Transformer中,图像特定的归纳偏置比CNN要少得多。在CNN中,局部特性、二维邻域结构信息(位置信息)和平移不变性贯彻了模型的每一层。而在ViT中,自注意力层是全局的,只有MLP层是局部和平移不变的。
ViT使用的二维邻域结构信息非常少,只有在模型开头将图像切割成图像块序列时以及在fine-tuning时根据图像的分辨率调整对应的position embedding有涉及。此外,初始的position embedding仅有图像块的一维顺序信息,不包含二维空间信息,所有图像块间的空间关系必须从头开始学习。
Hybrid Architecture
作为图像块的替代方案,输入序列可以由CNN的特征图映射产生,构成混合模型中。将公式1中映射得到图像块embedding E E E替换为从CNN提取的特征图中映射得到的特征块embedding,然后跟前面一样添加插入[class] token和position embedding进行后续计算。
有一种特殊情况,特征块为 1 × 1 1\times 1 1×1的空间大小。这意味着输入embedding序列通过简单地将特征图按空间维度展开,然后映射到Transformer维度得到。
Fine-Tuning and Higher Resolution
通常,ViT需要先在大型数据集上预训练,然后在(较小的)下游任务fine-tuning。为此,在fine-tuning时需要将预训练的预测头替换为零初始化的 D × K D\times K D×K前向层, K K K为下游任务的类数量。
根据已有的研究,fine-tuning时使用比预训练高的分辨率通常可以有更好的效果。但使用更高分辨率的图像时,如果保持图像块大小相同,产生的embedding序列会更长。虽然Vision Transformer可以处理任意长度的序列,但预训练得到的position embedding将会失去意义。因此,论文提出根据原始图像中的位置对预训练的position embedding进行2D插值,然后进行fine-tuning训练。
值得注意的是,这种分辨率相关的调整以及模型开头的图像块的提取是Vision Transformer中少有的手动引入图像二维结构相关的归纳偏置的点。
Experiment
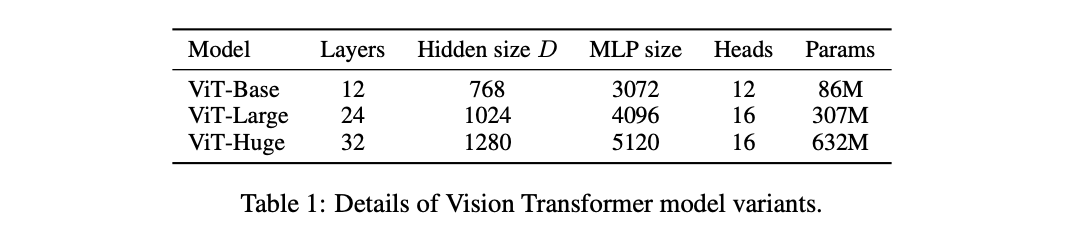
论文设计了三种不同大小的ViT,结构参数如上。
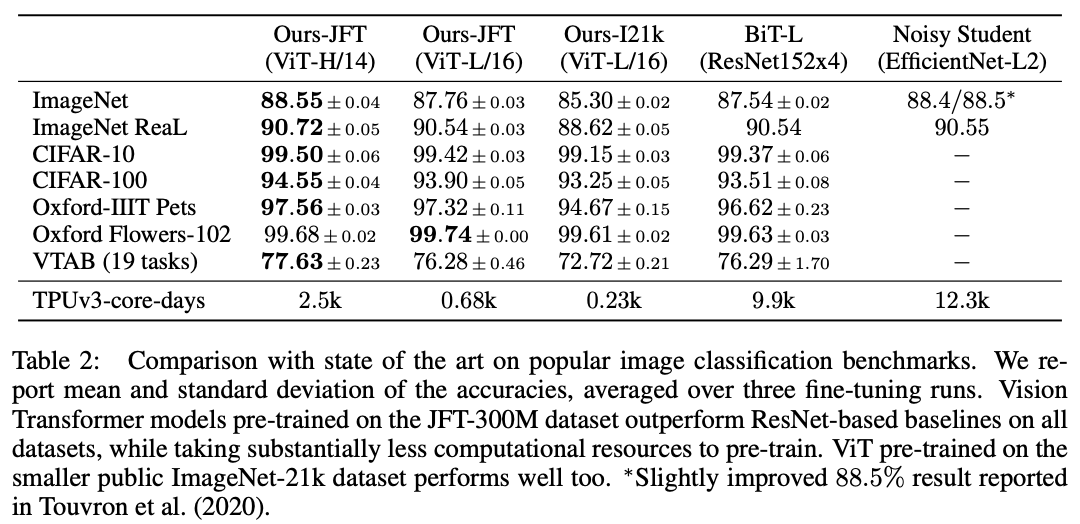
分类性能对比,不同模型、不同预训练数据集在不同分类训练集上的表现。

将VTAB任务拆分与SOTA模型进行对比,其中VIVI是在ImageNet和Youtube数据集上训练的ResNet类模型。

预训练数据集与迁移数据集上的性能关系对比,预训练数据集小更适合使用ResNet类模型。

预训练数据集与few-shot性能对比,直接取输出特征进行逻辑回归。

预训练消耗与迁移后性能的对比。
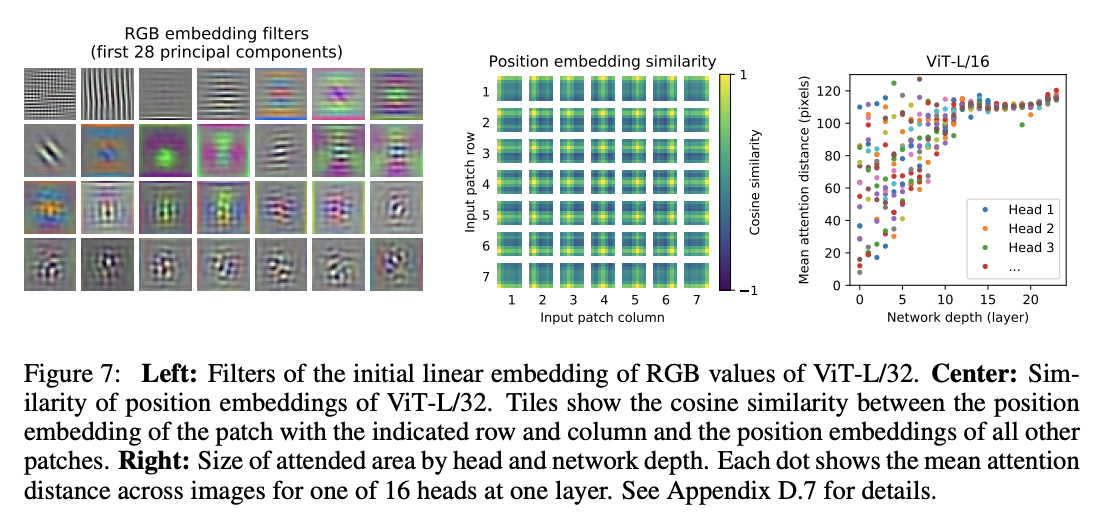
可视化ViT:
- 公式1的前28个线性映射参数的权值主成分分析,主成分差异代表提取的特征较丰富。
- position embedding之间的相关性,约近的一般相关性越高。
- 每层的self-attention中每个head的平均注意力距离(类似于卷积的感受域大小),越靠前的关注的距离更远,往后则越近。
Conclusion
论文直接将纯Trasnformer应用于图像识别,是Trasnformer在图像领域正式挑战CNN的开山之作。这种简单的可扩展结构在与大型数据集的预训练相结合时,效果出奇的好。在许多图像分类数据集上都符合或超过了SOTA,同时预训练的成本也相对较低。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

这篇关于ViT:拉开Trasnformer在图像领域正式挑战CNN的序幕 | ICLR 2021的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)

