iclr专题

论文翻译:ICLR-2024 PROVING TEST SET CONTAMINATION IN BLACK BOX LANGUAGE MODELS
PROVING TEST SET CONTAMINATION IN BLACK BOX LANGUAGE MODELS https://openreview.net/forum?id=KS8mIvetg2 验证测试集污染在黑盒语言模型中 文章目录 验证测试集污染在黑盒语言模型中摘要1 引言 摘要 大型语言模型是在大量互联网数据上训练的,这引发了人们的担忧和猜测,即它们可能已
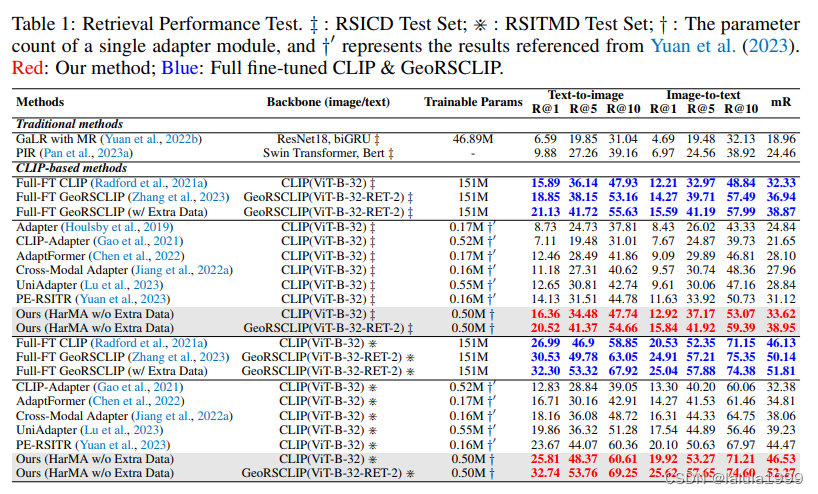
(ICLR,2024)HarMA:高效的协同迁移学习与模态对齐遥感技术
文章目录 相关资料摘要引言方法多模态门控适配器目标函数 实验 相关资料 论文:Efficient Remote Sensing with Harmonized Transfer Learning and Modality Alignment 代码:https://github.com/seekerhuang/HarMA 摘要 随着视觉和语言预训练(VLP)的兴起,越来越多的

CPVT(ICLR 2023)论文解读
paper:Conditional Positional Encodings for Vision Transformers official implementation:GitHub - Meituan-AutoML/CPVT 存在的问题 位置编码的局限性:传统Transformer中的绝对位置编码(无论是可学习的还是固定的)在训练时会固定编码的长度和数值,导致模型在测试时难以处理比训练

首个ICLR时间检验奖出炉,机器学习大牛Max Welling和OpenAI创始团队成员Diederik Kingma获奖
国际表征学习大会(ICLR)是机器学习领域的一个学术会议,每年一次,通常在每年四月底或五月初举行。会议包括特邀演讲以及经评审论文的口头和海报展示。 ICLR 由 Yann LeCun(杨立昆)和 Yoshua Bengio 两位图灵奖得主创立,被学术研究者们广泛认可,被认为是“深度学习的顶级会议“。自 2013 年举办首届起,该会议一直采用开放式同行评审。 ICLR 已进入第 12 个年头!为

ICLR 2017 | 基于双向注意力流的机器理解
本文提出了双向注意力流(BIDAF)网络,是一种分层的多阶段架构,在不同粒度等级上对上下文进行建模。BIDAF包括字符级(character-level)、单词级(word-level)和上下文(contextual)的embedding,并使用双向注意力流来获取query-aware的上下文表示。 论文地址: https://arxiv.org/abs/1611.01603 代码地址: htt
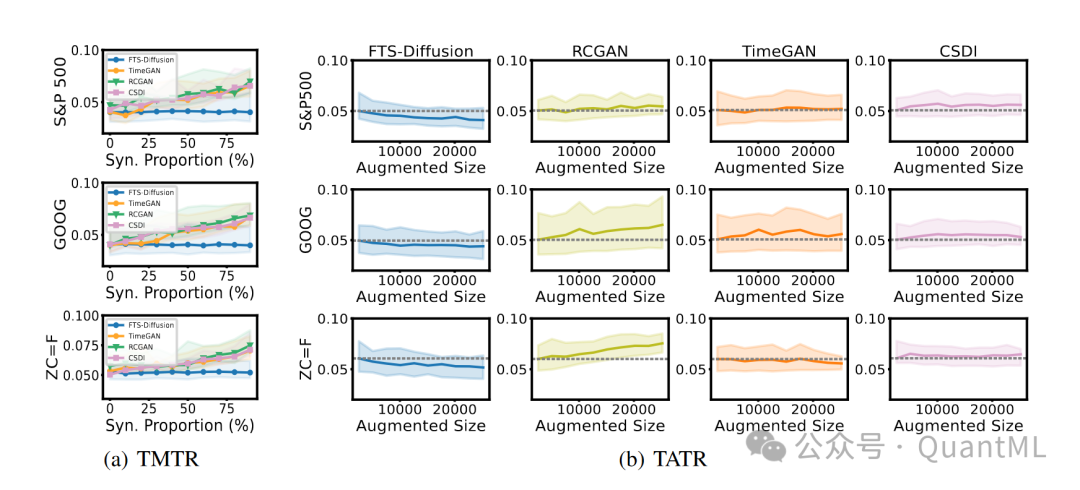
ICLR 2024 | FTS-Diffusion: 用于合成具有不规则和尺度不变模式的金融时间序列的生成框架
ICLR 2024 | FTS-Diffusion: 用于合成具有不规则和尺度不变模式的金融时间序列的生成框架 原创 QuantML QuantML 2024-04-17 09:53 上海 Content 本文提出了一个名为FTS-Diffusion的新颖生成框架,用于模拟金融时间序列中的不规则和尺度不变模式。这些模式由于其独特的时间动态特性(即模式在持续时间和幅度上的变化重复)而难以用

计算机常见的六大会议介绍:CVPR/ICCV/ECCV;NeurIPS/ICML/ICLR
计算机常见的六大会议介绍:CVPR/ICCV/ECCV;NeurIPS/ICML/ICLR CVPR、ICCV和ECCV是计算机视觉领域顶级的三个国际会议,而NeurIPS、ICML和ICLR则是机器学习领域最具影响力的三个国际会议。下面是它们的详细介绍: 计算机视觉领域 CVPR (Computer Vision and Pattern Recognition) 主办方:IEEE频率:

ViT:拉开Trasnformer在图像领域正式挑战CNN的序幕 | ICLR 2021
论文直接将纯Trasnformer应用于图像识别,是Trasnformer在图像领域正式挑战CNN的开山之作。这种简单的可扩展结构在与大型数据集的预训练相结合时,效果出奇的好。在许多图像分类数据集上都符合或超过了SOTA,同时预训练的成本也相对较低 来源:晓飞的算法工程笔记 公众号 论文: An Image is Worth 16x16 Words: Transformers for

ICLR 2024 | 联邦学习后门攻击的模型关键层
ChatGPT狂飙160天,世界已经不是之前的样子。 新建了免费的人工智能中文站https://ai.weoknow.com 新建了收费的人工智能中文站https://ai.hzytsoft.cn/ 更多资源欢迎关注 联邦学习使多个参与方可以在数据隐私得到保护的情况下训练机器学习模型。但是由于服务器无法监控参与者在本地进行的训练过程,参与者可以篡改本地训练模型,从而对联邦学习的
ICLR 2024 | 鸡生蛋蛋生鸡?再论生成数据能否帮助模型训练
ChatGPT狂飙160天,世界已经不是之前的样子。 新建了人工智能中文站https://ai.weoknow.com 每天给大家更新可用的国内可用chatGPT资源 发布在https://it.weoknow.com 更多资源欢迎关注 随着生成模型(如 ChatGPT、扩散模型)飞速发展,一方面,生成数据质量越来越高,到了以假乱真的程度;另一方面,随着模型越来越大,也使得

ICLR 2022 | 涨点神器!Intel提出ODConv:即插即用的动态卷积
点击下方卡片,关注“CVer”公众号 AI/CV重磅干货,第一时间送达 转载自:极市平台 | 作者:happy 导读 本文介绍了一篇动态卷积的工作:ODConv,其通过并行策略采用多维注意力机制沿核空间的四个维度学习互补性注意力。作为一种“即插即用”的操作,它可以轻易的嵌入到现有CNN网络中。并且实验结果表明它可提升大模型的性能,又可提升轻量型模型的性能,实乃万金油是也! Omni-D
顶级会议ICLR论文解读丨语法制导翻译VAE如何回答一代宗师叶问
原创作者:谭婧 美编:陈泓宇 -随堂测验- 俗话说,南拳北腿。 咏春拳作为经典的南派功夫,讲究贴身近击、连消带打与攻守合一。咏春高手的双手知觉灵敏且变化多端,防守时密不透风、滴水不漏,进攻时犹如水银泻地、插缝即入。初看斯文冷静、再看后发先至、以疾如风的速度、爆发出雷霆之力对敌。 叶问VS生成模型。 一代宗师叶问先生笑意慈祥,摆出咏春拳的标志性——问路手, 说道:“咏春,叶问。” 见此状后

顶级会议ICLR论文解读,语法制导翻译VAE如何回答一代宗师叶问
原创作者:谭婧 美编:陈泓宇 -随堂测验- 俗话说,南拳北腿。 咏春拳作为经典的南派功夫,讲究贴身近击、连消带打与攻守合一。咏春高手的双手知觉灵敏且变化多端,防守时密不透风、滴水不漏,进攻时犹如水银泻地、插缝即入。初看斯文冷静、再看后发先至、以疾如风的速度、爆发出雷霆之力对敌。 叶问VS生成模型。 一代宗师叶问先生笑意慈祥,摆出咏春拳的标志性——问路手, 说道:“咏春,叶
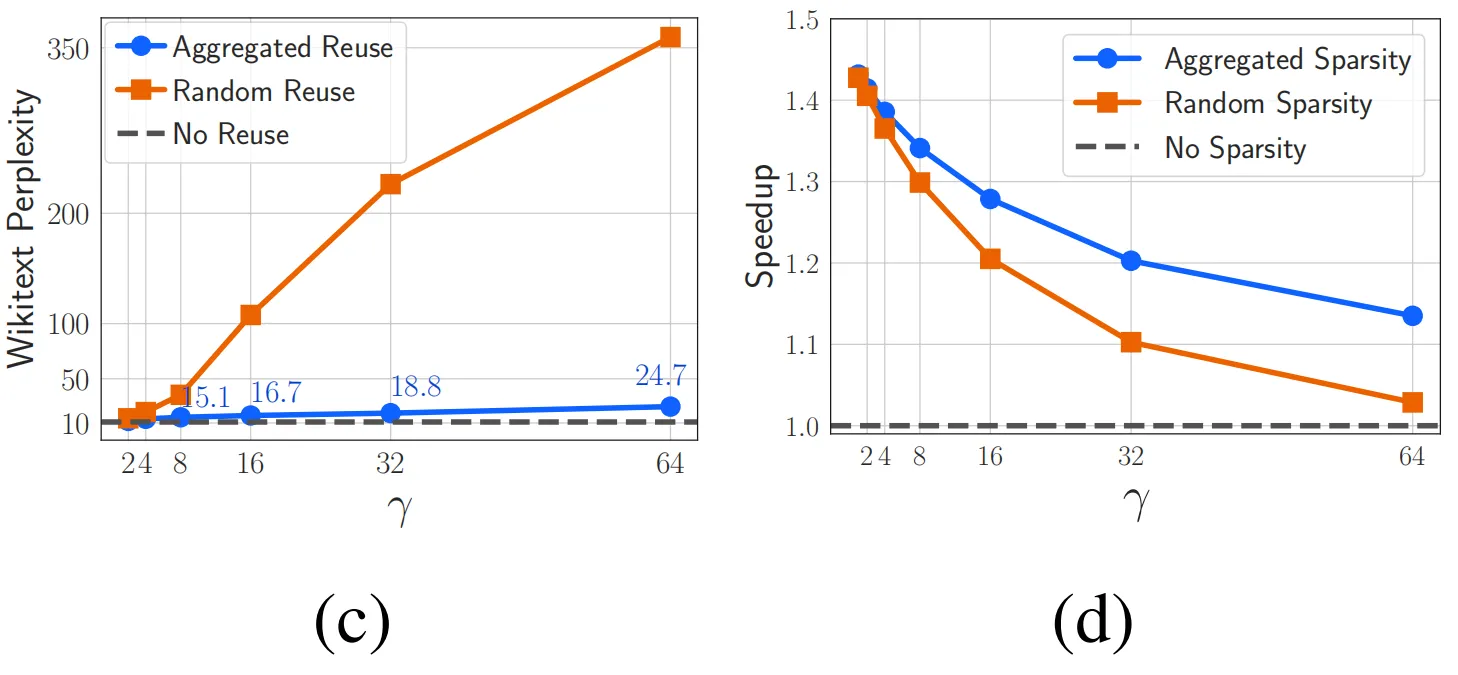
ICLR 2024|ReLU激活函数的反击,稀疏性仍然是提升LLM效率的利器
论文题目: ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models 论文链接: https://arxiv.org/abs/2310.04564 参数规模超过十亿(1B)的大型语言模型(LLM)已经彻底改变了现阶段人工智能领域的研究风向。越来越多的工业和学术研究者开始研究LLM领域
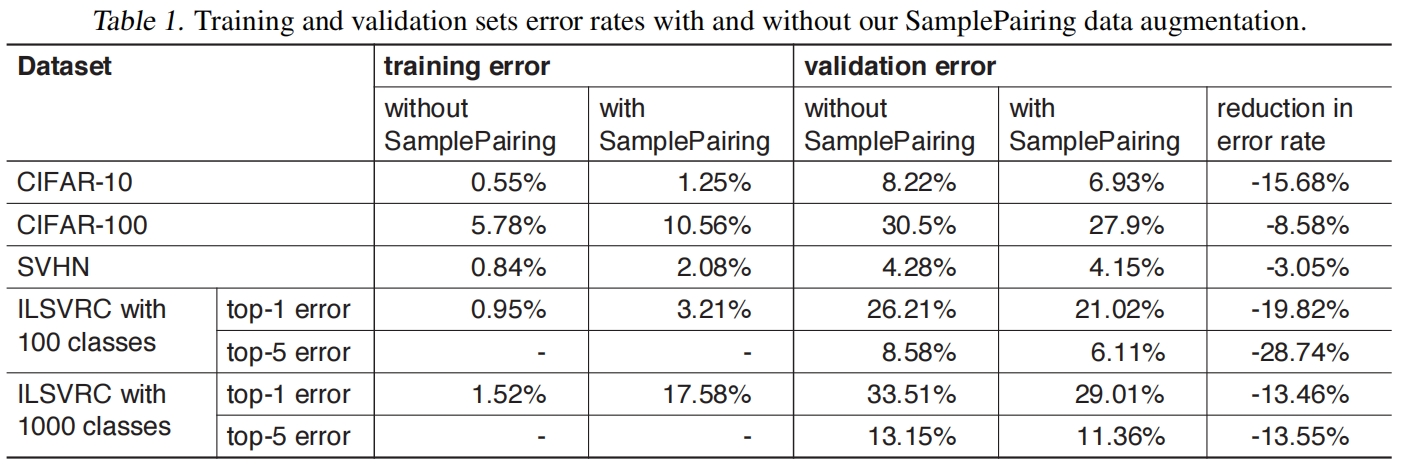
Sample Pairing(ICLR 2018)
paper:Data Augmentation by Pairing Samples for Images Classification 本文的创新点 本文提出了一种新的应用于图像分类的数据增强方法SamplePairing,这种简单的数据增强技术显著提高了所有测试的数据集的分类精度。此外当训练集中的样本数量非常少时,SamplePairing技术很大程度的提高了精度,因此该方法对于训练数据非

ICLR 2024 | Mol-Instructions: 面向大模型的大规模生物分子指令数据集
发表会议:ICLR 2024 论文标题:Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models 论文链接:https://arxiv.org/pdf/2306.08018.pdf 代码链接:https://github.com/zjunlp/Mol-Instructio

ICLR 2024 | MolGen: 化学反馈引导的预训练分子生成
MolGen: 化学反馈引导的预训练分子生成 英文题目:Domain-Agnostic Molecular Generation with Chemical Feedback 发表会议:ICLR 2024 论文链接:https://arxiv.org/abs/2301.11259 代码链接:https://github.com/zjunlp/MolGen 目录 引言 MolGen的训练
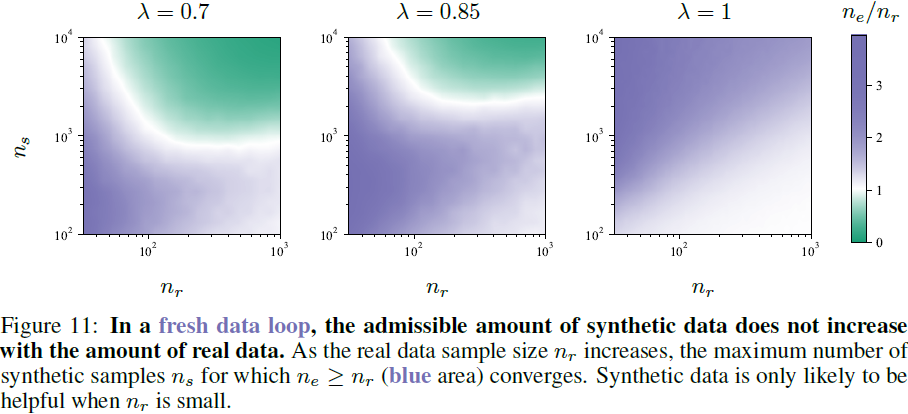
(2024|ICLR,MAD,真实数据与合成数据,自吞噬循环)自消耗生成模型变得疯狂
Self-Consuming Generative Models Go MAD 公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0. 摘要 2. 自吞噬生成模型 2.1 自吞噬过程 2.2 自吞噬过程的变体 2.3 自吞噬循环中的偏向采样 2.4 MADness 的度量 3. 完全合成循环:完全在合成数据上进行训练导致

ICLR‘2024时间序列论文汇总!预测、分析、分类等方向的最新进展
ICLR作为机器学习领域的顶级国际会议,每年都吸引了全球众多顶尖学者和研究者的目光。2024的ICLR会议,将在5月7日至11日在奥地利的维也纳会展中心举行,现在会议论文审稿结果也已经出来了,本届ICLR 2024共收到了7262篇提交论文,整体接收率约为31%。 今天给大家从中整理了一些时间序列领域的高分论文,涵盖了预测、分析、分类、对比学习和插补研究方向,这些论文展示了时间序列领域最新的
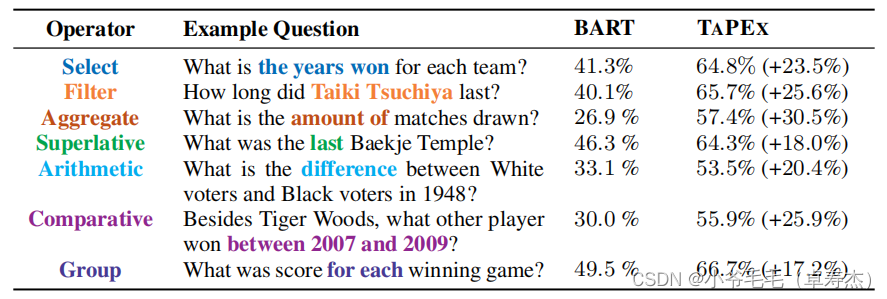
【微软】【ICLR 2022】TAPEX:通过学习神经 SQL 执行器进行表预训练
重磅推荐专栏: 《大模型AIGC》;《课程大纲》 本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展 论文:https://arxiv.org/abs/2107

【神经网络】2016-ICLR-通过扩张卷积进行多尺度上下文聚合
2016-ICLR-Multi-Scale Context Aggregation by Dilated Convolutions 通过扩张卷积进行多尺度上下文聚合摘要1. 引言2. 扩张卷积3. 多尺度上下文聚合4. 前端(front-end) 5. 实验6. 结论参考文献附录 A 城市场景理解A.1 CAMVIDA.2 KITTIA.3 CITYSCAPES 通过扩张卷积进
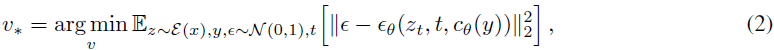
(2023|ICLR,文本反演,LDM,伪词)一个词描述一张图像:使用文本反演个性化文本到图像的生成
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion 公纵号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料) 目录 0. 摘要 1. 简介 2. 相关工作 3. 方法 4. 定性比较和应用 4.1 图像变化

(ICLR-2021)一幅图像相当于16X16个words:大规模图像识别的Transformer
一幅图像相当于16X16个words:大规模图像识别的Transformer paper题目:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE paper是Google发表在ICLR 2021的工作 paper地址:链接 ABSTRACT 虽然Transformer体系结
论文笔记 | ICLR 2023 ReAct:通过整合推理和行动来增强语言模型
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2023 | Accept: notable-top-5%:《ReAct: Synergizing Reasoning and Acting in Language Models》 一句话总结:ReAct 方法在问答任务

ICLR 2024 高分论文 | Step-Back Prompting 使大语言模型通过抽象进行推理
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2024 高分论文:《Step-Back Prompting Enables Reasoning Via Abstraction in Large Language Models》 论文地址:https://openre

ICLR 2023|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架
©作者 | 机器之心编辑部 来源 | 机器之心 大模型时代,模型压缩和加速显得尤为重要。传统监督学习可通过稀疏神经网络实现模型压缩和加速,那么同样需要大量计算开销的强化学习任务可以基于稀疏网络进行训练吗?本文提出了一种强化学习专用稀疏训练框架,可以节省至多 95% 的训练开销。 深度强化学习模型的训练通常需要很高的计算成本,因此对深度强化学习模型进行稀疏化处理具有加快训练速度和拓展模型部署的巨