本文主要是介绍CPVT(ICLR 2023)论文解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
paper:Conditional Positional Encodings for Vision Transformers
official implementation:GitHub - Meituan-AutoML/CPVT
存在的问题
- 位置编码的局限性:传统Transformer中的绝对位置编码(无论是可学习的还是固定的)在训练时会固定编码的长度和数值,导致模型在测试时难以处理比训练序列更长的输入数据。这种限制在视觉任务中尤其明显,如目标检测任务中需要处理不同大小的图像。
- 平移等变性问题:绝对位置编码会破坏平移等变性,即在输入图像中的目标对象移动时,模型的输出特征图不相应移动。
第一个问题或许可以通过删除位置编码来解决,因为除了位置编码之外,vision Transformer 的所有其他组件(如MHSA和FFN)都可以直接应用于更长的序列。然而,这种解决方案对模型的性能造成了严重影响。因为输入序列的顺序是一个重要的线索,而过没有位置编码,模型就无法提取顺序。去除位置编码后,DeiT-tiny在ImageNet上的精度从72.2%降低到了68.2%,如表1所示。
其次,DeiT通过对位置编码进行插值使其可以用于较长的输入序列,但这种方法需要对模型进一步微调,否则性能就会显著下降,如表1所示。
最后,相对位置编码可以同时应对上述两种问题,但是相对位置编码无法提供绝对位置信息,这对分类性能非常重要,如表1所示,相对位置编码的模型性能较差(70.5% vs. 72.2%)。

本文的创新点
- 条件位置编码(Conditional Position Encoding,CPE):本文提出了一种新的位置编码方法CPE,通过卷积操作保留位置关系,使得模型在处理不同大小的输入图像时无需重新训练或进行复杂的插值,从而保持了平移等变性。
- 位置编码生成器(Position Encoding Generator,PEG):通过一个简单的PEG实现CPE,它可以无缝地集成到当前的Transformer框架中。PEG通过局部邻域的动态编码,使得模型能够处理比训练期间见过的序列更长的输入序列。
- 全局平均池化(GAP):在分类任务中,提出用全局平均池化替代传统的可学习分类标记(class token),进一步增强了模型的平移等变性和性能。
- Conditional Position encoding Vision Transformer(CPVT):基于PEG构建的CPVT,在保持与学习到的位置编码相似的注意力图的同时,提供了更好的性能和泛化能力。
方法介绍
作者认为,一个成功的视觉任务的位置编码应该满足以下的要求:
- 使得输入序列对顺序敏感(permutation-variant)同时又具备平移不变性(translation-equivariance)。
- 能够处理比训练时更长的输入序列,有助于泛化到检测、分割等下游任务。
- 在一定程度上能够提供绝对位置,这对分类性能很重要。
作者发现,用位置编码描述局部关系就足以满足上述所有条件。首先,它满足permutation-variant,因为输入序列的排列顺序也会影响局部邻域的顺序。但对输入图像中的对象进行平移并不会改变其局部邻域的顺序,即translation-equivariance。其次,模型可以很容易地泛化到较长的输入序列,因为只涉及到一个token的局部邻域。此外,如果任何一个输入token的绝对位置都已知,则可以通过输入token之间的相互关系来推断出其它token的绝对位置。作者表明,由于zero-padding,边界上的token也可以知道它们的绝对位置。
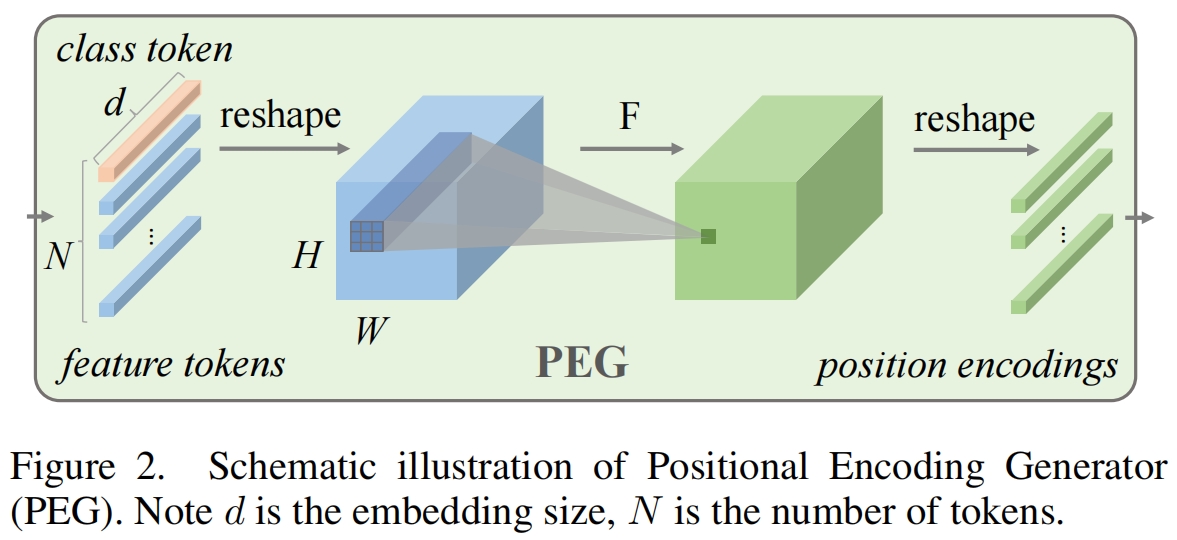
因此作者提出了位置编码生成器(PEG)来动态地生成基于输入token的局部邻域的位置编码。PEG如图2所示,我们首先将DeiT中展平后的输入序列 \(X\in \mathbb{R}^{B\times N\times C}\) reshape回二维图片空间中得到 \(X'\in \mathbb{R}^{B\times H\times W\times C}\),然后将一个函数(如图2中的 \(F\))重复地作用于 \(X'\) 中的local patch来得到conditional位置编码 \(E\in \mathbb{R}^{B\times H\times W\times C}\)。PEG可以通过一个核大小为 \(k(k\ge3)\) 以及 \(\frac{k-1}{2}\) 的zero padding的二维卷积来实现,而 \(F\) 可以是各种形式比如各种类型的卷积。

基于条件位置编码,作者提出了条件位置编码Vision Transformer(CPVT),除了位置编码,作者完全遵循ViT和DeiT来设计CPVT,并有三种不同尺寸的模型CPVT-Ti、CPVT-S和CPVT-B。和DeiT中原始的位置编码类似,条件位置编码也被添加到输入序列之中,如图1(b)所示。在CPVT中,PEG的位置对模型的性能也很重要,具体将在实验部分进行研究。
此外,DeiT和ViT都使用了一个额外的可学习的类别token来执行分类,即图1(a)和(b)中的cls_token。类别token本身的设计不是平移不变的,尽管它可以学习这种特性。一个简单的替代方法是直接使用全局平均池化(GAP),它本质上是平移不变的,从而得到了CPVT-GAP。结合CPE和CPVT-GAP得到了更好的分类性能。
实验结果
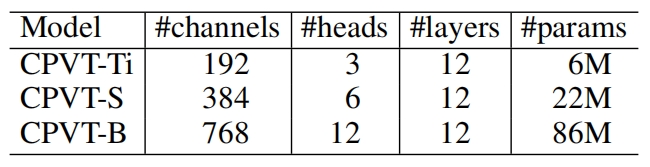
不同大小的CPVT的结构如下表所示
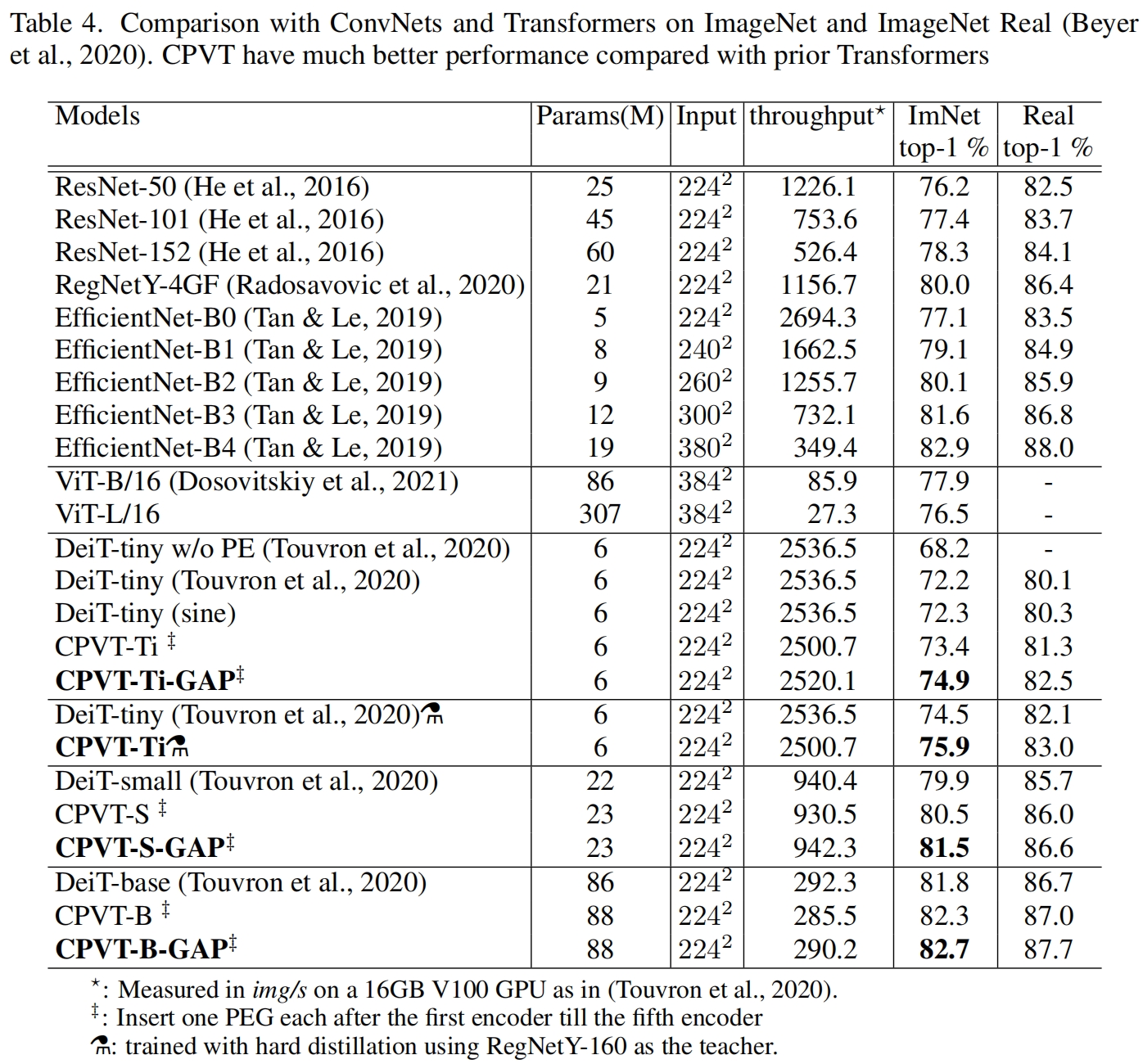
和其它SOTA模型在ImageNet上的性能对比,如表4所示,可以看到在相似的参数量和计算量区间范围内,CPVT的性能要优于DeiT。
消融实验
Class Token vs. GAP
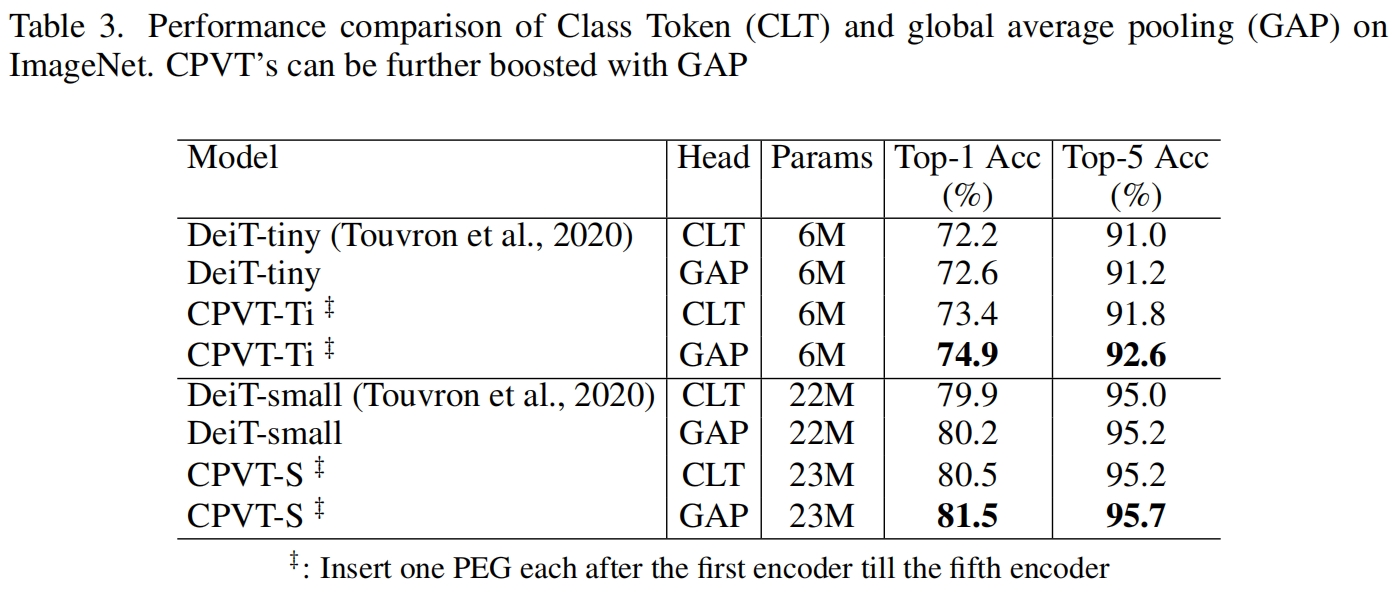
本文提出的PEG忽略padding时是平移等变的,因此如果我们进一步使用具有平移不变性的GAP而不是cls_token,CVPT也具有了平移不变性。这对分类任务是有帮助的。实验结果如表3所示,使用GAP可以将CPVT的精度提升超过1%。
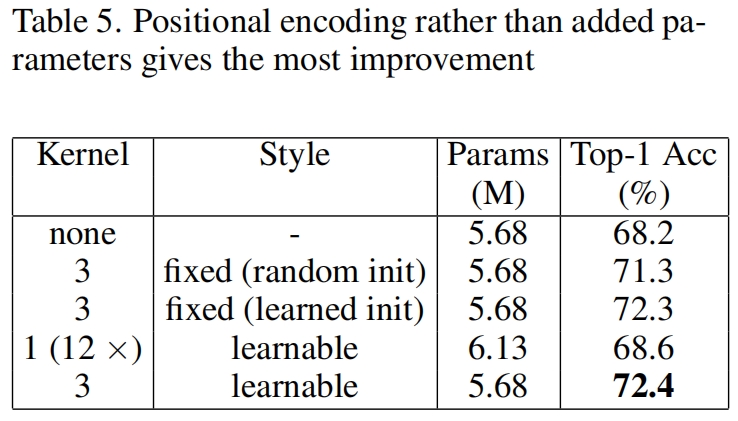
位置信息还是额外的参数?
有人可能会怀疑PEG带来的改进是由于PEG中的卷积层带来的额外的可学习参数,而不是它的位置表示能力。作者将PEG中3x3卷积的权重随机初始化后在训练阶段固定住,即不更新权重,仍然取得了71.3%的精度,由于不用位置编码的DeiT的68.2%,表明是通过zero padding引入的位置信息提升了性能而不是额外的参数。此外作者又用12层的1x1卷积替换PEG,此时可学习的参数更多了但没有引入位置信息,精度只有68.6%。
PEG的位置
作者又比较了将PEG放到不同位置时模型的性能,其中-1表示第一个encoder block的输入位置,0表示第一个encoder block的输出位置,作者认为两者性能差异这么大的原因在于感受野不同,经过第一个block后具有了全局感受野,如果在-1位置处增大感受野性能也会得到提升。为此作者将-1位置处的3x3卷积改成27x27的卷积,结果确实得到了提升,从而验证了作者的观点。

这篇关于CPVT(ICLR 2023)论文解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







