本文主要是介绍Sample Pairing(ICLR 2018),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
paper:Data Augmentation by Pairing Samples for Images Classification
本文的创新点
本文提出了一种新的应用于图像分类的数据增强方法SamplePairing,这种简单的数据增强技术显著提高了所有测试的数据集的分类精度。此外当训练集中的样本数量非常少时,SamplePairing技术很大程度的提高了精度,因此该方法对于训练数据非常有限的任务更有价值,比如医学图像任务。
方法介绍
本文的方法很简单,从训练集中随机抽取两张图片合成一张新的图片,合成方法也很简单,同一位置取像素的平均值。

图1是样本配对的整体过程,每个训练epoch,所有的样本随机顺序输入网络进行训练,我们从训练集随机挑选另一张图片(图1中的image B),两张图片取平均得到的混合图片与第一张图片的标签一起送入网络进行训练。
本文的方法和Between-class learning和mixup的区别在于:
- 本文的方法只对图片进行混合,而不对标签进行融合。
- 它们使用加权平均(权重的随机选择的)来混合两个样本,而本文是直接两张图片取平均,即权重相等。
完整的训练过程如下:
- 开始训练时不使用SamplePairing,但使用其它基本的数据增强方法如随机翻转和随机剪切。
- 在1个epoch(对于ILSVRC)或100个epoch(对于其它数据集)后,开启SamplePairing数据增强。
- 在这一阶段,间歇性的禁用SamplePairing。对于ILSVRC数据集,对30万张图片开启SamplePairing,然后对接下来的10万张图片禁用。对于其它数据集,开启8个epoch,接下来2个epoch禁用。
- 在训练损失和精度稳定后,关闭SamplePairing开始fine-tune阶段。
实验结果
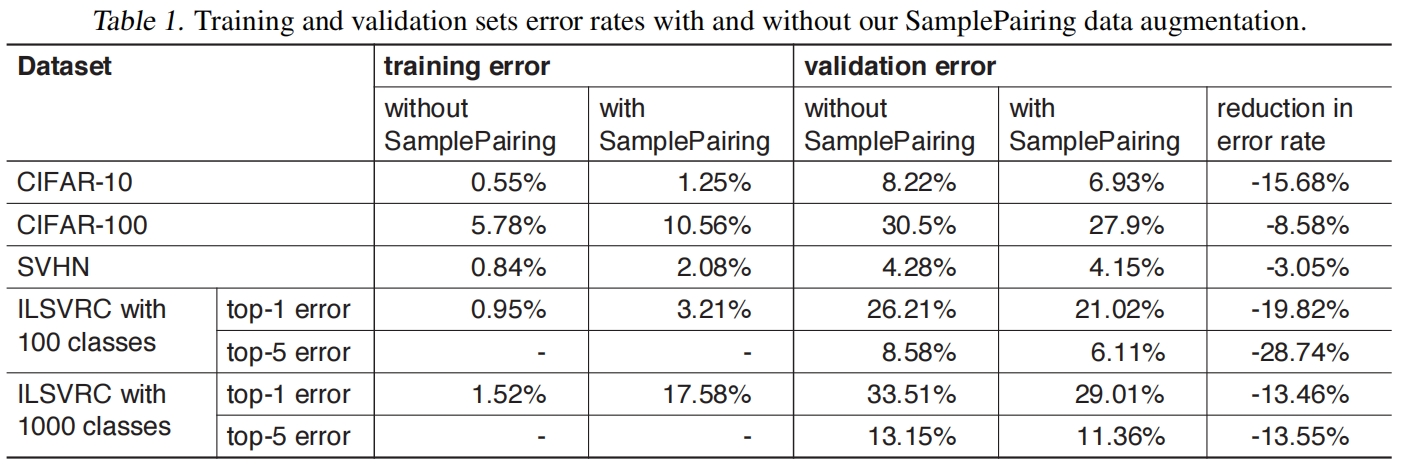
如表1所示,在实验的所有数据集上,使用SamplePairing都导致训练误差不同程度的增加,但验证误差也都有不同程度的减小,这表明SamplePairing可以有效减小过拟合,增加模型的泛化性能。
这篇关于Sample Pairing(ICLR 2018)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)




![解决树莓派IOError: [Errno Invalid sample rate] -9997 采样率16K错误](/front/images/it_default.gif)
