本文主要是介绍【微软】【ICLR 2022】TAPEX:通过学习神经 SQL 执行器进行表预训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
重磅推荐专栏: 《大模型AIGC》;《课程大纲》
本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展
论文:https://arxiv.org/abs/2107.07653
代码:https://github.com/microsoft/Table-Pretraining
通过利用大规模非结构化文本数据,语言模型的研究取得了巨大的成功。然而,由于缺乏大规模、高质量的表格数据,对结构化表格数据进行预训练仍然是一个挑战。在本文中,作者提出TAPEX来证明表预训练可以通过在合成语料库上学习神经SQL执行器来实现,这是通过自动合成可执行的SQL查询及其执行输出来获得的。TAPEX通过指导语言模型在多样化、大规模和高质量的合成语料库上模拟SQL执行器,从而解决了数据稀缺性的挑战。作者在四个基准数据集上评估了TAPEX。实验结果表明,TAPEX比以前的表前训练方法有很大的优势,并且都取得了新的最先进的结果。
1. 概述
在本文中,作者提出了一种新的以执行查询为核心的表格预训练方法——TAPEX(TAble Pretraining via EXecution)。通过逼近表上的正式语言的结构推理过程,实现了高效的表预训练。结构性推理过程与表的可执行性相关联,即表本身就能够支持各种推理操作(例如,对表中的一列进行求和)。特别是,TAPEX通过对语言模型(LM)进行预训练来模拟表上的SQL执行引擎的行为,来近似SQL查询的结构性推理过程。
![图1-1:我们的方法的示意图概述。为了简洁起见,输入中的表内容被简化为符号为[Table]](https://img-blog.csdnimg.cn/5fd715de5eae40ac8f5a8e4c29e58d52.png)
如图1-1所示,通过对表进行采样可执行的SQL查询,TAPEX首先合成了一个大规模的训练前语料库。然后,它继续预训练一个语言模型,以输出这些SQL查询的执行结果,这些查询从SQL执行引擎获得。 由于SQL查询的多样性,可以很容易地合成一个多样化、大规模、高质量的训练前语料库。
2. 对下游任务的微调
模型整体是一个BART结构。如图2-1所示,输入包含一个NL句子及其相应的表。
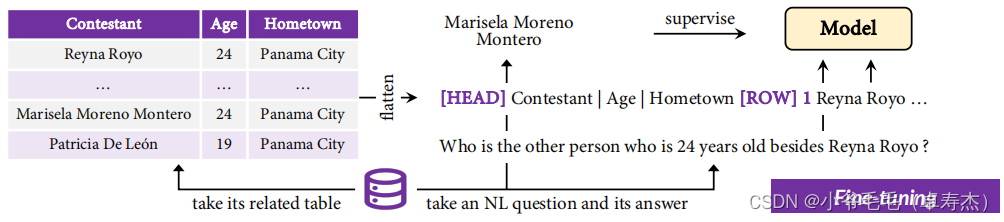
编码NL句子相对简单,而编码表并不简单,因为它展示了底层结构。在实践中,作者将表压平成一个序列,以便将它可以直接输入到模型中。通过插入几个特殊的标记来表示表的边界,可以将一个扁平的表格表示为:
T ∗ = [ H E A D ] , c 1 , ⋅ ⋅ ⋅ , c N , [ R O W ] , 1 , r 1 , [ R O W ] , 2 , r 2 , ⋅ ⋅ ⋅ , r M T^∗ = [HEAD], c_1, · · ·, c_N , [ROW], 1, r_1, [ROW], 2, r_2, · · ·, r_M T∗=[HEAD],c1,⋅⋅⋅,cN,[ROW],1,r1,[ROW],2,r2,⋅⋅⋅,rM
这里[HEAD]和[ROW]是特殊标记,分别表示表头和行的区域,[ROW]之后的数字用于表示行索引。注意:作者还使用“竖条|”在不同的列中分离标题或单元格。最后,作者在扁平表 T ∗ T^∗ T∗拼接上NL句子x作为前缀,并将它们输入模型编码器。
3. 通过执行器进行表格预训练
为了设计表的预训练的有效任务,作者认为关键在于表的可执行性。也就是说,结构化表使我们能够通过诸如SQL查询等编程语言对它们执行离散操作,而非结构化文本则不能。考虑到这一点,TAPEX采用SQL执行作为唯一的训练前任务。如图3-1所示,TAPEX的预训练与上述生成式微调的过程相似。
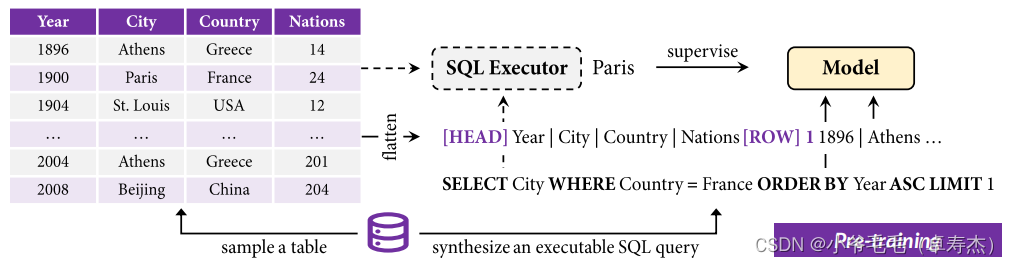
给定一个可执行的SQL查询和一个表T,TAPEX首先将SQL query 和打平的表 T ∗ T^∗ T∗连接起来,以馈入模型编码器。然后,它通过一个现成的SQL执行器(例如,MySQL)获得查询的执行结果,作为模型解码器的监督。直观地说,预训练过程是为了让一个语言模型成为一个神经SQL执行器。作者认为,如果一个语言模型可以预先训练,可靠地“执行”SQL查询并产生正确的结果,它应该对表有深入的理解。因此,执行预训练任务可以更有效地理解表和推理表。
4. 实践
你可以在 🤗 Transformers 中尝试经过训练的神经 SQL 执行器,如下所示:
from transformers import TapexTokenizer, BartForConditionalGeneration
import pandas as pdtokenizer = TapexTokenizer.from_pretrained("microsoft/tapex-large-sql-execution")
model = BartForConditionalGeneration.from_pretrained("microsoft/tapex-large-sql-execution")data = {"year": [1896, 1900, 1904, 2004, 2008, 2012],"city": ["athens", "paris", "st. louis", "athens", "beijing", "london"]
}
table = pd.DataFrame.from_dict(data)# tapex accepts uncased input since it is pre-trained on the uncased corpus
query = "select year where city = beijing"
encoding = tokenizer(table=table, query=query, return_tensors="pt")outputs = model.generate(**encoding)print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
# ['2008']5. 实验与分析
5.1 实验结果
作者在四个基准数据集上评估( TAPEX,包括WikiSQL(Weak)、WikiTableQuestions、SQA和TabFact)。
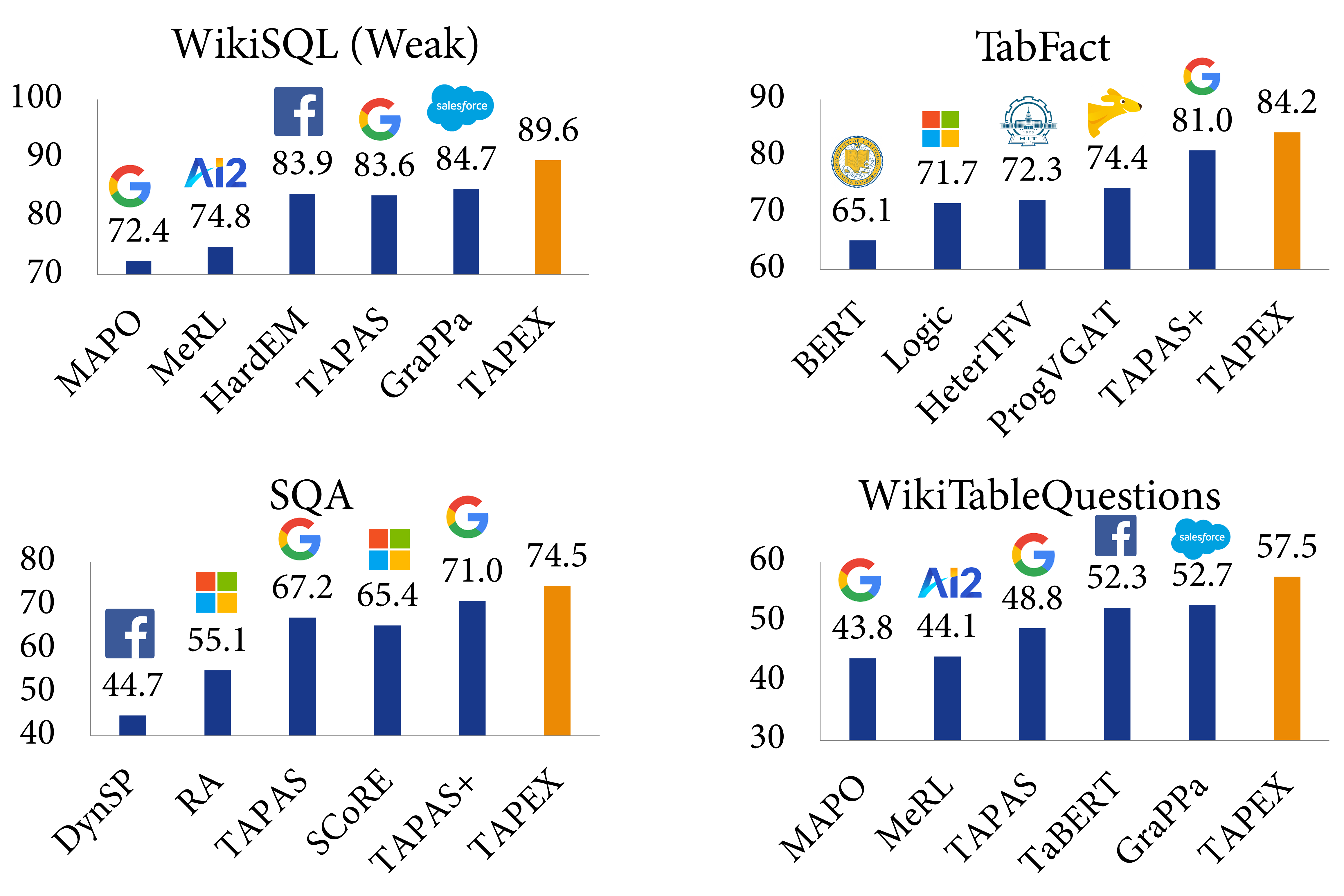
如图5-1的实验结果表明,TAPEX 大大优于以前的表格预训练方法,并且在所有这些方法上都取得了SOTA结果。
5.2 与以前的表预训练对比
表预训练的最早工作(Google Research 的 TAPAS 和Meta AI 的TaBERT)表明,收集更多领域自适应(domain-adaptive)数据可以提高下游性能。然而,这些以前的工作主要采用通用(general-purpose)的预训练任务,例如语言建模或其变体。TAPEX探索了一条不同的路径,通过牺牲预训练的自然性来获得领域自适应的预训练任务,即SQL执行。BERT、TAPAS/TaBERT 和 TAPEX 的比较如下图5-2所示:

作者认为 SQL 执行任务更接近于下游的表问答任务,尤其是从结构推理能力的角度来看。假设你面临一个 SQL 查询 SELECT City ORDER BY Year 和一个自然问题Sort all cities by year。SQL查询和问题所需的推理路径类似,只是SQL比自然语言更死板一些。如果一个语言模型可以被预训练以可靠地“执行”SQL 查询并产生正确的结果,它应该对具有类似意图的自然语言有深刻的理解。
效率怎么样?这样的预训练方式和之前的预训练相比效率如何?下图5-3给出了答案:
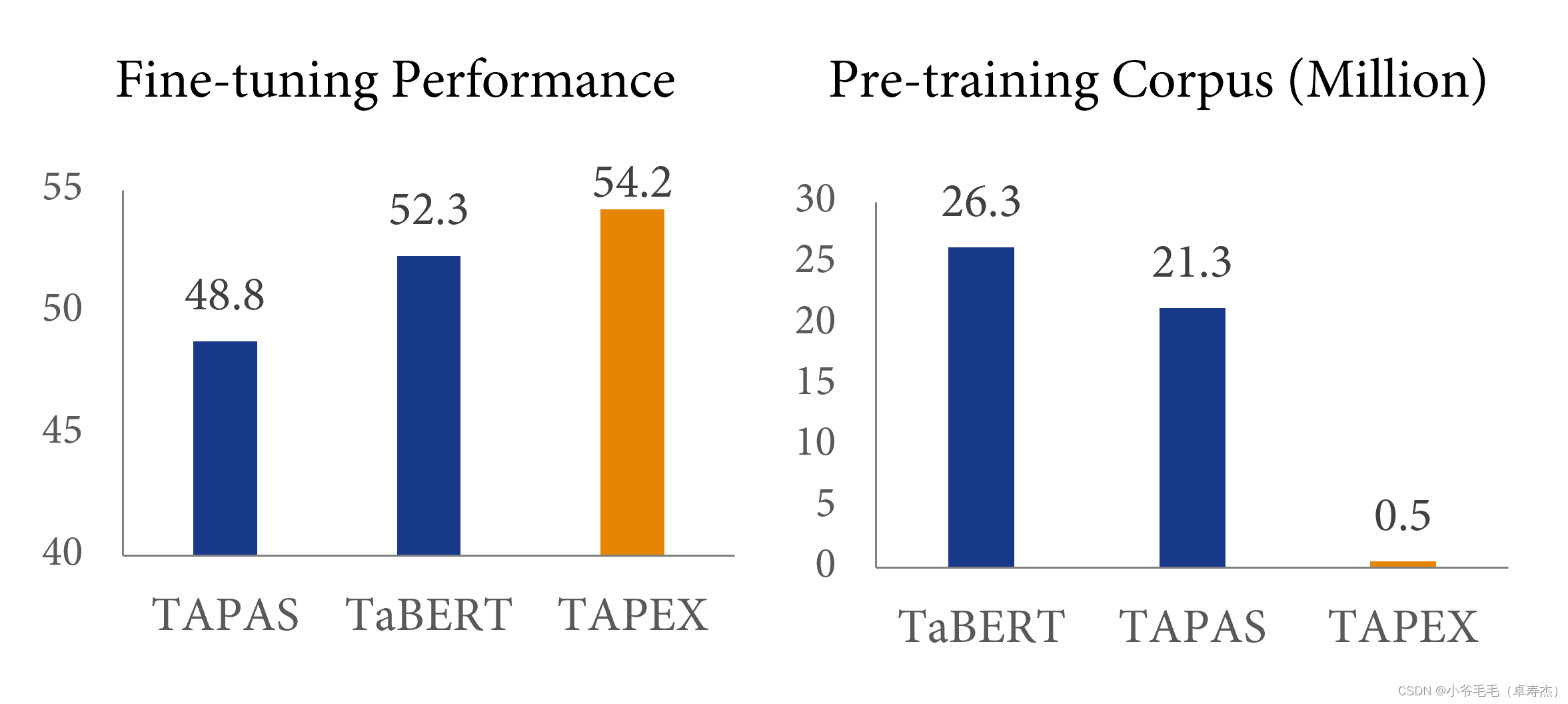
与之前的表格预训练方法TaBERT相比,TAPEX仅使用2%的预训练语料就可以得到2%的提升,实现了近50倍的加速!使用更大的预训练语料库(例如,500 万个<SQL, Table, Execution Result> 对),在下游数据集上的性能会更好。
5.3 通过预训练的SQL执行器
为了了解TAPEX在预训练后SQL执行效果如何,作者分析了它在未见过表上近20,000个SQL查询上的表现。总的来说,SQL的执行精度相对较高。如图5-4所示,,TAPEX正确地“执行”了89.6%的SQL Select操作查询:
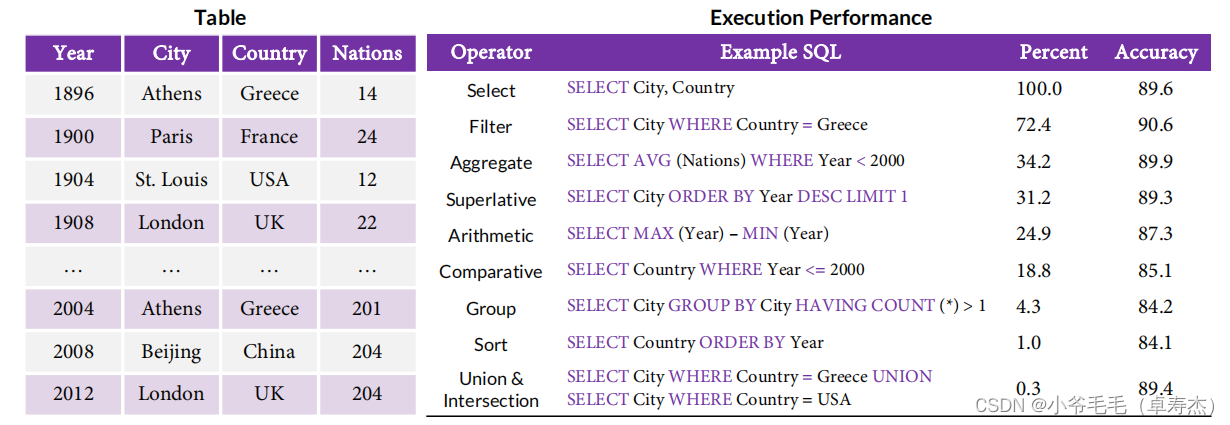
特别是,TAPEX在过 Filter, Aggregate 和 Superlative 操作符上表现得更好,这表明它在表单元格选择和表聚合方面具有很高的准确性。对于Arithmetic 和 Comparative操作,TAPEX也做得很好,展示了它在表上的数值推理能力。综上所述,TAPEX已经学会了成为一个具有良好的选择、聚合和数值能力的神经SQL执行器
5.4 通过预训练对表的理解
为了深入了解TAPEX是否有助于下游任务更好地理解表,作者在采样的WIKITABLE QUESTIONS 样本上可视化和分析了TAPEX的自我注意(没有微调)。如图5-4所示,TAPEX似乎更关注单元格对应的行和头。

以图5-5为例,注意权重意味着“adrian lewis”与第一列“player”和整个第三行密切相关,这是“adrian lewis”在结构化表中的位置。
5.5 通过预训练对表的推理
为了了解TAPEX是否可以改进表推理,作者比较了TAPEX和BART在500个随机选择的问题上的性能,并在图5-6中手动分析了它们:
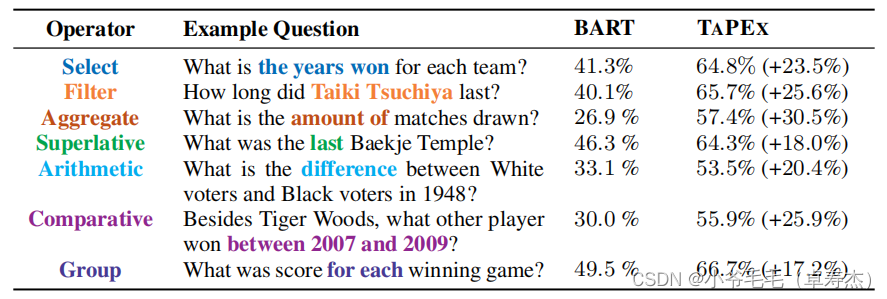
可以发现,TAPEX显著提高了所有操作符的性能,这意味着它确实增强了BART对文本和表的联合推理能力。
5.5 局限性
该方法的第一个限制是,它不能理想地处理大型表。如上所述,使用表的扁平化技术来表示一个表。当表相对较小时,它工作得很好,但当表太大而无法容纳内存时,它就变得不可行了。在实践中,可以通过删除一些不相关的行或列来压缩表,但这将降低下游任务的表现。
第二个限制是,NLP2SQL的任务不能从该表预训练中获益。作者尝试将TAPEX应用于一个NLP2SQL的任务,其中输入保持不变,输出转换为SQL。然而,TAPEX并没有显示出比BART相比的显著优势。作者将此归因于两个因素:
- 首先,预训练的合成语料库对其没有贡献,这是语义解析最重要的因素之一;
- 其次,TAPEX学习到的表推理能力(例如,聚合)可能不是SQL生成所必需的。例如,一个模型仍然可以将NL短语“sum”理解为聚合函数“sum”,即使它不知道“sum”的数学含义。
这篇关于【微软】【ICLR 2022】TAPEX:通过学习神经 SQL 执行器进行表预训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





