本文主要是介绍ICLR 2024|ReLU激活函数的反击,稀疏性仍然是提升LLM效率的利器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文题目: ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
论文链接: https://arxiv.org/abs/2310.04564
参数规模超过十亿(1B)的大型语言模型(LLM)已经彻底改变了现阶段人工智能领域的研究风向。越来越多的工业和学术研究者开始研究LLM领域中的难题,例如如何降低LLM在推理过程中的计算需求。
本文介绍一篇苹果发表在人工智能顶会ICLR 2024上的文章,本文针对LLM中激活函数对LLM推理效率的影响展开了研究,目前LLM社区中通常使用GELU和SiLU来作为替代激活函数,它们在某些情况下可以提高LLM的预测准确率。但从节省模型计算量的角度考虑,本文作者认为,经典的ReLU函数对模型收敛和性能的影响可以忽略不计,同时可以显着减少计算和权重IO量。因此作者主张在LLM社区重新评估ReLU的地位(尽可能多的使用ReLU)。
此外,作者还探索了一种基于ReLU的LLM稀疏模式,该模式可以对已激活的神经元进行重新利用来生成出新的高效token。综合这些发现和设计,本文实现了基于ReLU的高效LLM计算方案,相比其他激活函数,将LLM的推理计算量大幅减少三倍。
01. 引言
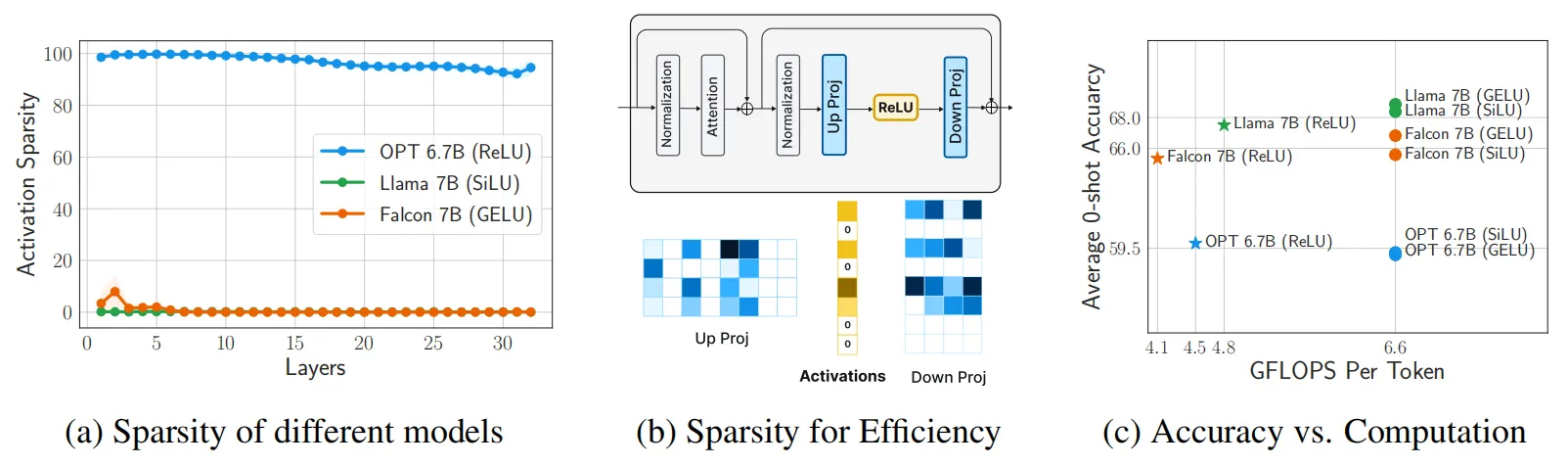
为了提高LLM的推理效率,研究者们提出了包括量化、推测解码、剪枝和权重稀疏化等多种加速手段。通过引入激活函数的稀疏性可以在LLM的精度和计算量之间实现非常可观的效率平衡,尤其是在GPU等现代硬件上。在传统神经网络中经常使用的ReLU激活函数被认为可以有效诱导模型进行稀疏激活,来提高网络的推理效率。本文作者对OPT模型(激活函数使用ReLU)中每层神经元的激活稀疏度进行了测量,如下图(a)所示,所有层的稀疏度均超过90%,这种稀疏度可以在模型训练时GPU 和 CPU 之间的权重IO节省大量时间。对于 OPT 模型,这种稀疏性将推理所需的计算量从每个token的 6.6G FLOPS 减少到 4.5G FLOPS,从而节省了 32% 的计算量(如下图c所示)。

02. 激活函数对模型综合性能的影响


上图第二行显示了LLM在使用不同激活函数时的性能指标曲线。可以看出,当使用不同的激活函数时,模型的性能非常相似。这一现象与LLM缩放定律[2]给出的结论一致,即LLM的性能很大程度上取决于计算和数据,而不是架构细节。但是不同激活函数带来的激活稀疏性水平明显不同。上图c反映了模型中所有层的平均稀疏度级别,当激活函数从SiLU过渡到ReLU(增加了门控权重 )时,模型的稀疏性也在增加。
03. ReLU充当预训练LLM的润滑剂
通过上一节的实验作者已经发现,LLM的预测准确率并不依赖于激活函数的类型。但是现有大多数LLM均是使用ReLU之外的激活函数进行训练,因此为了在推理阶段使这些LLM结合ReLU激活的计算优势,作者进行了各种架构改进实验。例如将ReLU合并到预训练LLM中,作者将这一过程称为对LLM的“再润滑”(ReLUfication)。将ReLU插入到预训练LLM中,模型在微调过程中可能快速的恢复性能,同时提高推理时的稀疏性,可谓是一举两得。
3.1 一阶段插入ReLU激活
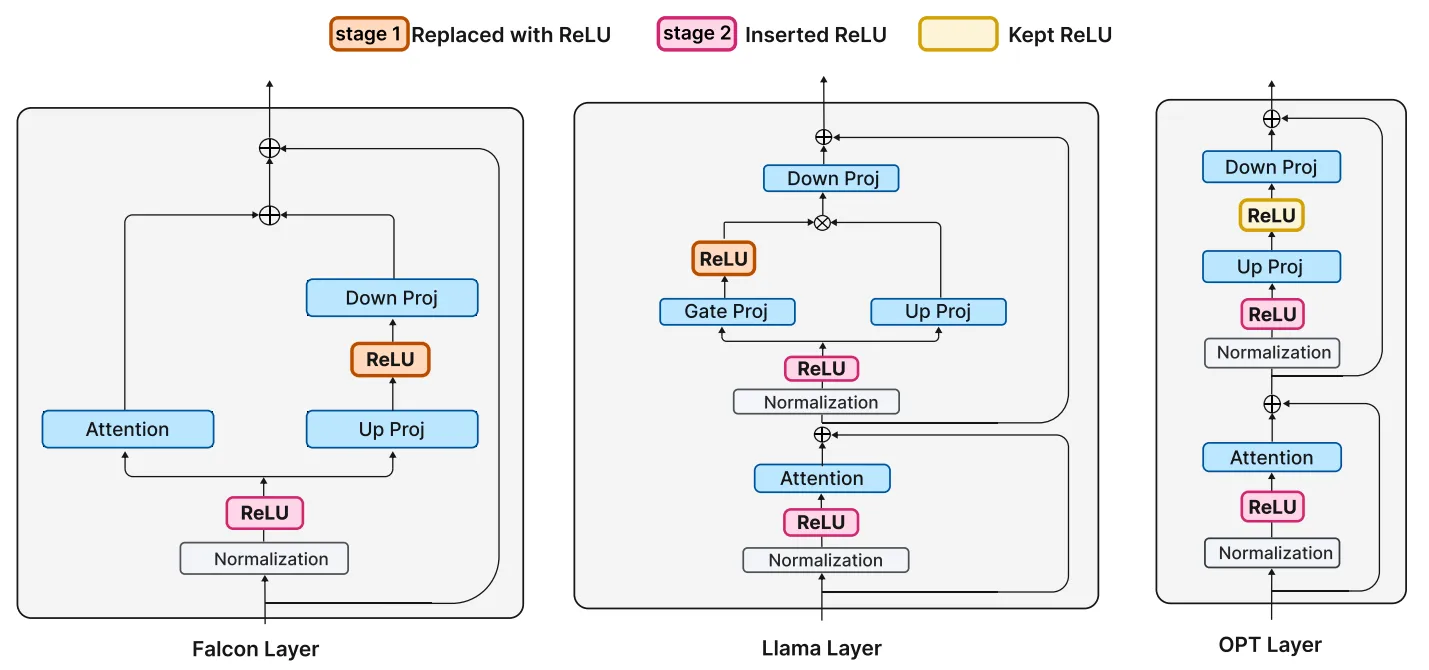
ReLUfication过程的示意图如下图所示,这个过程可以分为多个阶段完成,一阶段是使用ReLU替换到LLM中的其他激活函数,例如在Falcon 和 Llama分别替换 GELU 和 SiLU。由于 OPT 模型已经使用 ReLU 激活,因此这里保持不变。
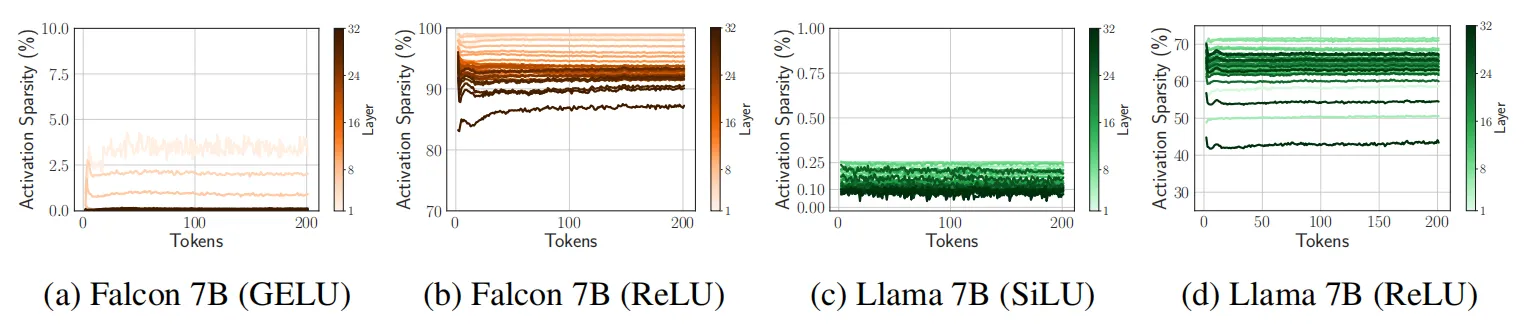
随后作者将替换ReLU后的模型在RefinedWeb数据集上进行微调,下图分别展示了Falcon 和 Llama在替换后模型稀疏性的对比效果。
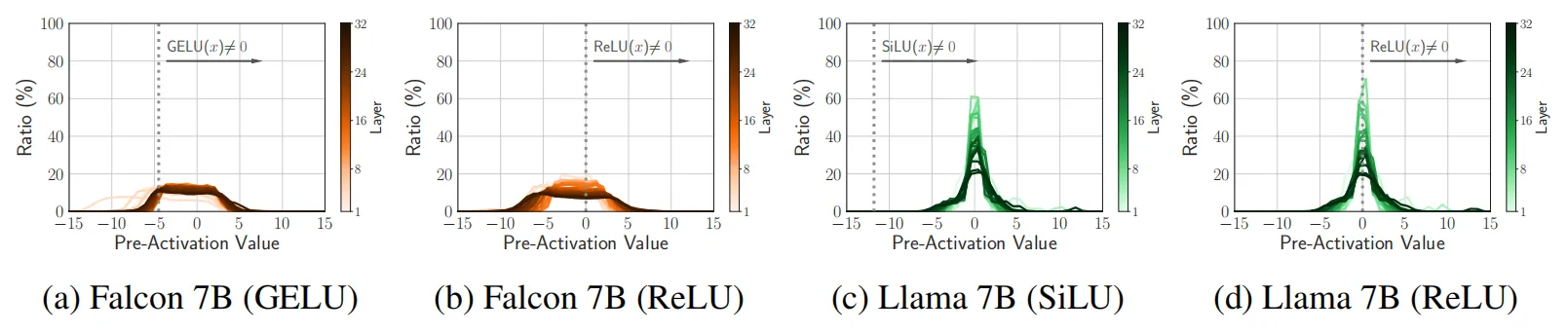
除了激活稀疏性的显着改善之外,作者还观察到了其他有趣的现象,如下图所示,作者测量了Falcon 和 Llama 预训练模型的预激活分布情况,可以看出,在微调阶段,这个分布本身的变化并不明显,这可能表明网络的预测倾向在引入稀疏性时并不会改变,具有良好的稳定性。
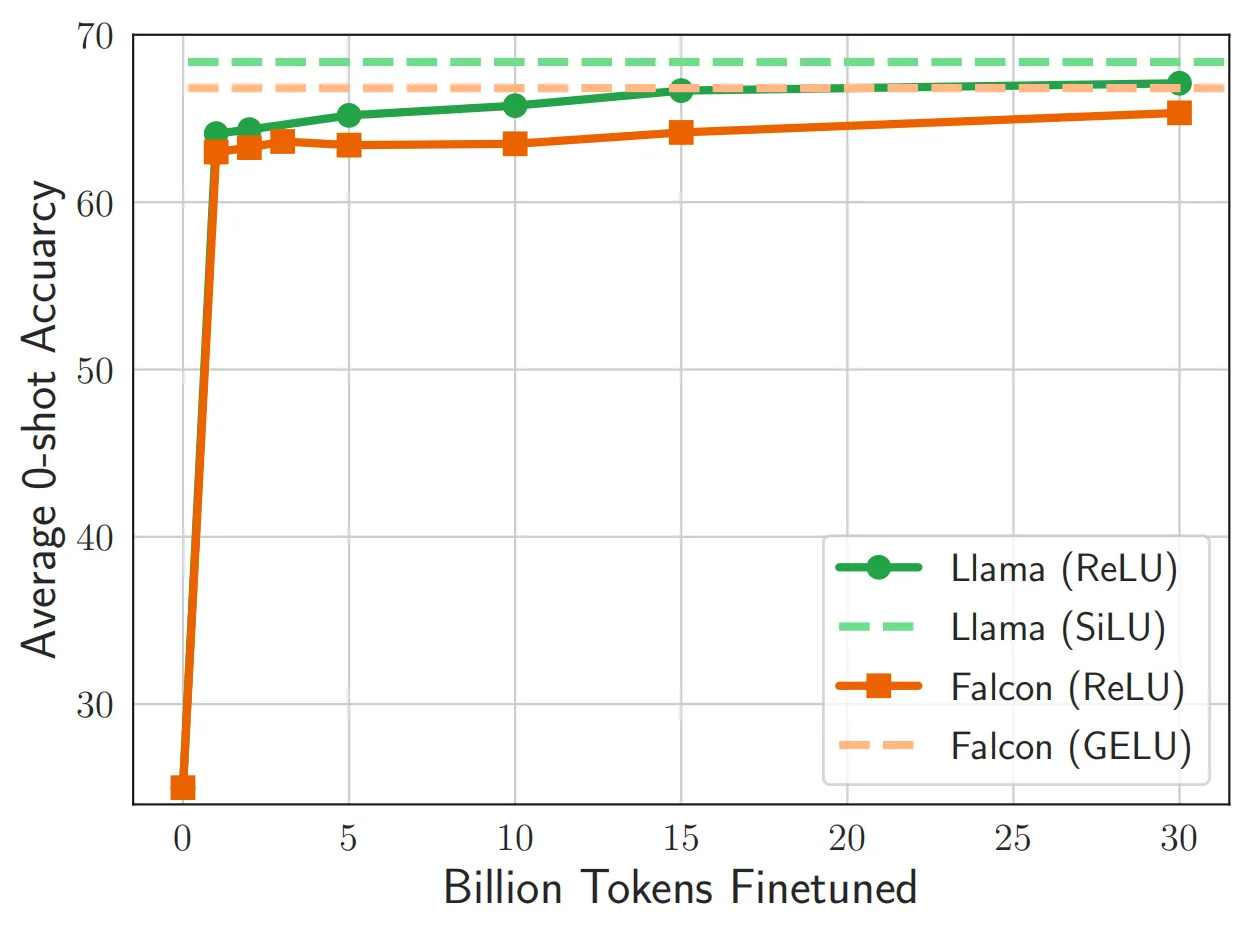
下图展示了模型的预测准确率随着ReLU的不断微调的变化情况,模型在微调阶段很快恢复了其原本的性能,其中Llama(绿色线条)完美的达到了ReLU插入之前的预测准确率。
3.2 二阶段的进一步稀疏化
在一阶段的ReLU融化中,作者插入了ReLU来替代其他激活函数,这会导致模型down projection层的输入变稀疏,稀疏程度大约占总计算量的30%。然而,除了down projection层之外,transformer的解码器层中还有其他复杂的矩阵向量乘法,例如注意力层中的QKV projection,这些矩阵向量乘法大约占总计算量的约 55%,因此对这一部分进行二次稀疏也非常重要。作者发现,在现代transformer层中,注意力层和 FFN 层的输入都来自归一化层(LayerNorm),这些层可以被视为 MLP 的一种特定形式,因为它们并不是学习参数,而是学习如何对输入数据进行缩放,因此作者将ReLU接在归一化层之后来进行二阶段的稀疏激活。
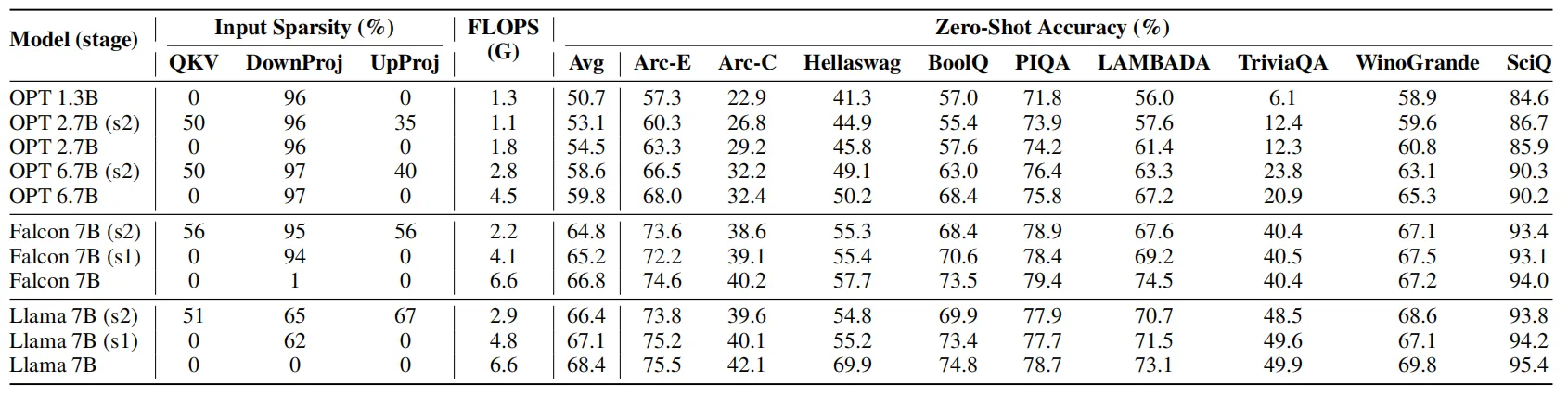
下表展示了ReLUfication调整后,模型的稀疏程度和zero-shot预测精度。其中模型的稀疏性可以分为三种类型:up projection、down projection和QKV projection。可以看到,对LLM的不同部位进行稀疏化后,模型的zero-shot精度变化并不明显,但是计算量的差异很大。
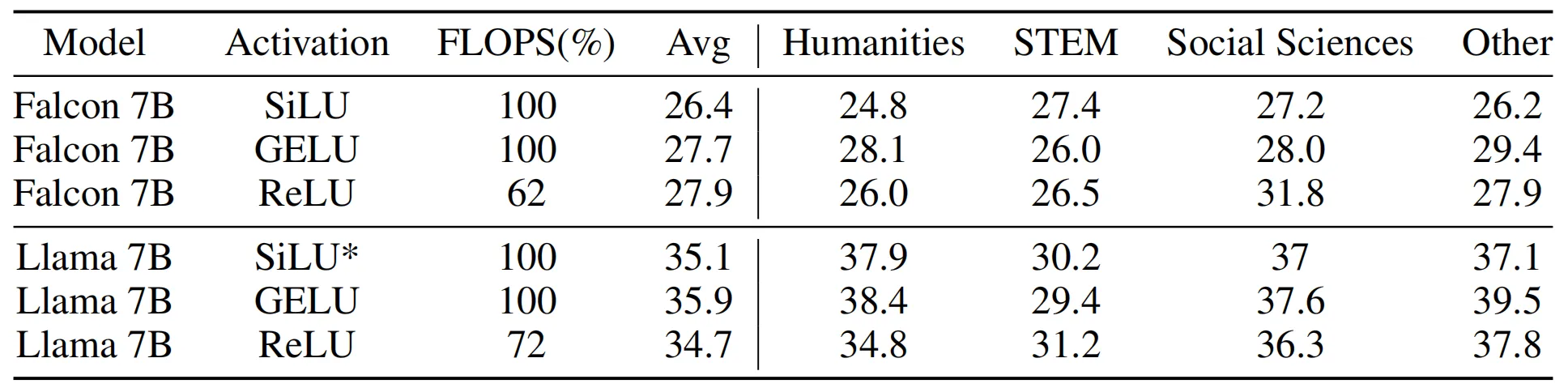
为了综合评估激活函数对LLM上下文学习能力的影响,作者在下表展示了模型在大规模多任务语言理解(MMLU)任务中的性能,结果表明,当使用不同的激活函数和微调策略来增强原始 LLM 时,模型的zero-shot性能也不会发生显着变化。此外,在相同的FLOPS情况下,参数规模较大但经过ReLU简化后的模型相比原始较小模型的性能更好。总体而言,本文提出的ReLUfication可以降低LLM各个阶段的推理FLOPS,同时保持各种任务的同等性能。
04. 聚合稀疏性:重用已激活的神经元

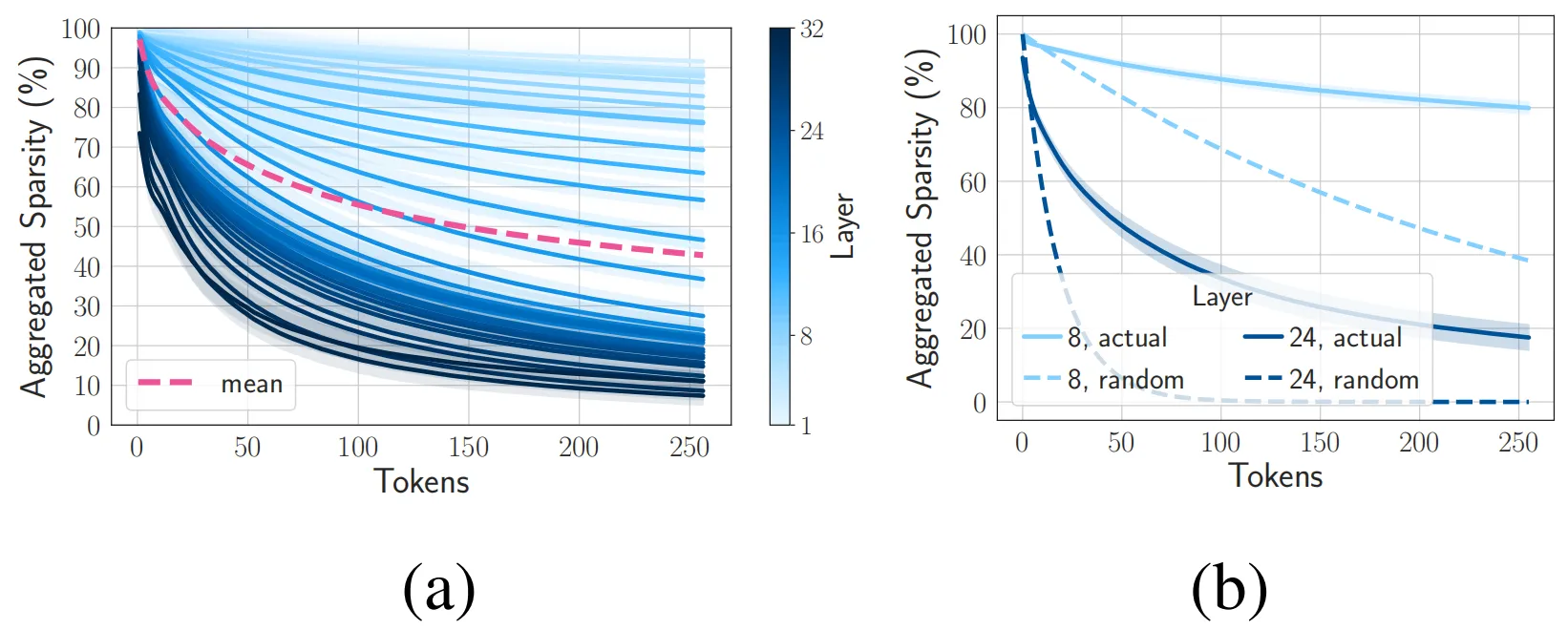

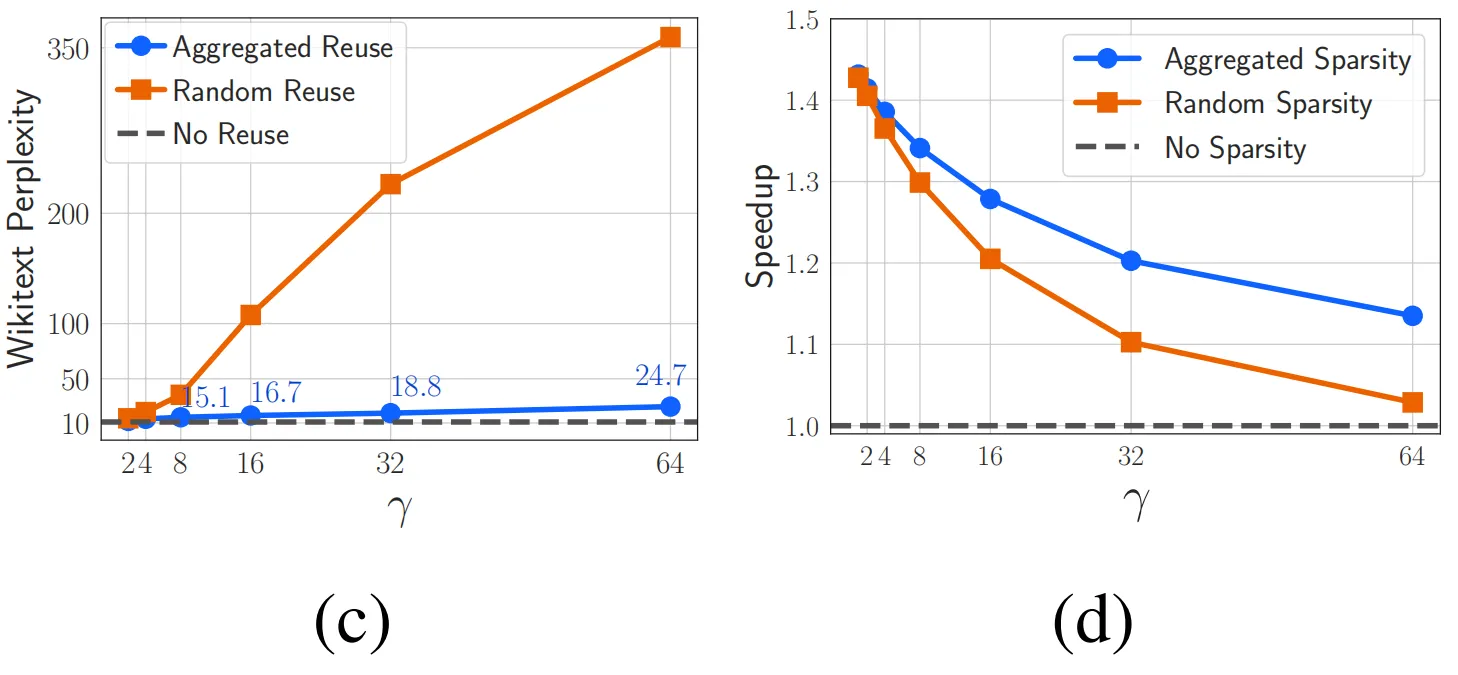
可以看出,重用激活方式对模型带来的困惑负面影响几乎可以忽略不记,其曲线与基线方法基本吻合,同时在推理加速方面也远远优于随机稀疏性。
05. 总结
本文对LLM中使用的激活函数进行了大规模的研究,作者发现,在LLM预训练和微调期间激活函数的选择不会对性能产生显着影响,而使用经典的 ReLU 可以为LLM提供稀疏性和更高效的推理效率。考虑到现有流行的LLM(例如Llama和Falcon)均已使用非ReLU激活函数进行预训练,从头对它们进行训练耗费的代价太大,因而作者提出了一种将ReLU激活函数合并到现有预训练LLM中的方法,被称为ReLUfication,ReLUfication具有即插即用的特点,可以在微调阶段快速将模型恢复到与原有状态相当的性能,同时带来显著的推理效率增益。作者在广泛的基准实验(包括zero-shot预测和上下文理解)上证明,在LLM中使用稀疏性激活函数具有强大的潜力。
参考
[1] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
[2] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffre Wu, and Dario Amodei. Scaling laws for neural language models. CoRR, abs/2001.08361, 2020.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区
这篇关于ICLR 2024|ReLU激活函数的反击,稀疏性仍然是提升LLM效率的利器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





