relu专题

深度学习-激活函数:饱和激活函数【Sigmoid、tanh】、非饱和激活函数【ReLU、Leaky ReLU、RReLU、PReLU、ELU、Maxout】
深度学习-激活函数:饱和激活函数【Sigmoid、tanh】、非饱和激活函数【ReLU、Leaky ReLU、RReLU、PReLU、ELU、Maxout】 一、激活函数的定义:二、激活函数的用途1、无激活函数的神经网络2、带激活函数的神经网络 三、饱和激活函数与非饱和激活函数1、饱和激活函数2、非饱和激活函数 四、激活函数的种类1、Sigmoid函数2、TanH函数3、ReLU(Recti

Caffe Prototxt 激活层系列:ReLU Layer
ReLU Layer 是DL中非线性激活的一种,常常在卷积、归一化层后面(当然这也不是一定的) 首先我们先看一下 ReLUParameter // Message that stores parameters used by ReLULayermessage ReLUParameter {// Allow non-zero slope for negative inputs to speed

ReLU Sigmoid and Tanh(2)
Sigmoid 它能够把输入的连续实值“压缩”到0和1之间。如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1. 缺点: 当输入非常大或者非常小的时候,这些神经元的梯度是接近于0的,从图中可以看出梯度的趋势。所以,需要尤其注意参数的初始值来尽量避免saturation的情况。如果你的初始值很大的话,大部分神经元可能都会处在saturation的状态而把gradientkill

ReLU Sigmoid and Tanh
ReLU 激活函数: ReLu使得网络可以自行引入稀疏性,在没做预训练情况下,以ReLu为激活的网络性能优于其它激活函数。 数学表达式: y=max(0,x) Sigmoid 激活函数: sigmoid 激活函数在神经网络学习方面,可以将重点特征推向中央区,将非重点特征推向两侧区。 数学表达式(正切函数): y=(1+exp(−x))−1 导数:f(z)' = f(z)(1

(2024,基于熵的激活函数动态优化,具有边界条件的最差激活函数,修正正则化 ReLU)寻找更优激活函数
A Method on Searching Better Activation Functions 公众号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0. 摘要 3. 动机 4. 方法论 4.1 问题设定 4.1.1 贝叶斯错误率和信息熵 4.1.2 激活函数和信息熵 4.2 具有边界条件的最差激活函数 (WAFBC)

【激活函数--下】非线性函数与ReLU函数
文章目录 一、非线性函数在神经网络中的重要性二、ReLU函数介绍及其实现2.1 ReLU函数概述2.2 ReLU函数的Python实现及可视化 一、非线性函数在神经网络中的重要性 在神经网络中,激活函数的选择对于网络的性能和能力至关重要。阶跃函数和Sigmoid函数除了是激活函数的具体实例外,它们还有一个共同的特性——非线性。这两种函数虽然在形式上有所不同,但都不是线性的,
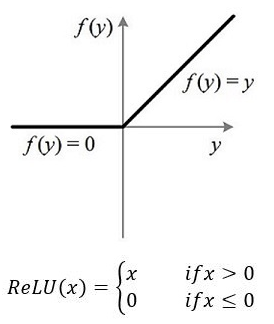
ReLU激活函数:简单之美
原址 导语 在深度神经网络中,通常使用一种叫修正线性单元(Rectified linear unit,ReLU)作为神经元的激活函数。ReLU起源于神经科学的研究:2001年,Dayan、Abott从生物学角度模拟出了脑神经元接受信号更精确的激活模型,如下图: 其中横轴是时间(ms),纵轴是神经元的放电速率(Firing Rate)。同年,Attwell等神经科学家通过研究大脑的
![[机器学习] softmax,sigmoid,relu,tanh激活函数](https://img-blog.csdnimg.cn/img_convert/25145fe35a0055a899553c9c5dad10e8.png)
[机器学习] softmax,sigmoid,relu,tanh激活函数
参考: https://blog.csdn.net/weixin_43483381/article/details/105232610 参考 :https://blog.csdn.net/zhuiyuanzhongjia/article/details/80576779 参考: https://www.sohu.com/a/452666201_809317 softmax 与 sigmoid 结
一位中国博士把整个 CNN 都给可视化了,可交互有细节,每次卷积 ReLU 池化都清清楚楚...
本文经AI新媒体量子位(公众号ID:qbitai)授权转载,转载请联系出处 本文约900字,建议阅读5分钟。 本文带你一张图看懂CNN。 标签:人工智能技术 CNN是什么?美国有线电视新闻网吗? 每一个对AI抱有憧憬的小白,在开始的时候都会遇到CNN(卷积神经网络)这个词。 但每次,当小白们想了解CNN到底是怎么回事,为什么就能聪明的识别人脸、听辨声音的时候,就懵了,只好理解为玄学: 好吧,
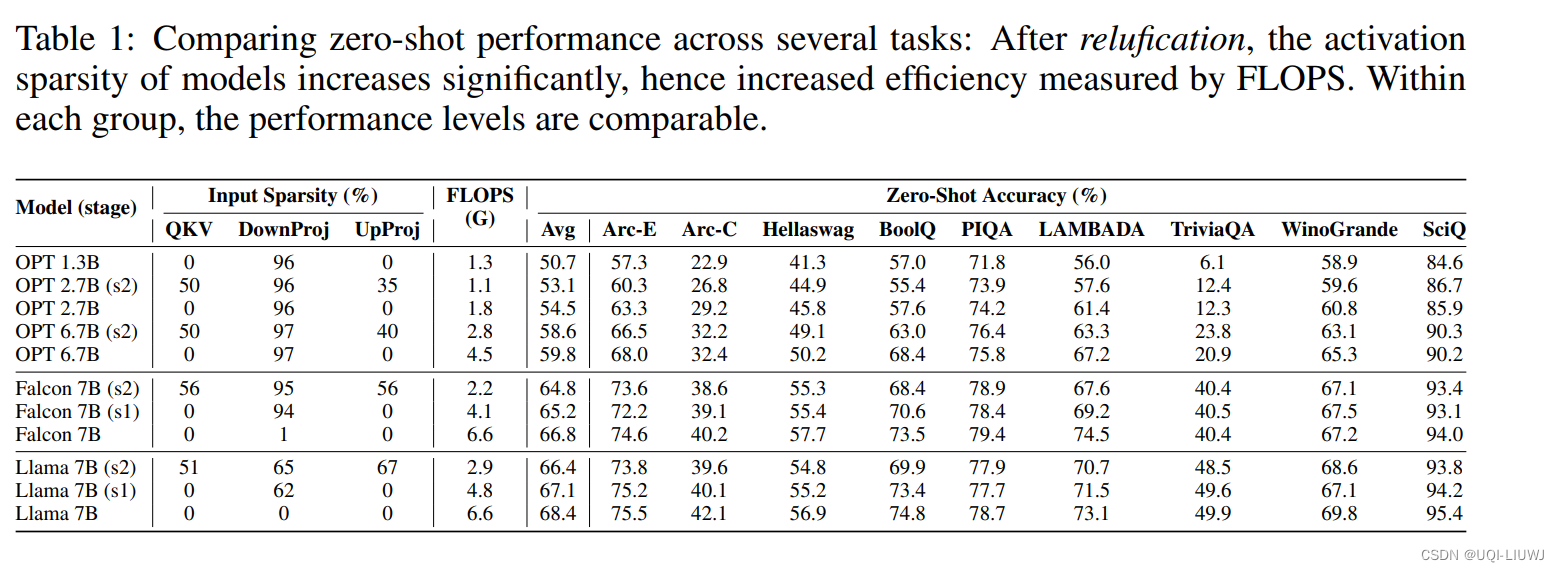
ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
iclr 2024 oral reviewer 评分 688 1 intro 目前LLM社区中通常使用GELU和SiLU来作为替代激活函数,它们在某些情况下可以提高LLM的预测准确率 但从节省模型计算量的角度考虑,论文认为经典的ReLU函数对模型收敛和性能的影响可以忽略不计,同时可以显着减少计算和权重IO量\ 2 激活函数影响效果吗? 选用了开源的大模型 OPT,Llama
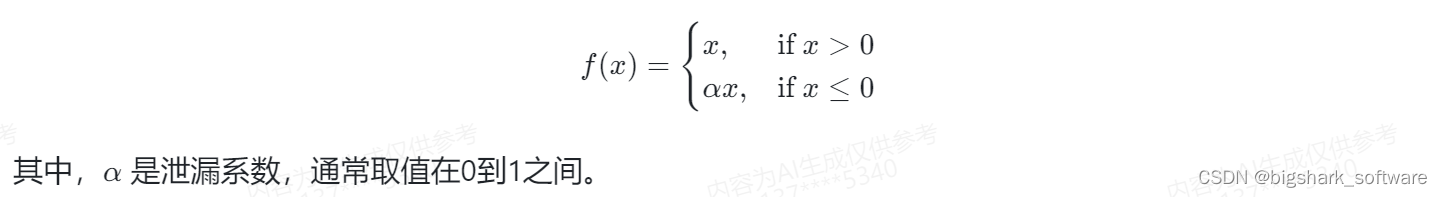
2024-04-05 问AI: 介绍一下深度学习中的Leaky ReLU函数
文心一言 Leaky ReLU(Leaky Rectified Linear Unit)函数是深度学习领域中的一种激活函数,主要用于解决ReLU(Rectified Linear Unit)函数在负值区域为零的问题。ReLU函数在输入为正时保持原样,而在输入为负时则输出为零,这可能导致某些神经元在训练过程中“死亡”或停止学习。 Leaky ReLU函数在负值区域有一个小的正斜率,使得即使输入为
relu神经元死亡的一种角度解释
最近在阅读 Airbnb 的论文 Applying Deep Learning to Airbnb Search。阅读的过程中,我发现作者在谈及特征归一化的必要性时,有如下表述: Feeding values that are outside the usual range of features can cause large gradients to back propagate. Thi
![[从0开始AIGC][Transformer相关]:Transformer中的激活函数:Relu、GELU、GLU、Swish](https://img-blog.csdnimg.cn/img_convert/b6acc964c165baeb1ebaad9ecdac1c8d.png)
[从0开始AIGC][Transformer相关]:Transformer中的激活函数:Relu、GELU、GLU、Swish
[从0开始AIGC][Transformer相关]:Transformer中的激活函数 文章目录 [从0开始AIGC][Transformer相关]:Transformer中的激活函数1. FFN 块 计算公式?2. GeLU 计算公式?3. Swish 计算公式?4. 使用 GLU 线性门控单元的 FFN 块 计算公式?5. 使用 GeLU 的 GLU 块 计算公式?6. 使用 Swis
python绘制激活函数(sigmoid, Tanh, ReLU, Softmax)
import numpy as npimport matplotlib.pyplot as plt# matplotlib的负数显示设置 plt.rcParams['axes.unicode_minus'] = False # 显示负数# 输出高清图像%config InlineBackend.figure_format = 'retina'%matplotlib inline#
keras代码阅读-relu函数
概述 relu是激活函数的一种。很多地方说relu函数的公式就是: f(x)=max(0,x) f(x)= max(0,x) 阅读了theano的代码 def relu(x, alpha=0):"""Compute the element-wise rectified linear activation function... versionadded:: 0.7.1Par
Tensorflow2.0笔记 - 常见激活函数sigmoid,tanh和relu
本笔记主要记录常见的三个激活函数sigmoid,tanh和relu,关于激活函数详细的描述,可以参考这里: 详解激活函数(Sigmoid/Tanh/ReLU/Leaky ReLu等) - 知乎 import tensorflow as tfimport numpy as nptf.__version__#详细的激活函数参考资料#https://zhuanla
ICLR 2024|ReLU激活函数的反击,稀疏性仍然是提升LLM效率的利器
论文题目: ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models 论文链接: https://arxiv.org/abs/2310.04564 参数规模超过十亿(1B)的大型语言模型(LLM)已经彻底改变了现阶段人工智能领域的研究风向。越来越多的工业和学术研究者开始研究LLM领域

猫头虎分享已解决Bug || ImportError: cannot import name ‘relu‘ from ‘keras.layers‘
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 — 从Web/安卓到鸿蒙大师!《100天精通Golang(基础入门篇)》 — 踏入Go语言世界的第一步!《100天精通Go语言(精品VIP版)》 — 踏入Go语言世界的第二步!

神经网络之激活函数(sigmoid、tanh、ReLU)
神经网络之激活函数(Activation Function) 补充:不同激活函数(activation function)的神经网络的表达能力是否一致? 激活函数理论分析对比 转载:http://blog.csdn.net/cyh_24 :http://blog.csdn.net/cyh_24/article/details/50593400 日常 coding 中,我们会很自然
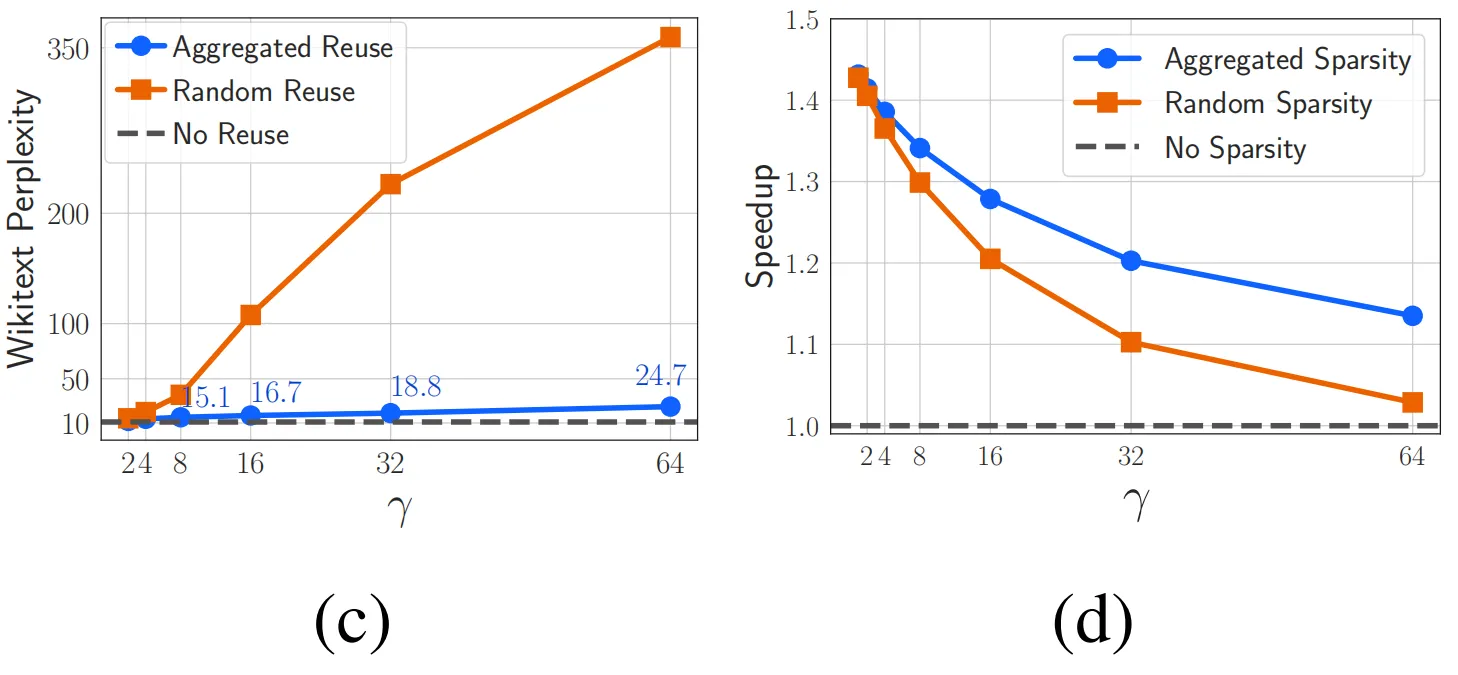
激活函数-Sigmoid,Tanh,ReLu,softplus,softmax
PS:在学习深度学习的搭建时,用到不同的激活函数,因此查阅了这些函数,转自:http://blog.csdn.net/qrlhl/article/details/60883604#t2,对其中我认为有误的地方进行了一点修正。 不管是传统的神经网络模型还是时下热门的深度学习,我们都可以在其中看到激活函数的影子。所谓激活函数,就是在神经网络的神经元上 运行的函数,负责将神经元的输入映射到输出
2、卷积和ReLU激活函数
python了解集合网络如何创建具有卷积层的特性。 文章目录 简介特征提取(Feature Extraction)卷积过滤(Filter with Convolution)Weights(权重)激活(Activations)用ReLU检测示例 - 应用卷积和ReLU结论 In [1]: import numpy as npfrom itertools import p

激活函数介绍Sigmoid,tanh,Relu,softmax。
什么是激活函数? 在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数 Activation Function。 2.为什么引入非线性激励函数? 若不使用激励函数,每一层的输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(perceptron)。 非线性函数作为激励函数,这样深层

为什么说ReLU是非线性激活函数
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。它的图像如下所示: 一直不明白为什么说ReLU函数是非线性激活函数,因为看起来就是一个线性的函数,今天查了一下,虽然仍然不是很明白,但是比以前要有深一点的理解主要是参考了一下连接

50、实战 - 利用 conv + bn + relu + add 写一个残差结构
上一节介绍了残差结构,还不清楚的同学可以返回上一节继续阅读。 到了这里,一个残差结构需要的算法基本都介绍完了,至少在 Resnet 这种神经网络中的残差结构是这样的。 本节我们做一个实战,基于之前几节中手写的 conv / bn 算法,来搭建一个残差结构。其中,relu 的实现和 add 的实现很简单。 relu 算法的实现用 python 来写就一行: def ComputeReluLa

self.relu = nn.ReLU(inplace = True) 里面的inplace什么意思,一般怎么设置?
在深度学习中,ReLU(修正线性单元)是一种常用的激活函数,其定义为 f(x) = max(0, x)。nn.ReLU是在PyTorch中实现ReLU的类。 参数`inplace`是nn.ReLU类的一个可选参数,默认值为False。该参数控制着ReLU函数的计算方式。 当`inplace=False`时,ReLU函数会返回一个新的张量作为输出,不改变原始张量。这意味着原始张量在ReLU前后的
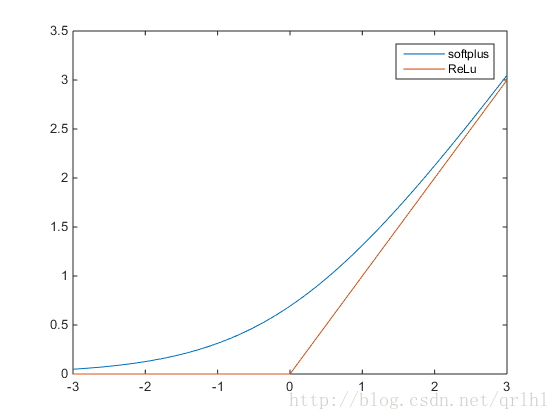
RELU是分段线性函数,怎么实现非线性呢?
ReLu虽然在大于0的区间是线性的,在小于等于0的部分也是线性的,但是它整体不是线性的,因为不是一条直线。多个线性操作的组合也是一个线性操作,没有非线性激活,就相当于只有一个超平面去划分空间。但是ReLu是非线性的,效果类似于划分和折叠空间,组合多个(线性操作 + ReLu)就可以任意的划分空间。 对于浅层的机器学习,比如经典的三层神经网络,用它作为激活函数的话,那表现出来的性质肯定是线性的。但