本文主要是介绍ICLR‘2024时间序列论文汇总!预测、分析、分类等方向的最新进展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ICLR作为机器学习领域的顶级国际会议,每年都吸引了全球众多顶尖学者和研究者的目光。2024的ICLR会议,将在5月7日至11日在奥地利的维也纳会展中心举行,现在会议论文审稿结果也已经出来了,本届ICLR 2024共收到了7262篇提交论文,整体接收率约为31%。
今天给大家从中整理了一些时间序列领域的高分论文,涵盖了预测、分析、分类、对比学习和插补研究方向,这些论文展示了时间序列领域最新的研究成果,一起看看吧!
时间序列预测
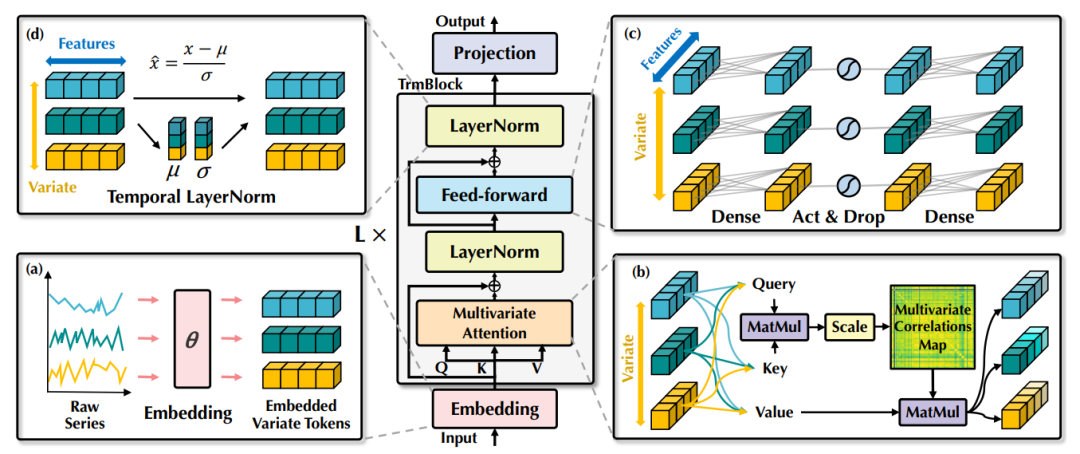
1、iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
iTransformer:反相变压器对时间序列预测有效
简述:本文提出了 iTransformer,它通过在反向维度上应用注意力和前馈网络,简单地处理时间序列数据,这种方法允许模型捕捉多变量之间的相关性,并通过前馈网络学习非线性表示。iTransformer 在多个真实数据集上的表现超越了现有技术,提升了 Transformer 在时间序列预测任务中的性能和泛化能力。
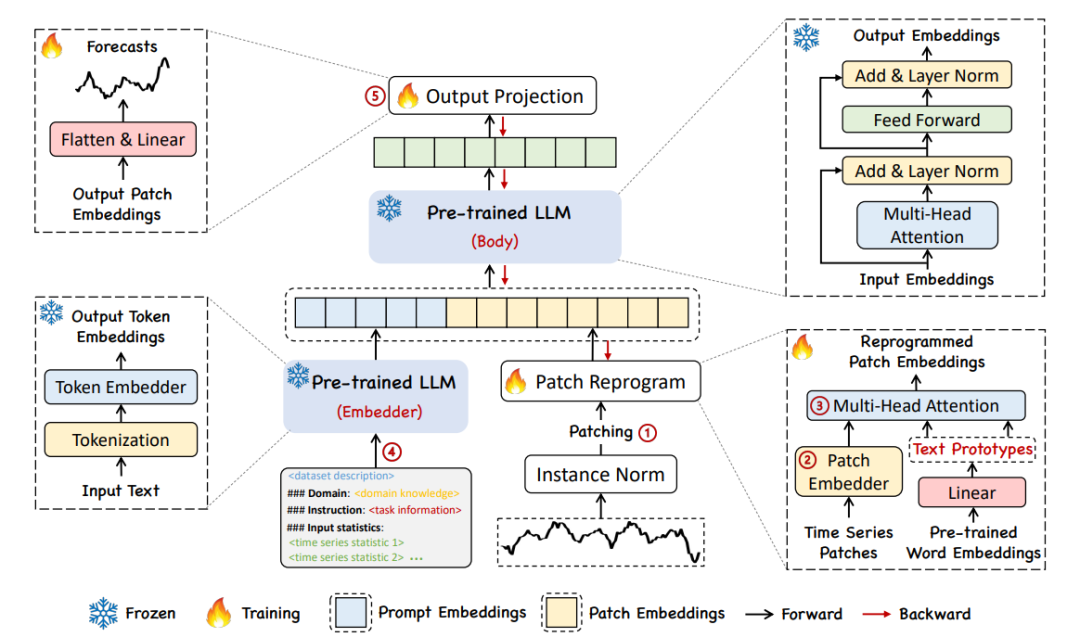
2、Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Time-LLM:通过重新编程大型语言模型进行时间序列预测
简述:本文提出了一个 Time-LLM 框架,通过将大型语言模型(LLM)重新编程用于时间序列预测,同时保留其核心结构。研究人员使用文本原型对时间序列进行重新编程,并利用 Prompt-as-Prefix(PaP)增强 LLM 处理时间序列数据的能力。Time-LLM 在多种数据集上的表现优于其他预测模型,尤其在小型和零样本学习环境中表现出色。
3、Interpretable Sparse System Identification: Beyond Recent Deep Learning Techniques on Time-Series Prediction
可解释稀疏系统识别:超越时间序列预测的最新深度学习技术
简述:本文提出了一种新的可解释稀疏系统识别方法,用于时间序列预测,它结合了基于知识和数据驱动的方法,利用傅里叶基处理时间序列数据,并通过稀疏优化实现高精度预测。该方法无需耗时的反向传播训练,并在多个基准数据集上展示了与最先进深度学习方法相比超过 20%的性能提升。此外,该方法在 CPU 上表现出高效的训练能力,本研究为时间序列预测领域提供了新的思路。

4、ClimODE: Climate Forecasting With Physics-informed Neural ODEs
ClimODE: 基于物理信息的神经ODEs气候预测
简述:本文提出了 ClimODE,一种结合了物理信息和深度学习的气候预测方法。ClimODE 通过学习全球天气传输作为神经流,实现了精确的天气演变和价值保持动态的建模,同时支持预测中的不确定性估计。该方法在全球和区域预测中优于现有数据驱动方法,且参数化规模小,为气候预测领域带来了新的技术突破。

5、TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
TEMPO:用于时间序列预测的基于提示的生成式预训练转换器
简述:本文提出了 TEMPO 框架,用于有效学习时间序列表示。该框架关注两个基本归纳偏差:一是分解趋势、季节性和残差分量之间的相互作用;二是引入选择性提示以适应非平稳时间序列的分布。实验结果表明,TEMPO 在多个时间序列基准数据集上优于最先进的方法,并在新数据集和多模态输入场景中表现出色,展示了其作为基础模型构建框架的潜力。

时间序列分析
6、ModernTCN: A Modern Pure Convolution Structure for General Time Series Analysis
ModernTCN:用于一般时间序列分析的现代纯卷积结构
简述:本文研究了如何在时间序列分析中更有效地利用卷积,提出了一种现代化的 TCN结构,称为 ModernTCN。通过针对时间序列任务进行调整,ModernTCN 在长期和短期预测、插补、分类和异常检测等五种任务上实现了优异的性能,同时保持了卷积模型的效率优势。与基于 Transformer 和 MLP 的模型相比,ModernTCN 提供了更好的效率和性能平衡,并展示了更大的有效感受野,从而更好地利用了卷积在时间序列分析中的潜力。

7、FITS: Modeling Time Series with Parameters
FITS:使用 参数对时间序列进行建模
简述:本文提出了FITS,是一种基于复频域操作的时间序列分析模型,它通过在频域中的插值来处理数据,避免了处理高频分量。FITS在性能上可与最新模型相媲美,但参数数量极少,使其非常适合在边缘设备上部署,这种轻量级模型为多种应用提供了便利。

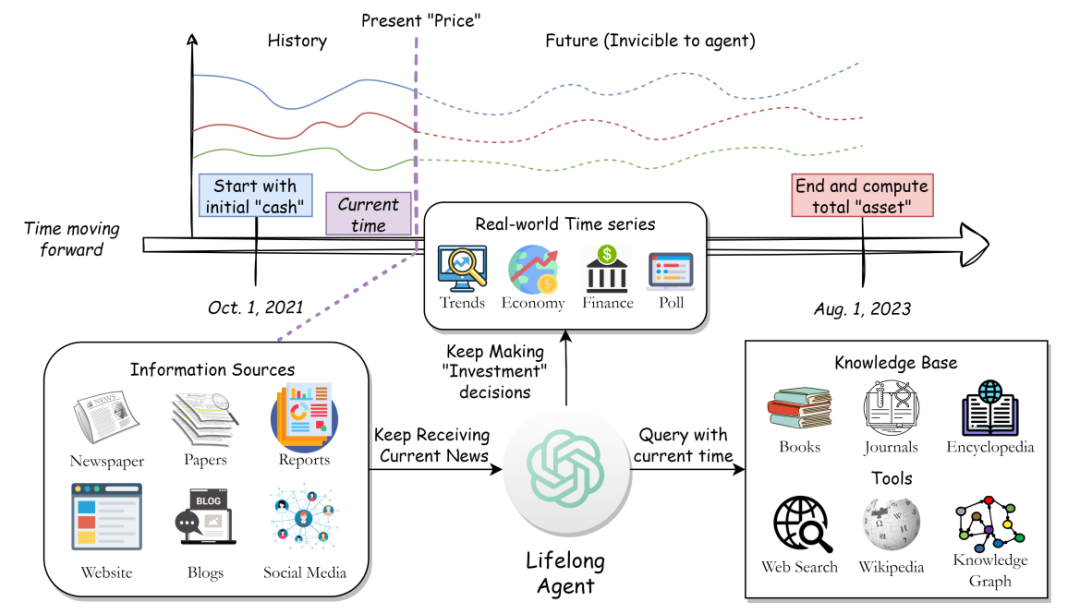
8、SocioDojo: Building Lifelong Analytical Agents with Real-world Text and Time Series
SocioDojo:使用真实世界的文本和时间序列构建终身分析代理
简述:本文提出了SocioDojo,一个用于开发自主代理的环境,这些代理可以对经济、金融等社会主题进行决策。该环境包括多种信息源和知识库,以及高质量的时间序列数据,这些数据支持一项新任务,旨在评估智能体的决策能力。研究人员提出了一种新颖的架构和提示,用于深入分析新闻和文章。实验结果表明,这个方法相比现有技术提高了32.4%和30.4%的性能。
9、Tim Series Continuous Modeling for Imputation and Forecasting with Implicit Neural Representations
使用隐式神经表示进行插补和预测的时间序列连续建模
简述:本文提出了一种新方法,用于处理不规则时间序列数据中的插补和预测问题,如不规则样本、缺失数据和未对齐的传感器测量。该方法基于连续时间动力学模型,结合隐式神经表示和元学习算法,允许模型适应新数据并外推预测。它在多个基准测试中展现出先进的性能。

10、Leveraging Generative Models for Unsupervised Alignment of Neural Time Series Data
利用生成模型对神经时间序列数据进行无监督对齐
简述:在神经科学中,大规模推理模型用于从高维神经记录中提取表征,但从头训练新模型成本高且效率低。为解决此问题,本文提出了一种无源无监督的对齐方法,利用学习到的动态重用预训练的生成模型,避免从头训练,并在模拟中验证了该方法对运动皮层神经记录的对准效果。

时间序列分类
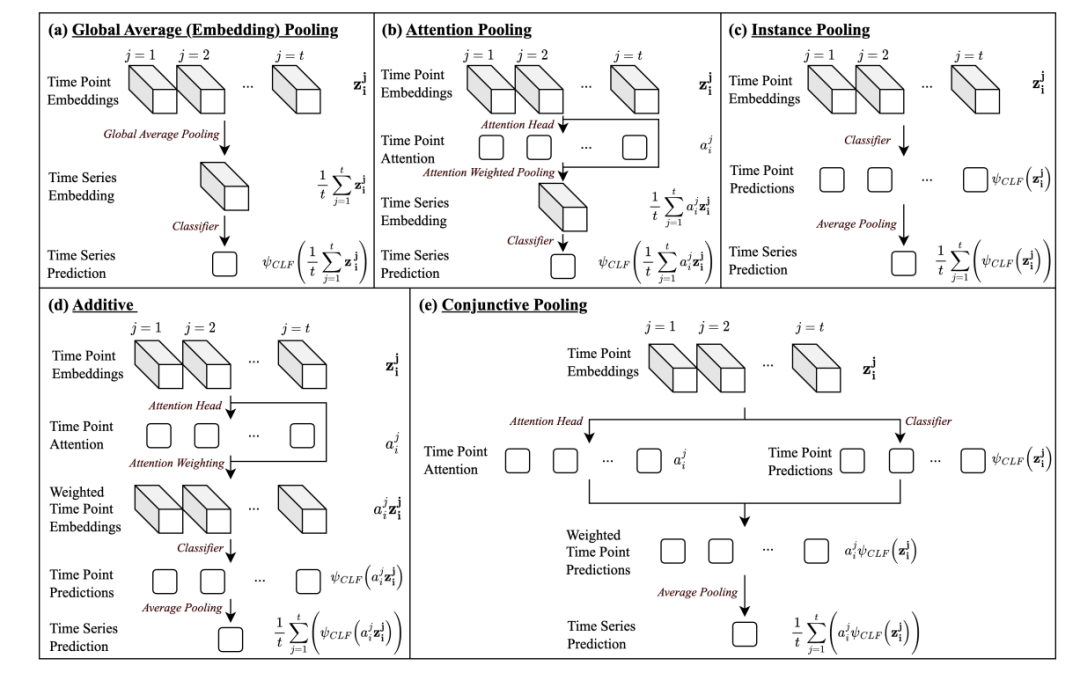
11、Inherently Interpretable Time Series Classification via Multiple Instance Learning
通过多实例学习实现固有可解释的时间序列分类
简述:本文提出了MILLET框架,利用多实例学习(MIL)使深度学习时间序列分类(TSC)模型变得可解释,同时保持或提升预测性能。MILLET在85个UCR TSC数据集上进行了评估,并提出了一个促进可解释性评估的新合成数据集。实验表明,MILLET能快速生成高质量的稀疏解释,是第一个将通用MIL方法应用于TSC的通用框架。
12、LogoRA: Local-Global Representation Alignment for Robust Time Series Classification
LogoRA:用于稳健时间序列分类的局部-全局表示对齐
简述:本文提出了LogoRA框架,用于无监督域自适应的时间序列,它使用两分支编码器提取全局和局部特征,并通过融合模块增强多尺度下的域不变对齐。LogoRA通过多种策略实现有效对齐,包括在源域学习不变特征、使用三元组损失精细调整以及基于动态时间规整的对齐。实验显示,LogoRA在四个时间序列数据集上优于基线,展示了其在时间序列UDA任务中的优越性。

对比学习
13、Soft Contrastive Learning for Time Series
时间序列的软对比学习
简述:本文提出了SoftCLT,一种简单有效的对比学习策略,能提高时间序列的学习表示质量。它通过引入实例和时间对比损失实现,软分配范围从零到一。SoftCLT适用于对比学习,无需复杂操作。实验证明,它在分类、半监督、迁移和异常检测等任务中表现卓越。

14、Towards Enhancing Time Series Contrastive Learning: A Dynamic Bad Pair Mining Approach
迈向更好的时间序列对比学习:一种动态的坏对挖掘方法
简述:本文研究了两种不良正对,它们会损害时间序列对比学习的质量,并提出了一种动态坏对挖掘(DBPM)算法,该算法能够可靠地识别和抑制时间序列对比学习中的坏正对。DBPM 利用内存模块来跟踪训练过程中每个正对的训练行为,识别并抑制不良正对。实验结果表明,DBPM有效地减轻了不良对的负面影响,并且可以很容易地用作插件来提高最先进方法的性能。

15、Learning to Embed Time Series Patches Independently
学习独立嵌入时间序列修补程序
简述:本文提出了一种改进的时间序列自监督表示学习策略,研究人员建议简单的补丁重建任务,该任务自动编码每个补丁而不查看其他补丁,以及独立嵌入每个补丁的简单补丁 MLP。还引入了互补对比学习,以有效地分层捕获相邻的时间序列信息。与最先进的基于 Transformer 的模型相比,这种方法提高了时间序列预测和分类性能,同时在参数数量和训练/推理时间方面效率更高。

16、Parametric Augmentation for Time Series Contrastive Learning
时间序列对比学习的参数增强
简述:本研究通过信息论分析时间序列数据增强,提出了一种编码器无关的对比学习框架AutoTCL,它可以适应性地用于支持时间序列表征学习。所提出的方法是编码器无关的,允许它无缝地与不同的骨干编码器集成。实验表明,该方法在单变量预测任务中性能优异,平均MSE降低6.5%,MAE降低4.7%。在分类任务中,AutoTCL实现了平均准确度的1.2%提高。

时间序列插补
17、Conditional Information Bottleneck Approach for Time Series Imputation
简述:本文提出了一种新的时间序列条件信息瓶颈(CIB)插补方法通过减少与时间上下文相关的冗余信息来减轻正则化约束的影响。该方法结合了证据下界和新型时间核增强对比优化,以实现CIB目标。实验表明,该方法显著提升了插补性能,包括插值和外推,并增强了基于插补值的分类性能。

码字不易,欢迎大家点赞评论收藏!
关注下方《享享学AI》
回复【ICLR时间序列】获取完整论文
👇
这篇关于ICLR‘2024时间序列论文汇总!预测、分析、分类等方向的最新进展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





