本文主要是介绍(2024|ICLR,MAD,真实数据与合成数据,自吞噬循环)自消耗生成模型变得疯狂,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Self-Consuming Generative Models Go MAD
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
2. 自吞噬生成模型
2.1 自吞噬过程
2.2 自吞噬过程的变体
2.3 自吞噬循环中的偏向采样
2.4 MADness 的度量
3. 完全合成循环:完全在合成数据上进行训练导致 MADness
4. 合成增强循环:固定的真实训练数据可能会延迟,但无法阻止MADness
5. 新鲜数据循环:新鲜的真实数据可以阻止 MADness
6. 讨论
0. 摘要
地震性的进展在涉及图像、文本和其他数据类型的生成式人工智能算法方面,引发了使用合成数据训练下一代模型的诱惑。重复这个过程会形成一个性质尚不明确的 “自吞噬”(autophagous,“self-consuming”)循环。我们进行了一项全面的分析和实证研究,使用最先进的生成式图像模型,研究了三个家族的自吞噬循环,对于在各代模型训练中可用的固定或新鲜的真实训练数据量,以及先前的生成模型的样本是否被偏向于权衡数据质量与多样性,这些循环存在差异。在所有情景下,我们的主要结论是,如果在自吞噬循环的每一代中没有足够的新鲜真实数据,未来的生成模型注定会在质量(精确度)或多样性(召回率)方面逐渐下降。我们将这种情况称为 “模型自吞噬紊乱”(Model Autophagy Disorder,简称 MAD),类比疯牛病。


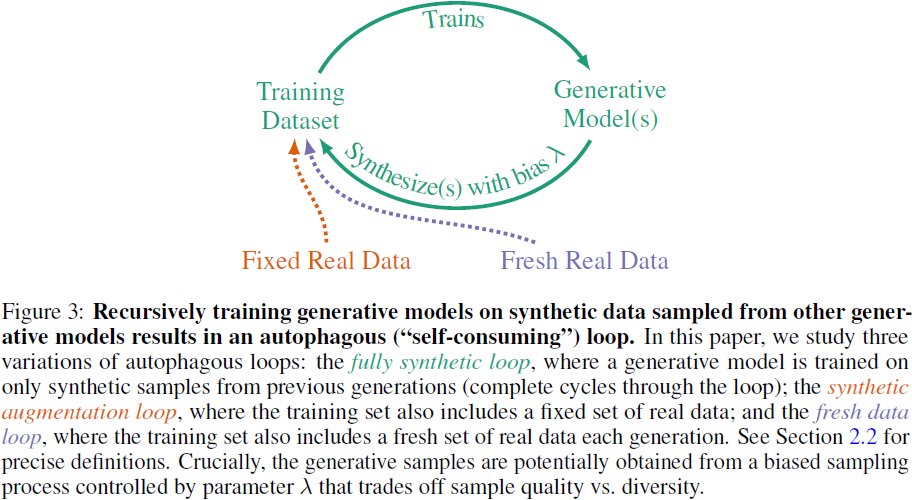
2. 自吞噬生成模型
现代生成模型在合成真实数据(信号、图像、视频、文本等)方面取得了迅速的进展,只需从参考(目标)概率分布 P_r 中获取有限的训练样本集合即可。随着生成模型的不断涌现,除了从 P_r 中抽取的 “真实世界” 样本(参见图 3),用于训练新模型的数据集在无意中(参见 [17] 和图 2)或有意 [57, 64–67] 地开始包含越来越多的合成数据。在这一部分,我们提出了一系列逐渐逼真的模型,用于描述这种自吞噬现象(autophagy,self-consuming),这将使我们能够得出关于合成训练数据不断增加对生成建模的潜在影响的许多结论。
2.1 自吞噬过程
考虑一个生成模型序列 (G^t) t∈N,其目标是训练每个模型以逼近参考概率分布 P_r。在每一代 t ∈ N 中,模型 G_t 是从头开始训练的,使用数据集
![]()
其中包含了从 P_r 中抽取的 n^t_r 个真实数据样本 D^t_r 和由已经训练过的生成模型产生的 n^t_s 个合成数据样本 D^t_s。第一代模型 G^1 是纯粹基于真实数据训练的,即 n^1_s = 0。
定义:自吞噬生成过程是一个分布的序列 (G^t) t∈N,其中每个生成模型 G^t 都是在包括来自先前世代模型 (G^τ )^(t−1)_(τ=1) 的样本的数据上进行训练的。
在这项工作中,我们研究了这种过程随时间恶化(即变得 “MAD”)的情况。让 dist(·, ·) 表示分布的某个距离度量。
定义:MAD 生成过程是一个随机漫步的分布的序列 (G^t) t∈N,使得 E[dist(G^t, P_r)] 随 t 增加。
声明:在温和的条件下,自吞噬生成过程是一个 MAD 生成过程。
通过研究生成模型序列 (G^t) t∈N 是否形成 MAD 生成过程,我们可以深入了解在合成数据上训练生成模型可能产生的有害影响。
自吞噬过程 MAD 的两个关键方面是训练集中真实数据和合成数据的平衡(第 2.2 节)以及从生成模型中抽样合成数据的方式(第 2.3 节)。
2.2 自吞噬过程的变体
在本文中,我们研究了三种现实的自吞噬机制,每种机制都在一个反馈循环中包括合成数据和潜在的真实数据(参见图 3)。我们现在为第 1.2 节的描述添加一些额外的细节:
- 完全合成循环(fully synthetic loop):在这种情景中,对于 t ≥ 2 的每个模型 G^t 都是完全在先前世代模型 (G^τ )^(t−1)_(τ=1) 生成的合成数据 D^t_s 上进行训练的,即 D^t = D^t_s。
- 合成增强循环(synthetic augmentation loop):在这种情景中,对于 t ≥ 2 的每个模型 G^t 都是在由从 P_r 中抽取的固定真实数据 D_r 和先前世代模型生成的合成数据 D^t_s 组成的数据集 D^t = (D_r,D^t_s) 上进行训练的。
- 新鲜数据循环(fresh data loop):在这种情景中,对于 t ≥ 2 的每个模型 G^t 都是在由独立从 P_r 中抽取的新鲜真实数据 D^t_r 和先前世代模型生成的合成数据 D^t_s 组成的数据集 D^t = (D^t_r ,D^t_s) 上进行训练的。
2.3 自吞噬循环中的偏向采样
虽然上述三种自吞噬循环在现实中模拟了涉及合成数据的生成模型训练场景,但同时考虑每一代合成数据是如何生成的也是至关重要的。特别是,不是所有来自生成模型的合成样本都具有相同的对训练分布的忠实度,或者说 “质量”。因此,在许多应用中(例如艺术生成),从业者会基于对感知质量的手动评估 “挑选” 合成样本。可以认为,今天在互联网上找到的大多数合成图像在某种程度上都是根据人类对感知质量的评估进行了挑选。因此,将这种概念纳入自吞噬循环的建模和分析是至关重要的。
在我们的建模和分析中,我们通过在生成建模实践中常用的偏向采样方法来实现 “挑选”,例如 BigGAN 和 StyleGAN [38, 58] 中的截断,扩散模型 [42] 中的引导,极性采样(polarity sampling) [68],以及大型语言模型中的温度采样 [7]。这些技术假定数据流形在学习分布的高密度区域中更好地近似。通过偏向于从接近生成模型分布 G^t 模式的部分抽取合成样本,这些方法通过在合成数据的多样性与质量之间进行权衡来提高样本的忠实度或质量 [68]。
在我们的实验中,我们使用了多个生成模型,每个模型都有一个唯一可控的参数,用于提高样本质量。我们将这些参数统一为通用的采样偏差参数 λ ∈ [0, 1],其中 λ = 1 对应于无偏采样,λ = 0 对应于从生成分布 G^t 的模式中采样,方差为零。λ 的确切解释在各种模型中有所不同,但通常随着 λ 从 1 减小,合成样本的质量将增加,多样性将减少。在下文中,我们为本文考虑的各种生成模型提供了 λ 的具体定义:
高斯模型:我们的理论分析和简化实验使用了一个多元高斯玩具模型(toy model)。为了在第 t 代实现偏向采样,我们估计训练数据的均值 μ_t 和协方差 Σ_t,然后从分布 N(μ_t, λΣ_t) 中抽样。当 λ 减小时,我们抽取更接近均值 μ_t 的样本。
生成对抗网络(GAN):在我们的 StyleGAN 实验中,我们使用截断参数来提高采样质量。基于风格的生成网络使用称为风格空间的辅助潜在空间。在推理过程中使用截断时,风格空间中的潜在向量会线性插值到风格空间潜在分布的均值。我们用 λ 表示截断因子;随着 λ 从 1 减小,样本被抽取得更接近风格空间分布的均值。
降噪扩散概率模型(DDPM):对于条件扩散模型,我们使用无分类器的扩散引导 [42] 来偏向于更高概率区域的采样。在训练期间,我们使用 10% 的条件丢弃来启用无分类器引导。我们将偏见参数 λ 根据 [42] 中的引导因子 w 定义为 λ = 1 / (1+w)。当 λ = 1时,网络充当常规条件扩散模型而无引导。随着 λ 的减小,扩散模型更接近无条件分布的模式,产生更高质量的样本。
2.4 MADness 的度量
确定自吞噬循环是否发展成 MAD(回顾定义 2.1)需要我们测量合成数据分布 G^t 在各代 t 中与真实数据分布 P_r 偏离的程度。我们使用作为 Fréchet Inception Distance(FID)实现的 Wasserstein 距离(WD)来衡量。对于质量和多样性的概念,我们还将精确度和召回率(precision and recall)的标准概念用于严格定义。
3. 完全合成循环:完全在合成数据上进行训练导致 MADness
在这里,我们对完全合成循环进行了彻底的分析,其中每个模型都是使用先前世代的合成数据进行训练的。我们关注由估计误差和采样偏差导致的代际非理想传播。具体而言,我们指出了这些非理想性的主要来源,并对循环的收敛性进行了表征。完全合成循环的简单性意味着它并不能准确反映生成建模实践的现实情况。然而,这种情况的一个具体例子是生成模型在其自己的高质量输出上进行微调的情况 [56]。尽管如此,这个循环在某种意义上是最坏的情况,因此提供了有价值的见解,可以推广到后续部分讨论的更实际的自吞噬循环。

没有采样偏差时,合成数据的质量降低:
- 在完全合成循环中,如果仅仅在合成数据上进行训练而没有采样偏差,生成模型的合成数据的质量和多样性会随着世代的增加而降低。
- 没有采样偏差的情况下,合成数据的模式会从真实模式漂移并融合。
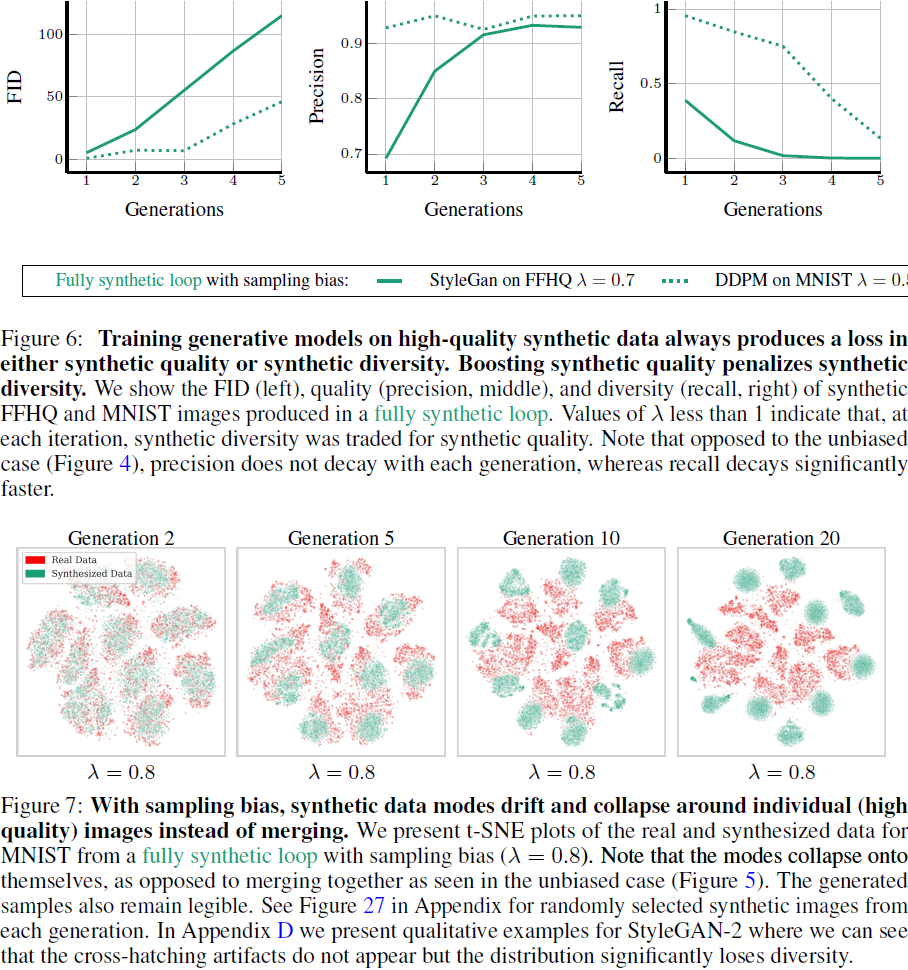
使用偏差采样,质量可能会提高,但多样性会迅速减少:
- 在高质量合成数据上训练生成模型总是会导致合成质量或合成多样性的损失。提高合成质量会惩罚合成多样性。
- 在采样偏差的情况下,合成数据的模式会围绕着个别(高质量)图像漂移和崩溃,而不是融合。
4. 合成增强循环:固定的真实训练数据可能会延迟,但无法阻止MADness
尽管在完全合成循环中的分析是可行的,但很难相信它会代表真实实践。在训练真实的生成模型时,从业者总是倾向于在可能的情况下使用至少一些真实数据。在本节中,我们探讨合成增强循环,其中训练数据由一个固定的真实数据集组成,逐渐增加了合成数据。
我们通过最近在分类任务中使用生成模型增强数据集的实践来推动合成增强循环,由于生成模型的进展,这一实践已经取得了有希望的结果 [26, 27]。然而,使用生成模型进行数据增强的影响仍然没有完全被理解。虽然增加训练数据的量通常会提高机器学习模型的性能,但当合成样本被引入数据集时,由于合成数据可能偏离真实数据分布的潜在偏差,存在不确定性。即使存在小的差异,也可能影响模型对真实世界数据分布的忠实度。正如我们所展示的,固定的真实数据集的存在并不足以阻止这个循环产生一个 MAD 生成过程。
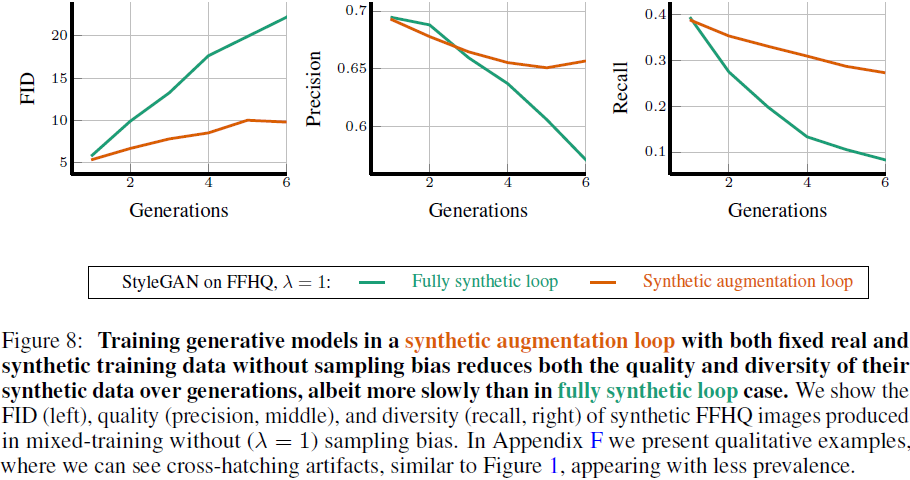
在合成增强循环中,在固定的真实和合成训练数据的情况下进行生成模型训练,即使没有采样偏差,也会使其合成数据的质量和多样性随着世代的增加而降低,尽管比完全合成循环的情况下慢一些。
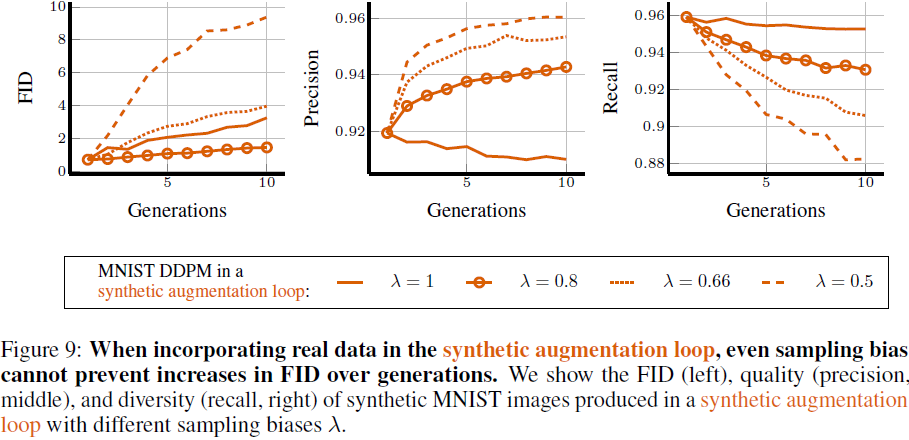
在合成增强循环中引入真实数据时,即使采用采样偏差,也不能阻止 FID 在世代间的增加。
5. 新鲜数据循环:新鲜的真实数据可以阻止 MADness
我们的自吞噬循环模型中最精美部分使用来自两个来源新的训练数据:来自参考分布的新鲜真实数据和先前训练的生成模型的合成数据。这一现象在 LAION-5B 数据集 [17] 中已经有了明确的例子,该数据集已经包含了来自生成模型(例如 Stable Diffusion [2])的图像(参见图 2)。
为了理解以这种方式训练的生成模型的演变,本节中我们调查新鲜数据循环,它将合成增强循环进一步扩展,每次迭代都加入新的真实数据样本。具体而言,我们假设真实数据样本只占可用数据池(例如训练数据集或互联网)的一部分 p ∈ (0, 1),而剩余部分 1−p 来自生成模型的合成数据。当我们从这样的训练数据集中独立采样 n^t 个数据点来训练第 t 代的生成模型时,有 n^t_r = pn^t 个数据点来自真实分布,有 n^t_s = (1 − p)n^t 个来自合成数据。

在这个背景下,我们在下面的实验中观察到,新鲜数据样本的存在幸运地缓解了 MAD 生成过程的发展;即新鲜的真实数据有助于使生成分布保持在参考分布附近,而不是经历纯粹的随机漫步。然而,我们仍然观察到一些令人担忧的现象。
首先,我们发现,不论早期代的性能如何,后续代的性能都会收敛到一个仅取决于训练循环中的真实和合成数据量的点。在自吞噬的背景下,这一点带来了一些希望:随着每一代引入新鲜数据,E[dist(G^t, P_r)] 并不一定会随着 t 的增长而增加。因此,新鲜数据循环可以防止MAD 生成过程。
其次,我们发现,虽然有限数量的合成数据实际上可以改善新鲜数据循环中的分布估计——因为合成数据有效地将先前使用的真实数据传递给后续代,并增加了有效数据集的大小——但过多的合成数据仍然会显著降低分布估计的性能。
我们通过高斯模拟来精确观察这一点。具体而言,我们考虑从方程(3)中得到的新鲜数据循环的极限点。利用这个极限点的值,我们通过蒙特卡洛模拟与仅在大小为 n_e 的一组真实数据样本上训练的另一模型 G(n_e) 进行比较。我们将 n_e 称为有效样本大小,并在给定(n_r, n_s, λ)时,通过方程(4)计算其值:
![]()
也就是说,n_e 捕捉了新鲜数据循环极限点的样本效率。我们在实验中评估了 n_e / n_r 的比率。当 n_e / n_r ≥ 1 时,合成数据有效地增加真实样本数量,这被认为是可接受的(admissible),而对于 n_e / n_r < 1,合成数据实际上减少了真实样本的数量。
我们在图 11 和图 12 中绘制了这个实验结果的两个视角。我们发现了几个效应。
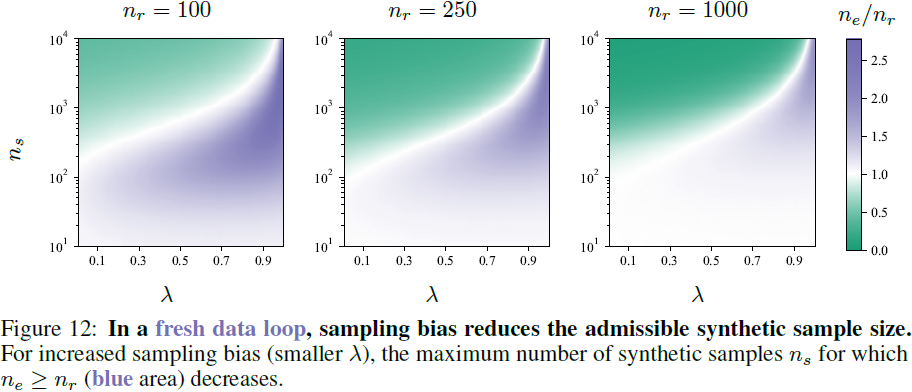
首先,我们对样本大小做了一些观察。我们发现,确实,对于给定的 n_r 和 λ < 1 的组合,存在 n_s 的相变(phase transition),如果 n_s 超过某个可接受的阈值,那么有效样本大小将低于新鲜数据样本大小。然而,我们发现 n_r 对 n_s 的比率并是固定值;实际上,我们发现相反的趋势。对于较小的 n_r 值,我们发现较大的 n_s 值可能是有用的,但随着 n_r 的增加,n_s 的相变阈值似乎变得恒定。
(注:这似乎解释了在 few-shot / zero-shot learning 中,使用大量的合成样本可以提升模型性能的现象)
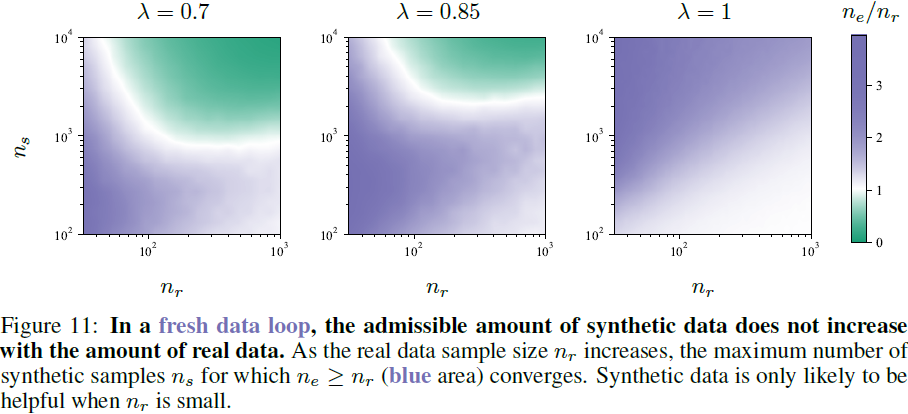
其次,我们对采样偏差参数 λ 的影响进行了一些观察。我们发现,n_s 的可接受阈值的值强烈依赖于合成过程中的采样偏差。令人惊讶的是,更多的采样偏差(较小的 λ)实际上会减少可以在不损害性能的情况下使用的合成样本数量。当 λ → 1 时,对于无偏采样的极限行为似乎确保了有效样本数始终会增加。这种极限行为是否延伸到高斯建模设置之外的其他生成模型尚不清楚。正如在第 2.3 节中讨论的那样,在实践中不太可能生成没有采样偏差的合成数据,因此我们认为最好从 λ < 1 的情况中得出结论。
6. 讨论
在本文中,我们试图推断随着生成模型变得普遍并被用于训练后代模型的自吞噬(自我消耗)循环在不久的将来和遥远的将来可能发生的情况。通过对最先进的图像生成模型和标准图像数据集进行分析和实验证明,我们研究了三类自吞噬循环,并强调了模型采样偏差的关键作用。一些影响显而易见:如果每一代都没有足够的新鲜真实数据,未来的生成模型注定会患上模型自吞噬障碍(MAD),这意味着它们的质量(以精度衡量)或多样性(以召回衡量)将逐渐降低,并且生成的人为效应将被放大。一个灾难性的场景是,如果不加控制地持续多代,MAD 可能会影响整个互联网的数据质量和多样性。即使在短期内,似乎 AI 自吞噬也不可避免地会带来迄今为止未曾预见的意外后果。
使用便宜且容易的合成数据进行训练的从业者,可以将我们的结论视为警告,并考虑调整其合成数据习惯,或许通过参与适当的 12 步计划。在真正缺乏数据的应用中,我们的结果可以被解释为指导未来需要多少有限的真实数据以避免 MAD 生成过程。例如,希望使用来自多个机构的匿名合成数据来训练全面的医学图像生成器的未来从业者 [29, 30] 现在应该知道,必须非常谨慎地确保:(i) 所有匿名合成图像都是无瑕疵且多样化的(参见完全合成循环),以及 (ii)(理想情况下是新的)真实数据尽可能多地出现在训练中(参见新鲜数据循环和合成增强循环)。
那些原本没有打算使用合成训练,但发现其训练数据池受到合成数据污染的情况更难处理。为了维护包含纯粹真实数据的可信数据集,明显的建议是社区开发方法来识别合成数据。然后可以使用这些方法过滤训练数据集以拒绝合成数据或保持合成到真实数据的特定比例。在这方面,AI 文献中与隐写术(steganography [40])密切相关的新方法的早期进展可以用于合成数据识别。由于生成模型不一定向生成的图像添加元数据(meta-data),另一种方法是对合成数据进行水印标记,以便在训练时可以识别和拒绝。目前有关 LLMs 生成的数据的水印的可靠性 [75] 和用于给 LLMs [76]、扩散模型 [77–80] 和 GANs [81] 添加水印的新方法是研究的活跃领域。我们对水印的一个保留意见是,它有意在合成数据中引入隐藏的人为制造的痕迹以使其可检测。这些痕迹可能会被自吞噬放大失控,将水印标记从有用变为有害。在新鲜数据循环中,我们看到大量的合成数据会损害性能,而适度量的合成数据实际上会提升性能。在这种情况下,水印可以帮助减少合成数据的量,并理想地将模型放置在良好的区域内(例如图 11 和图 12 中的蓝色区域),以避免水印的负面影响。这为研究关注自吞噬感知水印的新颖途径打开了有趣的方向。
这里报告的工作有许多可能的扩展,包括研究我们提出的三类自吞噬循环的组合。例如,可以分析训练数据包含来自先前生成模型的合成数据、一些固定真实数据和一些新鲜真实数据的自吞噬循环。我们的分析集中在合成和参考数据流形之间的距离上。一个有趣的研究问题是这种距离如何在AI 任务(如分类)的性能下降中体现出来(因为精度与分类器性能密切相关,这种联系有待建立)。
最后,在本文中,我们专注于图像,但我们的结论并没有使它们仅限于图像。任何类型的数据的生成模型都可以连接成自吞噬循环并变得 MAD。例如,一个数据类型是 LLMs 生成的文本(其中一些已经在来自 ChatGPT 等现有模型的合成数据上进行训练)[57, 66, 67],我们的精度和召回结果直接转化为经过多代自吞噬后生成的文本的特性。在同期工作 [53] 的实验中也得出了类似的结论,但在这方面还有很多工作要做。
这篇关于(2024|ICLR,MAD,真实数据与合成数据,自吞噬循环)自消耗生成模型变得疯狂的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







