本文主要是介绍ICLR 2023|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

©作者 | 机器之心编辑部
来源 | 机器之心
大模型时代,模型压缩和加速显得尤为重要。传统监督学习可通过稀疏神经网络实现模型压缩和加速,那么同样需要大量计算开销的强化学习任务可以基于稀疏网络进行训练吗?本文提出了一种强化学习专用稀疏训练框架,可以节省至多 95% 的训练开销。
深度强化学习模型的训练通常需要很高的计算成本,因此对深度强化学习模型进行稀疏化处理具有加快训练速度和拓展模型部署的巨大潜力。然而现有的生成小型模型的方法主要基于知识蒸馏,即通过迭代训练稠密网络,训练过程仍需要大量的计算资源。另外,由于强化学习自举训练的复杂性,训练过程中全程进行稀疏训练在深度强化学习领域尚未得到充分的研究。
清华大学黄隆波团队提出了一种强化学习专用的动态稀疏训练框架,“Rigged Reinforcement Learning Lottery”(RLx2),可适用于多种离策略强化学习算法。它采用基于梯度的拓扑演化原则,能够完全基于稀疏网络训练稀疏深度强化学习模型。RLx2 引入了一种延迟多步差分目标机制,配合动态容量的回放缓冲区,实现了在稀疏模型中的稳健值学习和高效拓扑探索。
在多个 MuJoCo 基准任务中,RLx2 达到了最先进的稀疏训练性能,显示出 7.5 倍至 20 倍的模型压缩,而仅有不到 3% 的性能降低,并且在训练和推理中分别减少了高达 20 倍和 50 倍的浮点运算数。

论文链接:
https://arxiv.org/abs/2205.15043
代码链接:
https://github.com/tyq1024/RLx2

背景
在游戏、机器人技术等领域,深度强化学习(DRL)已经取得了重要的应用。然而,深度强化学习模型的训练需要巨大的计算资源。例如,DeepMind 开发的 AlphaGo-Zero 在围棋游戏中击败了已有的围棋 AI 和人类专家,但需要在四个 TPU 上进行 40 多天的训练。OpenAI-Five 是 OpenAI 开发的 Dota2 AI,同样击败了人类半职业 Dota 高手,但是需要高达 256 个 GPU 进行 180 天的训练。
实际上,即使是简单的 Rainbow DQN [Hessel et al. 2018] 算法,也需要在单个 GPU 上训练约一周时间才能达到较好的性能。

▲ 图:基于强化学习的 AlphaGo-Zero 在围棋游戏中击败了已有的围棋 AI 和人类专家
高昂的资源消耗限制了深度强化学习在资源受限设备上的训练和部署。为了解决这一问题,作者引入了稀疏神经网络。稀疏神经网络最初在深度监督学习中提出,展示出了对深度强化学习模型压缩和训练加速的巨大潜力。在深度监督学习中,SET [Mocanu et al. 2018] 和 RigL [Evci et al. 2020] 等常用的基于网络结构演化的动态稀疏训练(Dynamic sparse training - DST)框架可以从头开始训练一个 90% 稀疏的神经网络,而不会出现性能下降。
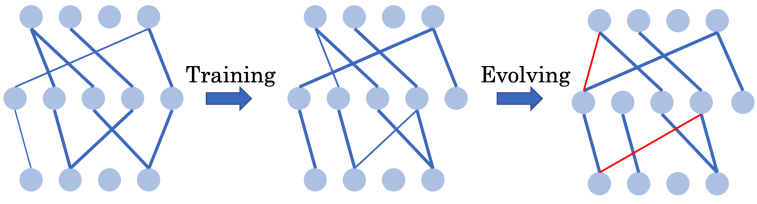
▲ 图:SET和RigL等常用的稀疏训练框架会在训练的过程中周期性地调整神经网络结构
在深度强化学习领域,已有的工作已经成功生成了极度稀疏的深度强化学习网络。然而,他们的方法仍然需要迭代地训练稠密网络,往往需要预训练的稠密模型作为基础,导致深度强化学习的训练成本仍然过高,无法直接应用于资源有限设备。
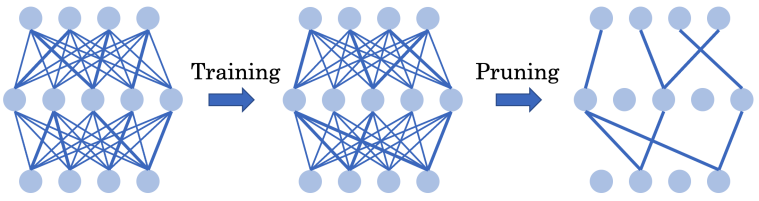
▲ 图:迭代剪枝通过迭代地训练稠密网络得到稀疏的深度强化学习网络
从头开始训练一个稀疏深度强化学习模型,如果能够完美实现,将极大地减少计算开销,并实现在资源受限设备上的高效部署,具备优秀的模型适应性。然而,在深度强化学习中从头开始训练一个超稀疏网络(例如 90% 的稀疏度)具有挑战性,原因在于自举训练(Bootstrap training)的非稳定性。
在深度强化学习中,学习目标不是固定的,而是以自举方式给出,训练数据的分布也可能是非稳定的。此外,使用稀疏网络结构意味着在一个较小的假设空间中搜索,这进一步降低了学习目标的置信度。因此,不当的稀疏化可能对学习路径造成不可逆的伤害,导致性能较差。最近的研究 [Sokar et al. 2021] 表明,在深度强化学习中直接采用动态稀疏训练框架仍然无法在不同环境中实现模型的良好压缩。因此,这一重要的开放问题仍然悬而未决:
能否通过全程使用超稀疏网络从头训练出高效的深度强化学习智能体?

方法
清华大学黄隆波团队对这一问题给出了肯定的答案,并提出了一种强化学习专用的动态稀疏训练框架,“Rigged Reinforcement Learning Lottery”(RLx2),用于离策略强化学习(Off-policy RL)。这是第一个在深度强化学习领域以 90% 以上稀疏度进行全程稀疏训练,并且仅有微小性能损失的算法框架。
RLx2 受到了在监督学习中基于梯度的拓扑演化的动态稀疏训练方法 RigL [Evci et al. 2020] 的启发。然而,直接应用 RigL 无法实现高稀疏度,因为稀疏的深度强化学习模型由于假设空间有限而导致价值估计不可靠,进而干扰了网络结构的拓扑演化。
因此,RLx2 引入了延迟多步差分目标(Delayed multi-step TD target)机制和动态容量回放缓冲区(Dynamic capacity buffer),以实现稳健的价值学习(Value learning)。这两个新组件解决了稀疏拓扑下的价值估计问题,并与基于 RigL 的拓扑演化准则一起实现了出色的稀疏训练性能。为了阐明设计 RLx2 的动机,作者以一个简单的 MuJoCo 控制任务 InvertedPendulum-v2 为例,对四种使用不同价值学习和网络拓扑更新方案的稀疏训练方法进行了比较。
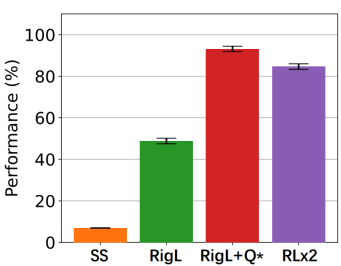
▲ 图:不同网络结构更新方案的性能比较。其中,SS 表示采用静态稀疏网络,RigL 表示使用基于梯度的网络拓扑演化的方法,RigL+Q * 表示使用 RigL 的拓扑演化且采用真实值函数引导自举训练的方法(真实值函数在实际算法中并不可知),RLx2 表示使用 RigL 网络拓扑演化且采用作者所提值估引导自举训练的方法。可以发现,RLx2 的性能已经非常逼近 RigL+Q * 的方法。
下图展示了 RLx2 算法的主要部分,包括基于梯度的拓扑演化、延迟多步差分目标和动态容量回放缓冲区。
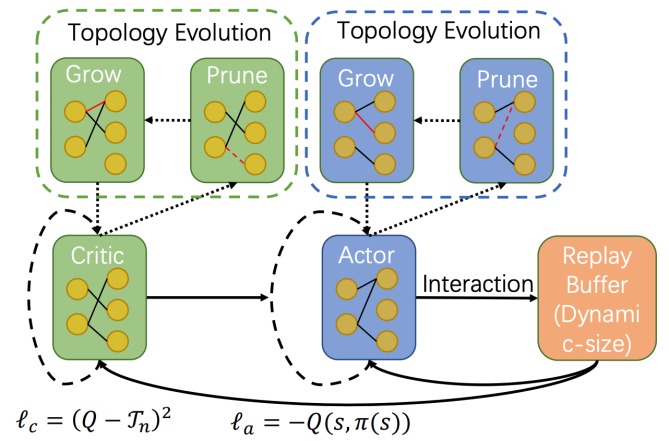
▲ RLx2 算法的概览
基于梯度的拓扑演化
在 RLx2 中,作者采用了与 RigL [Evci et al. 2020] 相同的方法来进行拓扑结构的演化。作者计算了损失函数对网络权重的梯度值。然后,周期性地增加稀疏网络中具有较大梯度的连接,并移除权重绝对值最小的现有连接。通过周期性的结构演化,获得了一个结构合理的稀疏神经网络。
延迟多步差分目标
RLx2 框架还引入了多步差分目标:
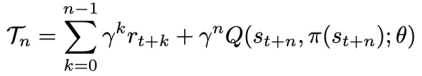
这一概念在现有研究中 [Munos et al. 2016] 已被证实能够改善差分学习(TD learning)。作者还发现,引入多步目标可以通过折扣因子减少稀疏网络的拟合误差,如下式所示:

然而,训练伊始立即采用多步差分目标可能会导致更大的策略不一致误差。因此,作者额外采用了延迟方案来抑制策略不一致性并进一步提高值函数的学习效果。
动态容量回放缓冲区
离策略(Off-policy)算法使用回放缓冲区(Replay buffer)来存储收集到的数据,并使用从缓冲区中抽样的批次数据来训练网络。研究表明 [Fedus et al. 2020],当使用更大的回放容量时,算法的性能通常会提高。然而,无限大小的回放缓冲区会因为多步目标的不一致性和训练数据的不匹配导致策略不一致性。动态容量回放缓冲区是一种通过调整缓冲区容量控制缓冲区中数据的不一致性,以实现稳健值函数学习的方法。
作者引入了以下策略距离度量来评估缓冲区中数据的不一致性:
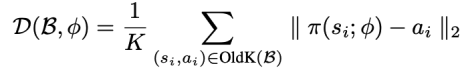
随着训练的进行,当回放缓存中的策略距离度量大于阈值时,则停止增加缓冲区容量,使得策略距离度量始终小于设定的阈值。

实验
作者在四个 MuJoCo 环境(HalfCheetah-v3、Hopper-v3、Walker2d-v3 和 Ant-v3),和两个常见的深度强化学习算法 TD3 和 SAC 中进行了实验。作者定义了一个终极压缩比率,即在该比率下,RLx2 的性能下降在原始稠密模型的 ±3% 之内。这也可以理解为具有与原始稠密模型完全相同性能的稀疏模型的最小大小。根据终极压缩比率,作者在下表中呈现了不同算法在不同环境采用相同参数量的神经网络的性能。
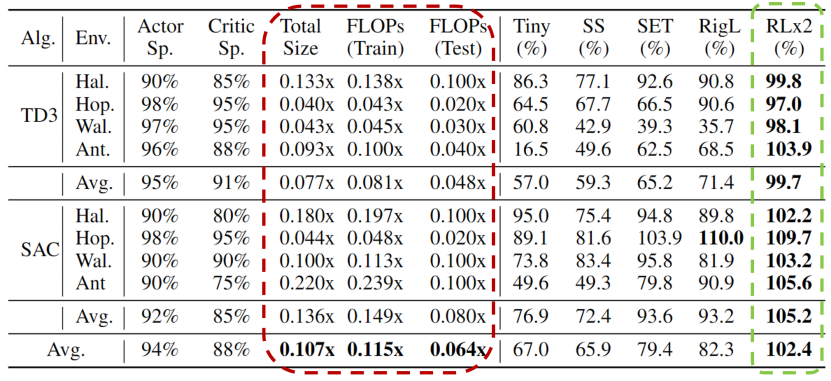
性能:在所有四个环境中,RLx2 的性能在很大程度上优于所有基准算法(除了 Hopper 环境中与 RigL 和 SAC 的性能相近)。此外,小型稠密网络(Tiny)和随机静态稀疏网络(SS)的性能平均最差。SET 和 RigL 的性能较好,但在 Walker2d-v3 和 Ant-v3 环境中无法保持性能,这意味着在稀疏训练下稳健的价值学习是必要的。
模型压缩:RLx2 实现了优秀的压缩比,并且仅有轻微的性能下降(不到 3%)。具体而言,使用 TD3 算法的 RLx2 实现了 7.5 倍至 25 倍的模型压缩,在 Hopper-v3 环境中获得了最佳的 25 倍压缩比。在每个环境中,演员网络(Actor network)可以压缩超过 96% 的参数,评论家网络(Critic network)可以压缩 85% 至 95% 的参数。SAC 算法的结果类似。另外,使用 SAC 算法的 RLx2 实现了 5 倍至 20 倍的模型压缩。
节省训练开销:与基于知识蒸馏或行为克隆的方法 [Vischer et al. 2021] 不同,RLx2 在整个训练过程中使用了稀疏网络。因此,它具有加速训练并节省计算资源的额外潜力。四个环境的平均结果表明,表格中 RLx2-TD3 分别减少了 12 倍和 20 倍的训练和推理浮点运算数,RLx2-SAC 分别减少了 7 倍和 12 倍的训练和推理浮点运算数。

总结
作者提出了一种用于离策略强化学习的稀疏训练框架 RLx2,能够适用于各种离策略强化学习算法。这一框架利用基于梯度的结构演化方法实现了高效的拓扑探索,并通过延迟多步差分目标和动态容量回放缓冲区建立了稳健的值函数学习。RLx2 不需要像传统剪枝方法一样预训练稠密网络,却能够在训练过程中使用超稀疏网络来训练高效的深度强化学习智能体,并且几乎没有性能损失。
作者在使用 TD3 和 SAC 的 RLx2 上进行了实验,结果表明其稀疏训练性能非常出色:模型压缩比例为 7.5 倍至 20 倍,性能下降不到 3%,训练和推理的浮点运算数分别减少高达 20 倍和 50 倍。作者认为未来有趣的工作包括将 RLx2 框架扩展到更复杂的 RL 场景,这些场景对计算资源的需求更高,例如多智能体、离线强化学习等场景,也包括真实世界的复杂决策问题而非标准的 MuJoCo 环境。

参考文献
1. Hessel, Matteo, et al. "Rainbow: Combining improvements in deep reinforcement learning." Proceedings of the AAAI conference on artificial intelligence. Vol. 32. No. 1. 2018.
2. Mocanu, Decebal Constantin, et al. "Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science." Nature communications 9.1 (2018): 2383.
3. Evci, Utku, et al. "Rigging the lottery: Making all tickets winners." International Conference on Machine Learning. PMLR, 2020.
4. Sokar, Ghada, et al. "Dynamic sparse training for deep reinforcement learning." arXiv preprint arXiv:2106.04217 (2021).
5. Munos, Rémi, et al. "Safe and efficient off-policy reinforcement learning." Advances in neural information processing systems 29 (2016).
6. Fedus, William, et al. "Revisiting fundamentals of experience replay." International Conference on Machine Learning. PMLR, 2020.
7. Vischer, Marc Aurel, Robert Tjarko Lange, and Henning Sprekeler. "On lottery tickets and minimal task representations in deep reinforcement learning." arXiv preprint arXiv:2105.01648 (2021).
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·

这篇关于ICLR 2023|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







