开销专题

C++高效内存池实现减少动态分配开销的解决方案
《C++高效内存池实现减少动态分配开销的解决方案》C++动态内存分配存在系统调用开销、碎片化和锁竞争等性能问题,内存池通过预分配、分块管理和缓存复用解决这些问题,下面就来了解一下... 目录一、C++内存分配的性能挑战二、内存池技术的核心原理三、主流内存池实现:TCMalloc与Jemalloc1. TCM
[译]探索Kotlin中隐藏的性能开销-Part 2
翻译说明: 原标题: Exploring Kotlin’s hidden costs — Part 2 原文地址: https://medium.com/@BladeCoder/exploring-kotlins-hidden-costs-part-2-324a4a50b70 原文作者: Christophe Beyls 这是关于探索Kotlin中隐藏的性能开销的第2部分,如果你还没有看到
![[译]探索Kotlin中隐藏的性能开销-Part 1](https://i-blog.csdnimg.cn/blog_migrate/9defb64cd886ef030a8cdca07ccd91b6.png)
[译]探索Kotlin中隐藏的性能开销-Part 1
翻译说明: 原标题: Exploring Kotlin’s hidden costs — Part 1 原文地址: https://medium.com/@BladeCoder/exploring-kotlins-hidden-costs-part-1-fbb9935d9b62 原文作者: Christophe Beyls 在2016年,Jake Wharton大神就Java中隐藏性能开销

多进程比多线程开销大的原因
多进程比多线程开销大的原因主要可以归结为以下几个方面: 资源分配与回收 内存与地址空间:每个进程都拥有独立的内存空间和地址空间,这意味着在创建进程时,操作系统需要为其分配独立的资源,如内存空间、文件描述符等。相比之下,线程是共享进程的资源,包括内存和文件描述符等,因此在资源分配上更为“节俭”。 资源回收:当进程结束时,操作系统需要回收其占用的所有资源,这包括内存、文件描述符等,而线程结束时则不需
【杂记-浅谈如何根据优先级、开销值、子网掩码进行路由选择】
如何根据优先级、开销值、子网掩码进行路由选择 一、路由选择概述二、路由选择参考的要素1、优先级2、开销值3、子网掩码长度 三、路由选择过程1、子网掩码长度匹配2、优先级选择3、开销值对比 一、路由选择概述 路由选择的合理性直接影响到网络的性能和稳定性,路由选择通常依赖于路由表,路由表中包含了各种路由信息,如优先级、开销值和子网掩码长度等属性,这些属性共同决定了路由的选择和数据包

06|容器CPU(2):如何正确地拿到容器CPU的开销?
无论是容器的所有者还是容器平台的管理者,我们想要精准的对运行着众多容器的云平台做监控,快速排查例如应用的处理能力下降,节点负载过高等问题,就绕不开容器CPU开销。CPU开销的异常,往往是程序异常最明显的一个指标。 一、问题重现 容器中运行top,"%Cpu(s)"那一行中显示的数值,并不是这个容器的 CPU 整体使用率,而是容器宿主机的 CPU 使用率。 1.1、进程 CPU 使用率
利用Redis队列,如果需要处理大量的消息并且希望避免轮询的开销,使用BLPOP或BRPOP,Java代码实现
当使用Redis来处理大量的消息并希望避免轮询的开销时,确实可以使用BLPOP或BRPOP命令。在Java中,你可以通过Jedis库或者Spring Data Redis的RedisConnection来执行这些命令。以下是一个使用Jedis的示例代码: 首先,确保你已经添加了Jedis的依赖到你的项目中。如果使用Maven,可以在pom.xml中添加如下依赖: xml 复制

学习笔记——路由网络基础——等开销负载均衡
3、等开销负载均衡 等开销负载均衡:到达同一目标网段,存在多条路由条目,存在两条或两条以上的路由优先级值和开销值都是最优的(优先级值和开销值一致),则这几条路径执行负载均衡(在ping中就是这条路由发个包再下一条路由再发个包,轮流发) 问题:假如上图的两条路由的速度为1000Mbps和100Mbps的话,由于负载均衡(两条路由轮流输送数据)会导致最高的数据传输效率也
ZNS SSD+F2FS文件系统|如何降低GC开销?--2
在F2FS(Flash-Friendly File System)中,Over-provisioning,OP配置是一种优化策略,旨在通过预留一部分存储空间不分配给用户使用,以提升文件系统的性能、耐用性和可靠性。在F2FS与ZNS SSD的结合中,OP策略得到了进一步优化。由于ZNS SSD具有固定的区域(zone)大小和顺序写入特性,F2FS能够更加精确地管理OP配置空间,以适应ZNS特有的存储

MoonBit 本周有超多重磅更新:零开销迭代,动态数组模式匹配完美支持
MoonBit更新 标准库里添加了 Iter 类型,该类型可以高效地对容器中的元素的进行访问,并且将访问过程优化成循环,使用方式比如: test "iter" {let sum = Iter::[1, 2, 3, 4, 5, 6].filter(fn { x => x % 2 == 1 }).take(2).map(fn { x => x * x}).reduce(fn (x, y) { x

代理IP在爬虫中的连接复用与开销减少
目录 一、引言 二、代理IP的基本概念 三、代理IP在爬虫中的使用 四、代理IP的连接复用 五、减少开销的策略 六、代码示例与注释 七、总结 一、引言 在爬虫开发中,代理IP的使用是常见的做法,尤其在目标网站设置了反爬虫机制时。代理IP能够帮助爬虫绕过IP封锁,提升爬取效率。然而,频繁更换代理IP也会带来额外的开销,如连接建立时间、代理服务器费用等。因此,如何在爬虫中有效
js中的arguments的时间开销
console.time('start');function a() {var a1=arguments[0],b1=arguments[1],c1=arguments[2],d1=arguments[3],e1=arguments[4];}function b(a,b,c,d,e) {var a1=a,b1=b,c1=c,d1=d,e1=e;}for (var i=0; i<1000
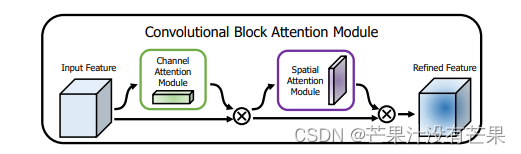
免费阅读篇 | 芒果YOLOv8改进111:注意力机制CBAM:轻量级卷积块注意力模块,无缝集成到任何CNN架构中,开销可以忽略不计
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可 该专栏完整目录链接: 芒果YOLOv8深度改进教程 该篇博客为免费阅读内容,YOLOv8+CBAM改进内容🚀🚀🚀 文章目录 1. CBAM 论文2. YOLOv8 核心代码改进部分2.1 核心新增代码2.2 修改部分 2.3 YOLOv8-CBAM 网络配置文件2.4 运行代码改
Final方法节省时间开销
[size=medium][color=indigo]1、final类: 可以用“final”声明一个类不可再被作为超类。 2、final方法: 当一个方法用“final”来修饰时,表示该方法不可以被子类重写。 好处: 一、限制了子类中对其改写; 二、提高了执行的效率,因为这种情况属于静态绑定,Java虚拟机(JVM)的即时编译器就不会去检索该方法在其父类、子类或爷爷类、孙子类等有
降低 Linux 内存开销
Linux 广受追捧的一个优点是它比 Microsoft® Windows® 的效率更高,因此在不太前沿的硬件上也能很好地执行。对于依然使用 Windows 98 时代的机器的人来说,最新最卓越的软件(特别是安全补丁)已经不再支持这些机器,因此这种性能优势使 Linux 成为颇具吸引力的升级产品。 然而,问题的真相在于虽然 Linux 内核仍然可以配置成合理的大小和效率,但由于新计算机的处理能力
使用内联函数,降低函数调用开销,实现移动时绘制
easyx devc++ 开发。 AWSD移动,移动时可以左键绘制 左键绘制 左上角画笔颜色 右键拖拽 #include <graphics.h>// 使用关键字 inline 声明为内联函数,减少贴图函数频繁调用的开销导致的卡顿。 // 缓冲区纹理映射函数:bkmesh 映射目标,map 映射总网格,pentable:纹理集,bkmeshmapi,bkmeshmapj:映射起始点

查询已取消,因为此查询的估计开销(363)超出了配置的阈值 300
1.问题 2.问题解决: 登录服务器的SQL Server > 右键单击服务器并选择“属性”>选择“链接页”==>取消勾选
Avoiding Image Decompression Sickness如何避免图像解压缩的时间开销
转自:http://longtimenoc.com/archives/ios%E5%A6%82%E4%BD%95%E9%81%BF%E5%85%8D%E5%9B%BE%E5%83%8F%E8%A7%A3%E5%8E%8B%E7%BC%A9%E7%9A%84%E6%97%B6%E9%97%B4%E5%BC%80%E9%94%80#more-722 转载请注明! 这是一篇译文,(原文"Av

IS-IS:05 ISIS开销值和协议优先级
IS-IS 协议为路由器的每个 IS-IS 接口定义并维护了一个 level-1 开销值和一个 level-2开销值。开销值可以在接口上或者全局上手动配置,也可以使用 auto-cost自动计算确定。 修改接口cost: int g0/0/0isis cost 50 修改全局cost: isiscircuit-cost 30 修改参考带宽: isisbandwi
Twitter:使用Netty 4来减少GC开销
在twitter,需要网络功能的核心模块使用的都是Netty。 比方说: [list] [*]- [url=http://twitter.github.io/finagle/]Finagle[/url]是我们的协议无关的RPC系统,它的传输层是在Netty之上构建的,许多内部的服务都是通过它来实现的,比如说搜索服务。 [*]- TFE(Twitter Front End,Twitter
巧妙的设计stl中的比较函数,以避免不必要的cpu开销
在stl algorithm.h中,常利用一些排序操作,比如通过vector实现一个堆。如果堆的每个元素是自定义结构,也就是,自己实现的类作为堆的基本元素,那么make_heap和push_heap,pop_heap就需要开发者提供自己的比较函数。bool __cmp(value &v1 ,value & v2).在stl的内部实现中,当这个_cmp判定为true时,就需要调整heap,所

Open judge 06月度开销
06:月度开销 总时间限制: 1000ms 内存限制: 65536kB 传送门 描述 农夫约翰是一个精明的会计师。他意识到自己可能没有足够的钱来维持农场的运转了。他计算出并记录下了接下来 N (1 ≤ N ≤ 100,000) 天里每天需要的开销。约翰打算为连续的M (1 ≤ M ≤ N) 个财政周期创建预算案,他把一个财政周期命名为fajo月。每个fajo月包含一天或连续的多天,每天被

ICLR 2023|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架
©作者 | 机器之心编辑部 来源 | 机器之心 大模型时代,模型压缩和加速显得尤为重要。传统监督学习可通过稀疏神经网络实现模型压缩和加速,那么同样需要大量计算开销的强化学习任务可以基于稀疏网络进行训练吗?本文提出了一种强化学习专用稀疏训练框架,可以节省至多 95% 的训练开销。 深度强化学习模型的训练通常需要很高的计算成本,因此对深度强化学习模型进行稀疏化处理具有加快训练速度和拓展模型部署的巨

【双点双向-OSPF-ISIS(3)】(开销导致的环路问题)
目录 一、拓扑图 二、引入路由 1.R2单点双向 2.R3配置ospf->isis以及isis->ospf 分析: 三、更改拓扑(大坑图:开销问题导致的环路) 1.改动:在双点双向之后,修改cost,引入直连1.1路由。 2.【次优路径】用路由策略将1.1路由精确引入 假设:引入后直连1.1后,R2先将ospf外部路由1.1引入到isis区域 1)出现1.1路由的次优路径

深入分析高性能互连点对点通信开销
今天分享最近阅读的一篇文章:“Breaking Band,A Breakdown of High-Performance Communication”,这篇文章发表在ICPP 2019会议。由加州大学欧文分校和ARM公司合作完成。从题目中可以看到,这篇文章是一篇评测型的文章,它主要对高性能网络点对点通信中的各部分开销进行了比较详细的分析。本文将首先介绍论文的研究背景与论文最核心的贡献,以及本文