提出专题

超越IP-Adapter!阿里提出UniPortrait,可通过文本定制生成高保真的单人或多人图像。
阿里提出UniPortrait,能根据用户提供的文本描述,快速生成既忠实于原图又能灵活调整的个性化人像,用户甚至可以通过简单的句子来描述多个不同的人物,而不需要一一指定每个人的位置。这种设计大大简化了用户的操作,提升了个性化生成的效率和效果。 UniPortrait以统一的方式定制单 ID 和多 ID 图像,提供高保真身份保存、广泛的面部可编辑性、自由格式的文本描述,并且无需预先确定的布局。

生成式AI让你提出高智商问题,让你看起来超聪明
你可以使用生成式AI来提出极其聪明的问题,这些问题对于各种目的和意图都非常有用。 你想表现得聪明绝顶吗? 我相信大多数人都想。 如果你不熟悉“聪明绝顶”这个词,它在1997年的电影《心灵捕手》中流行起来,当时本·阿弗莱克的角色说他的朋友聪明绝顶,这是一种波士顿人常用的表达,表示某人非常聪明。这个地方性俚语从那时起就被广泛使用,并且非常朗朗上口。 让一个人看起来特别聪明的方式之一就是通过他们

自动驾驶真正踏出迈向“用户”的第一步:IROS24新SOTA提出个性化的实例迁移模仿学习
导读: 本文针对自动驾驶规划任务,提出了一种基于实例的迁移模仿学习方法,通过预先训练的微调框架从专家域迁移专业知识,以解决用户域数据稀缺问题。实验结果显示,该方法能有效捕捉用户驾驶风格并实现具有竞争力的规划性能,但仍需开发合适的用户风格测量方法。©️【深蓝AI】编译 1. 摘要 个性化运动规划在自动驾驶领域中具有重要意义,可以满足个人用户的独特需求。然而,以往的工作在同时解决两个关键问题

谷歌提出新型半监督方法 MixMatch
事实证明,半监督学习可以很好地利用无标注数据,从而减轻对大型标注数据集的依赖。而谷歌的一项研究将当前主流的半监督学习方法统一起来,得到了一种新算法 MixMatch。该算法可以为数据增强得到的无标注样本估计(guess)低熵标签,并利用 MixUp 来混合标注和无标注数据。实验表明,MixMatch 在许多数据集和标注数据上获得了 STOA 结果,展现出巨大优势。例如,在具有 250

每日AIGC最新进展(54):中科大提出Pose引导的图像生成模型、韩国科技学院提出发型控制模型、北大提出风格生成数据集CSGO
Diffusion Models专栏文章汇总:入门与实战 GRPose: Learning Graph Relations for Human Image Generation with Pose Priors 在过去的研究中,基于扩散模型的人工生成技术在根据特定条件合成高质量人像方面取得了显著进展。然而,尽管之前的方案引入了姿势先验,现有方法仍然在高质量图像生成和稳定的姿势对齐上存
总结GRE作文四种问题及提出几条建议
在GRE考试的备战过程中,有不少考生咨询自己的新GRE写作为什么不能写好,很多同学看完每年的满分作文再对照自己写的都有挫败感,不明白为什么人家的新GRE作文能写那么好而自己的却又这么多问题。针对这个问题总结出考生的作文四种问题及提出几条建议。 1.例证匮乏,老生常谈 并不是这些例证不恰当或不足以说明问题,而是如果每一位GRE考生都把爱迪生发明电灯作为例证,都引用爱因斯坦所说的成功是

中山大学和联想研究院提出文本到服装生成模型GarmentAligner,解决服装生成中语义对齐、数量、位置和相互关系等问题。
中山大学和联想研究院提出一个能够根据文字描述生成服装图像的智能工具GarmentAligner。它可以从已有服装图像中提取出各个组成部分,并记录下它们的位置和数量。接着根据你的描述进行匹配,找出最吻合的服装组件进行组合。而为了确保生成的图像能够准确反映描述,不仅仅是看上去好看,还可以在细节上做到精准对齐。通过这种方法,GarmentAligner可以在时尚设计的过程中给你提供更多灵感和帮助!
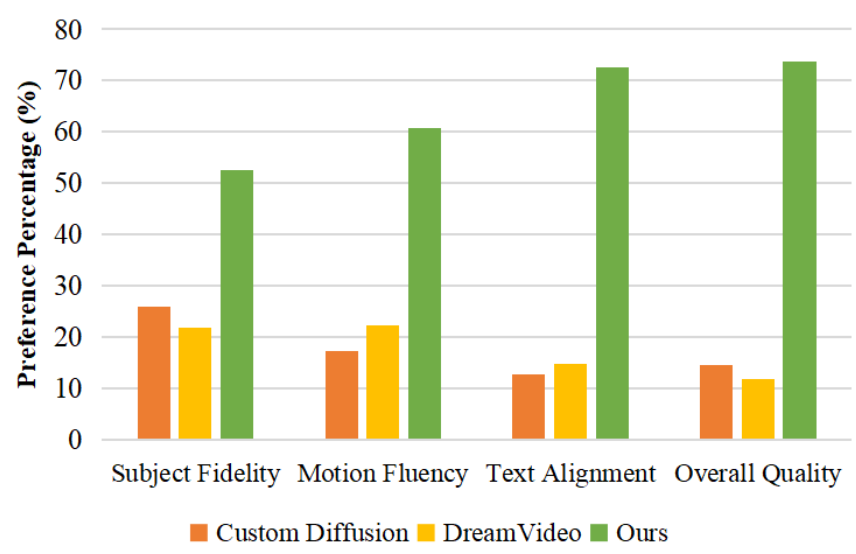
腾讯浙大提出定制化视频生成框架CustomCrafter,只需通过少量图像就可以完成高质量视频生成!
腾讯联合浙大提出了一种定制化视频生成框架-CustomCrafter,它能够基于文本提示和参考图像生成自定义视频,同时保留运动生成和概念组合的能力。通过设计一系列灵活的模块,使得模型实现了无需额外视频,通过少量图像学习,就能生成高质量的个性化视频。 上图为 CustomCrafter 可视化结果。CustomCrafter允许自定义主体身份和运动模式 通过保留运动生成和概念组合能力来生成带有

ECCV2024|港中文提出文本生成3D方法DreamDissector,能够生成具有交互的多个独立对象。
DreamDissector 是一种文本生成3D对象的方法,通过将多对象文本生成的NeRF输入并生成独立的纹理网格,提供了对象级别的控制和多种应用可能性。 DreamDissector 可以生成具有合理交互的多个独立纹理网格,方便各种应用,包括对象级别的文本引导纹理、通过简单操作方便的手动用户几何编辑以及文本引导的可控对象替换。 相关链接 论文地址:https://a

中国矿业大学(北京)孙灏老师课题组在遥感学科顶刊RSE上发文,率先提出30m分辨率植被干旱遥感综合监测模型
《Remote Sensing of Environment》高空间分辨率干旱响应指数(HiDRI):基于遥感、深度学习和时空融合的植被干旱监测一体化框架 第一作者:徐振恒 通讯作者:孙灏 该项研究首次构建30m分辨率植被干旱遥感综合监测模型,突破了国内外现有植被干旱遥感综合监测模型公里级空间分辨率的约束,为农田、矿区等局域尺度植被干旱监测提供了有力工具。 介绍

【C/C++】我自己提出的数组探针的概念,快来围观吧
数组探针 在许多编程语言中如果涉及到数组那么就可以使用这个东西,便于遍历数组 中文名 数组探针 外文名 arrProbe 适用领域 大数据 所属学科 软件技术、编程 提出者 董翔 目录 1 概述2 工作原理3 应用场景 ▪ 数据处理和分析▪ 图像处理▪ 游戏开发▪ 模拟和建模 4 示例代码5 总结 概述 数组探针(Array Probe)是一个编程中常
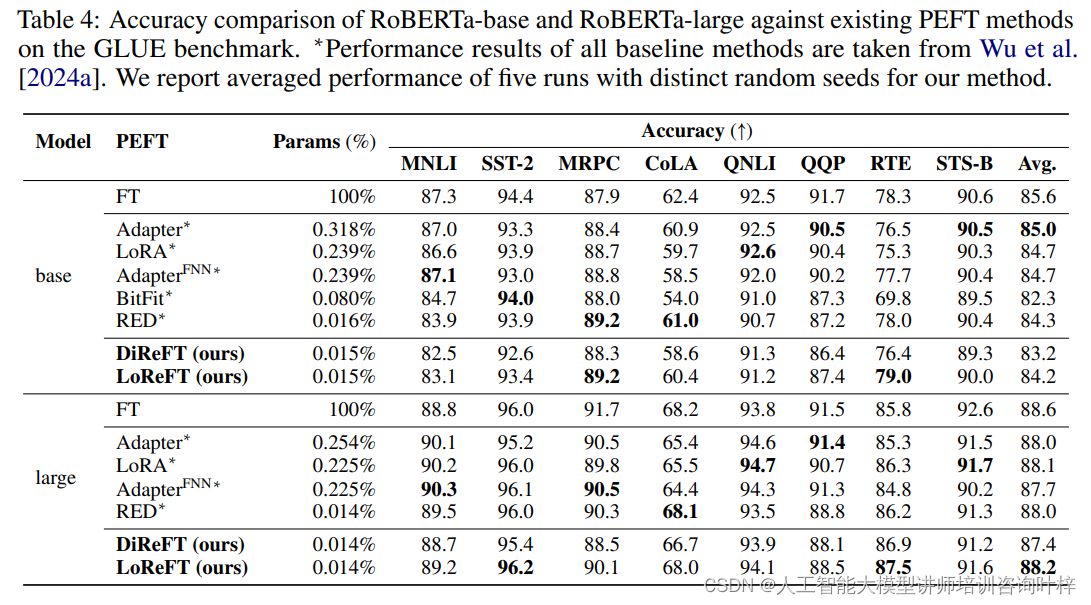
ReF:斯坦福提出的新型语言模型微调方法
随着预训练语言模型(LMs)在各种自然语言处理(NLP)任务中的广泛应用,模型微调成为了一个重要的研究方向。传统的全参数微调方法虽然有效,但计算成本高昂,尤其是在大型模型上。为了解决这一问题,来自斯坦福大学和 Pr(Ai)⊃2;R Group 的研究团队推出一种全新的微调方法——表征微调(ReFT)。ReFT方法的核心优势在于,它不直接对模型权重进行更新,而是通过学习对隐藏层表征的特定干预来适应下

超高清图像生成新SOTA!清华唐杰教授团队提出Inf-DiT:生成4096图像比UNet节省5倍内存。
清华大学唐杰教授团队最近在生成超高清图像方面的新工作:Inf-DiT,通过提出一种单向块注意力机制,能够在推理过程中自适应调整内存开销并处理全局依赖关系。基于此模块,该模型采用了 DiT 结构进行上采样,并开发了一种能够上采样各种形状和分辨率的无限超分辨率模型。与常用的 UNet 结构相比,Inf-DiT 在生成 4096×4096 图像时可以节省超过 5 倍的内存。该模型在机器和人类评估中均实现
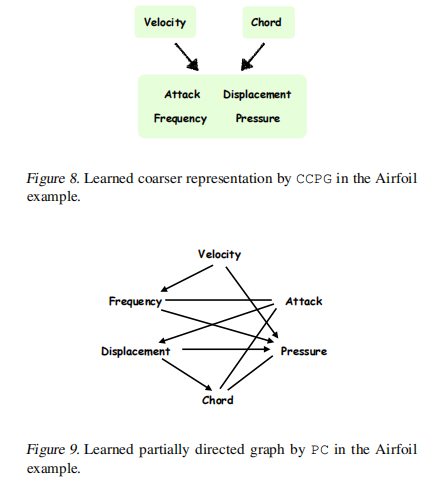
ICML24麻省理工提出使用更少的条件独立性测试来发现因果关系新方法
【摘要】众多科学领域的核心问题围绕着理解因果关系这一基本问题。然而,大多数基于约束的因果发现算法,包括广受欢迎的PC算法,通常会进行指数级数量的条件独立性(CI)测试,在各种应用中造成局限。为解决这一问题,我们的工作重点是表征在减少CI测试数量的情况下,可以了解潜在因果图的哪些信息。我们证明,学习一个隐藏因果图的更粗糙表示只需多项式数量的测试。该更粗糙表示,称为因果一致分区图(CCPG),包括

人大高瓴/腾讯提出QAGCF:用于QA推荐的图形协同过滤
【摘要】问答(Q&A)平台通常推荐问答对来满足用户的知识获取需求,这与仅推荐单个项目的传统推荐不同。这使得用户行为更加复杂,并为Q&A推荐带来了两个挑战,包括:协作信息纠缠,即用户反馈受问题或答案的影响;以及语义信息纠缠,其中问题与其相应的答案相关联,不同问答对之间也存在相关性。传统的推荐方法将问答对视为一个整体或仅将答案视为单个项目,忽略了这两个挑战,无法有效地模拟用户兴趣。为了应对这些挑战
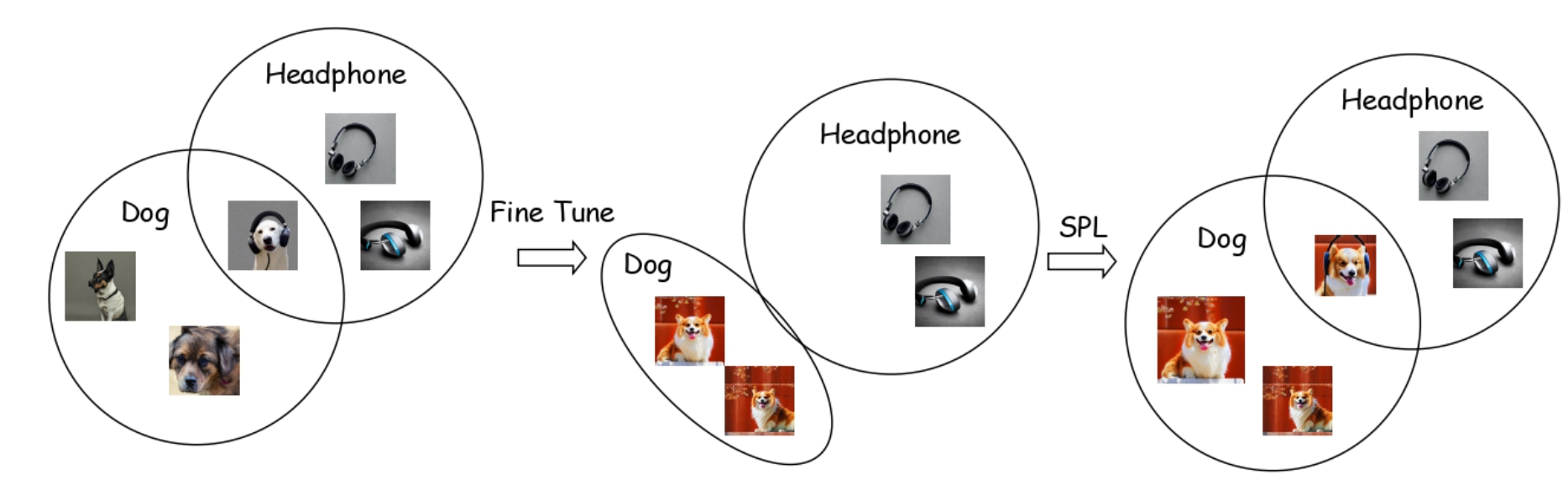
北交字节联合提出ClassDiffusion: 使用显式类别引导的一致性个性化生成。
在个性化生成领域, 微调可能会引起过拟合导致模型无法生成与提示词一致的结果。针对这个问题,北交&字节联合提出ClassDiffusion,来提升个性化生成的一致性。 通过两个重要观察及理论分析提出了新的观点:一致性的损失是个性化概念语义偏移导致的, 还引入了BLIP2-T 来为个性化生成领域提供更公平有效的指标。 一只狗和太阳镜的故事,展示了一只狗是如何获得诺贝尔文学奖的,以及一副太阳镜的
软件项目中如何处理用户提出的不合理需求
软件项目中经常出现用户提出不合理需求,这种情况如何处理呢?处理用户提出的不合理需求需要谨慎和策略,以确保用户的满意度与项目的可行性之间达到平衡。 我们可以尝试如下方法: 首先确保自己完全理解他们的立场和动机 耐心倾听和理解用户的需求,并确保自己完全理解他们的立场和动机。这有助于建立信任,并确保自己的回应是基于对需求的准确理解。 不合理需求经过沟通,变成了合理需求。 如果确认是不合理需求后

UniAnimate:华科提出人类跳舞视频生成新框架,支持合成一分钟高清视频
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。 针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 合集: 《大模型面试宝典》(2024版) 正式发布! 持续火爆!!!《AIGC 面试宝典》已圈粉无数! 人类跳舞视频生成是一项引人注目且具有挑战性的可控视频合成任务
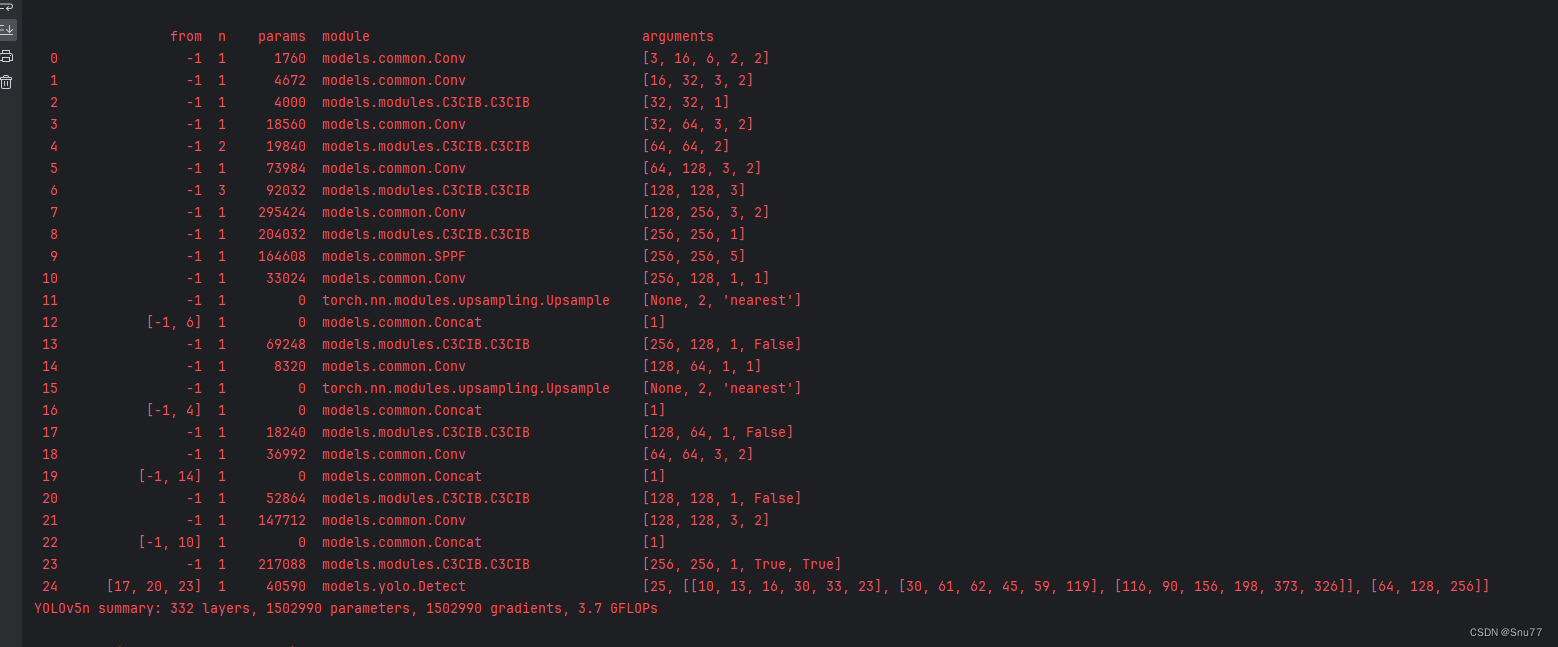
YOLOv5改进 | Conv篇 | 利用YOLOv10提出的UIB模块二次创新C3(附代码 + 完整修改教程)
一、本文介绍 本文给大家带来的改进机制是利用利用YOLOv10提出的UIB模块二次创新C3助力YOLOv5进行有效涨点,其中C2fUIB模块所用到的CIB模块是一种紧凑的倒置块结构,它采用廉价的深度卷积进行空间混合,并采用成本效益高的点卷积进行通道混合。本文针对该方法给出多种使用方法,大家可以根据自己的数据集来针对性的使用,同时本文附C3UIB网络结构图! 欢迎大家订阅我的专栏一起学习YOL

西湖大学提出AIGC检测框架,精准识别AI撰写的文稿
近年来人工智能技术突飞猛进,尤其是大语言模型的出现,让AI具备了创作文章、小说、剧本等内容的能力。 AI代写,已经逃不过老师、编辑、审稿人的火眼金睛了。但让AI仅改写部分片段,就安全了么? 针对检测AI改写的片段,西湖大学发布了一种叫做"篡改文本片段检测"(PTD)的新方法,它能精确识别文本中哪些片段是由AI生成或改写的,让AI改写的文本无处遁形! 传统的AI文本检测通常只能判断整篇文章是否

清华大学提出IFT对齐算法,打破SFT与RLHF局限性
监督微调(Supervised Fine-Tuning, SFT)和基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)是预训练后提升语言模型能力的两大基础流程,其目标是使模型更贴近人类的偏好和需求。 考虑到监督微调的有效性有限,以及RLHF构建数据和计算成本高昂,这两种方法常常被结合使用。但由于损失函数、数据格式的差异以及对
华为云IoT提出万物互联新范式,从万物感知到万物生长
万物互联,不仅仅是对物的感知,更重要的是让万物融入到智能世界。华为云IoT,以云为基础,从物的泛在联接、物的场景化孪生、物的智能协同三个维度,提出万物互联新范式,让万物生于端而长于云,将万物带入整个智能世界中。 从物联网字面意思看,就是要解决“物”的联接,华为云IoT基于60余种行业接入协议,沉淀出工业、交通、水利、环保等多种细分行业的设备协议库,同时以10种以上

上交提出TrustGAIN,提出6G网络中可信AIGC新模式!
月16日至18日,2024全球6G技术大会在南京召开。会上,全球移动通信标准制定组织3GPP(第三代合作伙伴计划)的3位联席主席分享了3GPP6G标准时间表: 2024年9月,启动6G业务需求研究; 2025年6月,启动6G技术预研; 2027年上半年,启动6G标准制定; 2029年,完成6G基础版本标准,即Rel-21版本标准。 6G时代的脚步已经越来越近,而我们当下如火如荼的AIGC

优于InstantID!中山大学提出ConsistentID:可以仅使用单个图像根据文本提示生成不同的个性化ID图像
给定一些输入ID的图像,ConsistentID可以仅使用单个图像根据文本提示生成不同的个性化ID图像。效果看起来也是非常不错。 相关链接 Code:https://github.com/JackAILab/ConsistentID Paper:https://ssugarwh.github.io/consistentid.github.io/arXiv.pdf Demo:ht
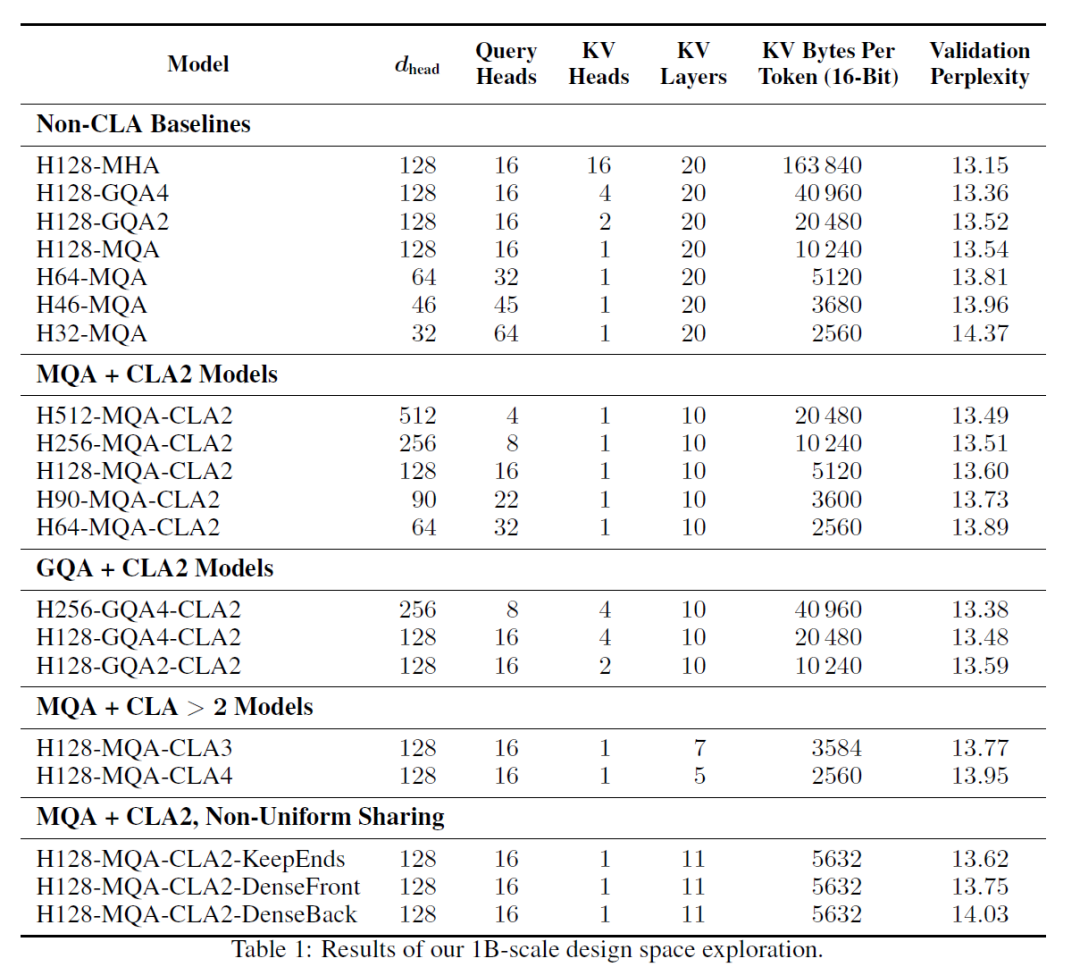
MIT提出基于Transformer的Cross-Layer Attention:江湖骗子还是奇思妙想
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于构建生产级别架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。 键值(KV)缓存对于加速基于Transformer的大型语言模型 (LLM)
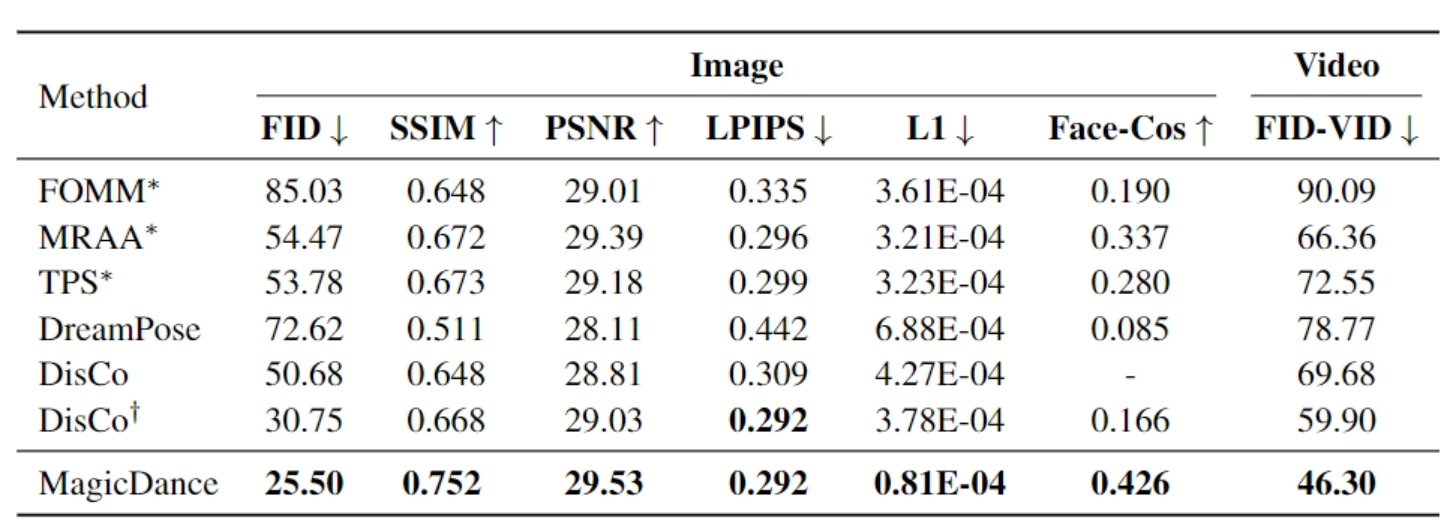
南加州大学字节提出MagicPose,提供逼真的人类视频生成,实现生动的运动和面部表情传输,以及不需要任何微调的一致的野外零镜头生成。
MagicPose可以精确地生成外观一致的结果,而原始的文本到图像模型(如Stable Diffusion和ControlNet)很难准确地保持主体身份信息。 此外,MagicPose模块可以被视为原始文本到图像模型的扩展/插件,而无需修改其预训练的权重。 相关链接 论文链接:https://arxiv.org/pdf/2311.12052.pdf 项目链接:https://githu