本文主要是介绍中山大学和联想研究院提出文本到服装生成模型GarmentAligner,解决服装生成中语义对齐、数量、位置和相互关系等问题。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
中山大学和联想研究院提出一个能够根据文字描述生成服装图像的智能工具GarmentAligner。它可以从已有服装图像中提取出各个组成部分,并记录下它们的位置和数量。接着根据你的描述进行匹配,找出最吻合的服装组件进行组合。而为了确保生成的图像能够准确反映描述,不仅仅是看上去好看,还可以在细节上做到精准对齐。通过这种方法,GarmentAligner可以在时尚设计的过程中给你提供更多灵感和帮助!

GarmentAligner能够生成高质量的服装图像,准确地描述提供说明中指定的组件的数量和空间对齐。
相关链接
http://arxiv.org/abs/2408.12352v1
论文阅读

GarmentAligner:通过检索增强多级校正实现文本到服装的生成
摘要
通用的文本转图像模型为艺术、设计和媒体领域带来了革命性的创新。然而,当应用于服装生成时,即使是最先进的文本转图像模型也存在细粒度语义错位,特别是在服装组件的数量、位置和相互关系方面。
为了解决这个问题,我们提出了 GarmentAligner,这是一个使用检索增强多级校正训练的文本转服装扩散模型。为了在组件级别实现语义对齐,我们引入了一个自动组件提取管道,以从相应的图像和标题中获取服装组件的空间和定量信息。随后,为了利用服装图像中的组件关系,我们通过基于组件级相似性排名的检索增强为每件服装构建检索子集,并进行对比学习以增强模型对正样本和负样本组件的感知。
为了进一步增强跨语义、空间和定量粒度的组件对齐,我们利用详细组件信息的多级校正损失。实验结果表明,与现有竞争对手相比,GarmentAligner 实现了更高的保真度和细粒度的语义对齐。
方法
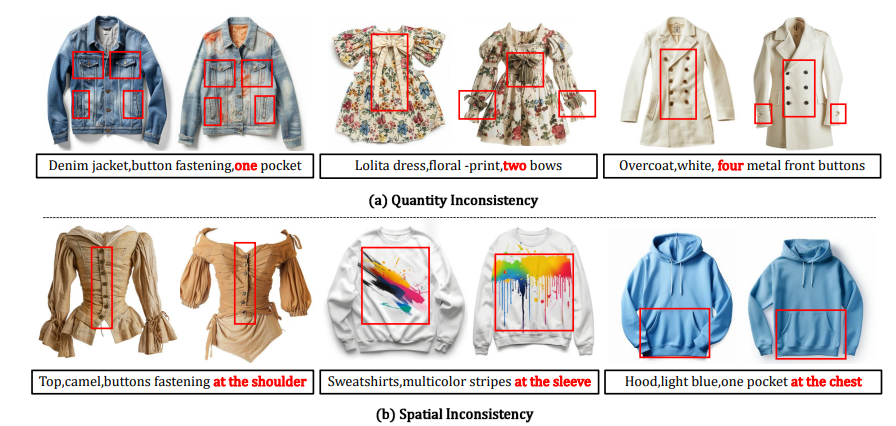
最先进的文本到图像模型Midjourney在文本到服装任务中的失败。这种错位主要归因于组件的数量和空间位置,因此很难生成符合预期的细粒度细节的服装。
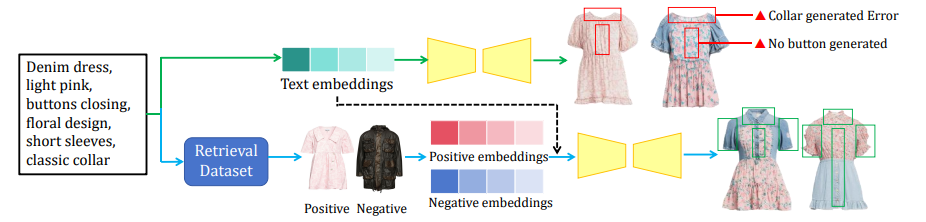
通过检索增强对比学习来解决不对齐的问题。通过吸收通过组件级相似性排序检索的正面和负面样本的见解,该模型增强了对组件关系的感知。
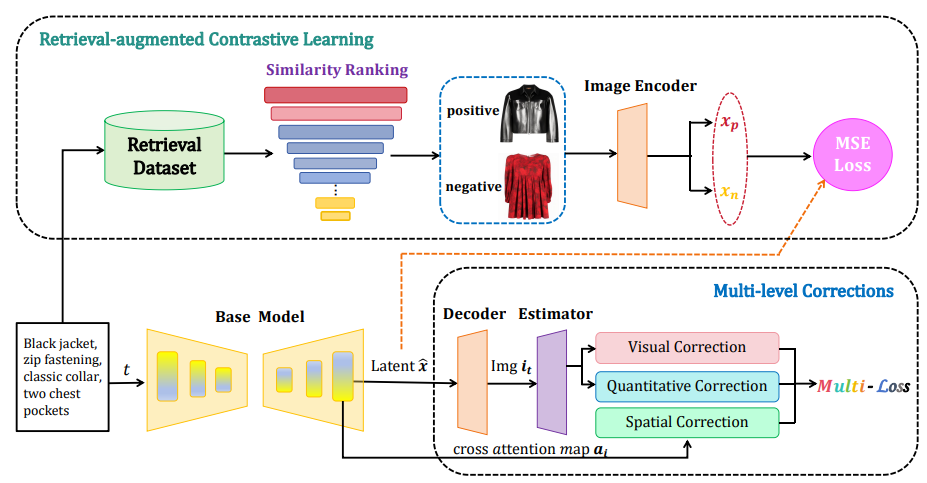
提出的 GarmentAligner 概述。在训练过程中,系统地构建检索样本,利用多级语义相似性排序进行对比学习,目的是实现全局感知对齐。同时,采用多个校正损失来细化视觉语义、空间位置和服装组件的数量,从而增强细节的粒度。
GarmentAligner 的主要目标是在整体感知和细粒度语义的多个语义层面上增强输入文本提示和生成的服装图像之间的对齐。为了实现这一目标,GarmentAligner 集成了预训练的潜在扩散模型作为主干,以利用其固有知识,并使用检索增强的多级校正对预训练的文本到图像主干进行微调,以使其适应文本到服装生成领域。此外,采用自动组件提取流程,通过先进的开放域检测和分割方法从服装图像中获得深入的组件级信息。

提出的检索增强对比学习的例证。基于组件级语义相似性排序,在包含n个样本的随机选择子集中执行每个样本的检索。随后,对检索结果进行全局评估过滤,获得正样本和负样本进行对比学习。
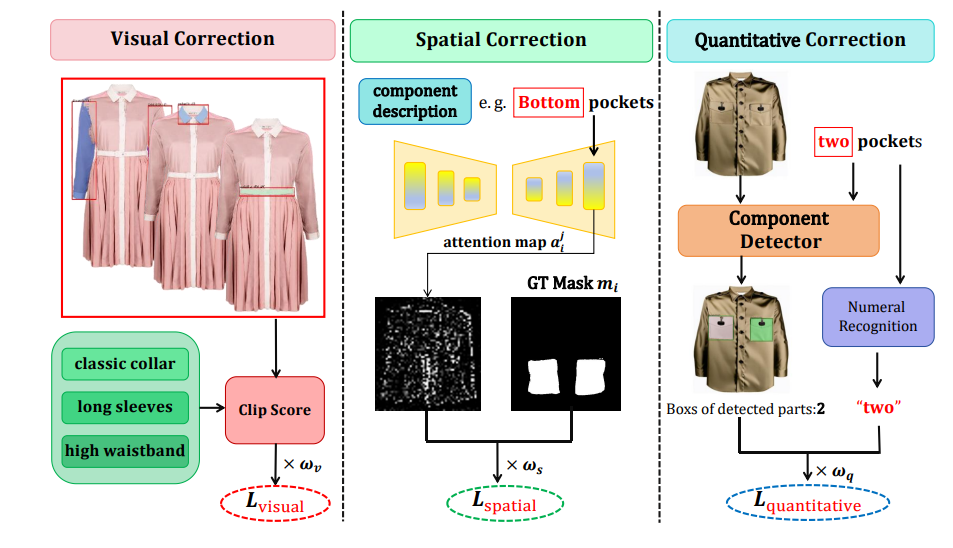
提出的多级校正的说明。生成的服装图像在组件级别进行分解,然后进行校正程序,包括对齐以确保文本图像一致性、空间交叉注意图和组件数量对齐。
实验
数据集
实验是在CM-Fashion数据集上进行的,该数据集由50万张服装图像组成,分辨率为512×512,每张图像都附有相应的说明文字。采用自动组件提取管道从图像中提取组件级别的服装分割和组件计数。随后用提取的信息来丰富标题。因此,我们设计了一个来自CM-Fashion数据集的增强服装数据集,具有优化的标题和组件级分割和数量。
效果


与基线的视觉比较。红框表示未正确生成的区域,绿框表示正确生成的区域,黄框表示未生成的区域。我们的方法在捕捉服装部件的纹理、定位和数量方面表现出卓越的性能,从而生成具有精确细粒度对齐的逼真时尚图像。
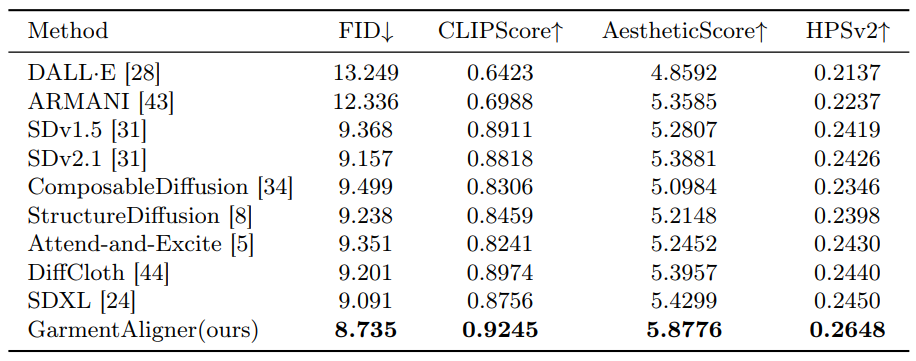
与基线的定量比较结果。与许多方法相比,我们的方法实现了最佳性能,在图像质量和文本与图像之间的一致性指标方面表现出色。
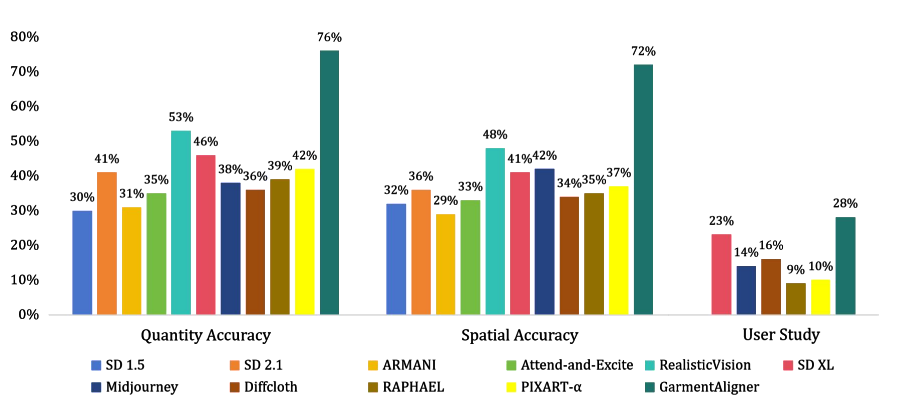
我们的方法和基线的组件级数量和空间精度与用户研究结果。我们的方法表现出出色的性能,在数量和空间维度上都明显优于其他方法,并获得了用户偏好。

消融实验中不同变化的视觉比较。[M]表示[V+S+C]的组合,其余的定义相同。
结论
本研究引入了 GarmentAligner,这是一种文本到服装的扩散模型,旨在纠正服装生成中固有的细粒度语义错位问题。通过将检索增强对比学习与多级校正相结合,GarmentAligner 有效地将生成的服装组件的视觉语义、空间定位和数量与提供的标题对齐。此外,我们设计了一个自动组件提取管道,从图像中提取有关服装组件的空间和定量信息,这些信息可应用于任何服装数据集,从而促进高质量服装生成的进步。我们的实验表明,与现有方法相比,GarmentAligner 可以生成具有改进的语义对齐的优质服装图像。
社会影响和局限性。 在生产高质量服装的同时,我们的方法仍然遇到某些限制。我们方法中使用的训练数据是通过提出的提取管道生成的,这严重依赖于语义分割和检测模型的准确性。不可避免地,可能会出现错误,特别是在处理大规模数据集时。此外,从预训练模型中继承的偏见可能会导致输出缺乏稳健性和用户友好性。未来需要采取措施,通过减少偏见和彻底审查来解决这些道德问题。
这篇关于中山大学和联想研究院提出文本到服装生成模型GarmentAligner,解决服装生成中语义对齐、数量、位置和相互关系等问题。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








