语义专题

理解分类器(linear)为什么可以做语义方向的指导?(解纠缠)
Attribute Manipulation(属性编辑)、disentanglement(解纠缠)常用的两种做法:线性探针和PCA_disentanglement和alignment-CSDN博客 在解纠缠的过程中,有一种非常简单的方法来引导G向某个方向进行生成,然后我们通过向不同的方向进行行走,那么就会得到这个属性上的图像。那么你利用多个方向进行生成,便得到了各种方向的图像,每个方向对应了很多

C++11 ---- 右值引用和移动语义
文章目录 1 左值引用和右值引用2. 左值引用与右值引用总结3. 右值引用使用场景和意义4. 再谈移动构造函数和移动赋值运算符重载5. 关键字default 和 delete6. move函数7. 完美转发 1 左值引用和右值引用 之前的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以在C++11之前的引用都叫做左值引用。无论左值引用还是右值引用,都是给对
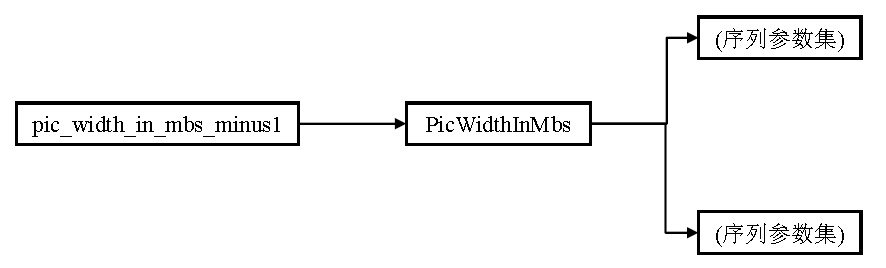
H264的句法和语义(二)
1.2 句法元素的分层结构 1.2.1 句法元素与变量 编码器将数据编码为句法元素然后依次发送。在解码器端,通常要将句法元素作求值计算,得出一些中间数据,这些中间数据就是H.264定义的变量。 图1 从句法元素解出变量 pic_width_in_mbs_minus1 是解码器直接从码流中提取的句法元素,这个句法元素表征图像的宽度以宏块为单位。我们看到,为了


# 使用 OpenAI 的 Embeddings 接口实现文本和代码的语义搜索
本文主要介绍 OpenAI 的 Embeddings (嵌入) 接口,该接口可以轻松执行自然语言和代码任务,如语义搜索、聚类、主题建模和分类。 Embeddings 是转换为数字序列的概念的数字表示,使计算机可以轻松理解这些概念之间的关系。Embeddings 在 3 个标准基准测试中优于顶级模型,其中代码搜索的改进相对提升了 20%。 Embeddings 对于处理自然语言和代码非常有用,因

【论文阅读】语义通信安全研究综述(2024)
摘要 语义通信系统架构 笔记 内容概述 引言:介绍了语义通信技术的背景、发展和重要性,以及它在无线通信系统中面临的安全挑战。 语义通信系统架构及安全攻击:描述了一个端到端的深度学习语义通信系统的基本架构,包括语义编解码器、信道编解码器和收发端知识库等模块,并讨论了这些模块可能遇到的安全攻击,如窃听、篡改等。 语义通信模型安全研究现状:详细讨论了模型安全攻击手段(数据投毒、后门

将语义分割的标签转换为实例分割(yolo)的标签
语义分割的标签(目标处为255,其余处为0) 实例分割的标签(yolo.txt),描述边界的多边形顶点的归一化位置 绘制在原图类似蓝色的边框所示。 废话不多说,直接贴代码; import osimport cv2import numpy as npimport shutildef img2label(imgPath, labelPath, imgbjPath, seletName)

【Python机器学习】卷积神经网络(CNN)——语义理解
无论是人类还是机器,理解隐藏在文字背后的意图,对于倾听者或阅读者来说的,都是一项重要的技能。除了理解单个词的含义,词之间还有各种各样巧妙的组合方式。 词的性质和奥妙与词之间的关系密切相关。这种关系至少有两种表达方式: 词序词的临近度 这些关系的模式以及词本身存在的模式可以从两个方面来表示:空间和时间。两者的区别主要是:对于前者,要像在书页上的句子那样来处理——在文字的位置上寻找关系;对于后者

HTML语义化标签的重要性及常见错误
聚沙成塔·每天进步一点点 本文回顾 ⭐ 专栏简介HTML语义化标签的重要性及常见错误1. 引言2. 什么是HTML语义化标签?2.1 语义化标签的定义2.2 语义化标签的例子 3. HTML语义化标签的重要性3.1 提升可访问性 (Accessibility)3.2 改善搜索引擎优化 (SEO)3.3 提高代码可读性和可维护性3.4 增强网页的表现力3.5 支持未来的发展 4. 常见的

目标检测和图像语义分割领域的性能评价指标
混淆矩阵 从混淆矩阵出发,再看各项性能评价指标就一目了然了。 1)True positives(TP): 被正确分类到正样本的样本数量,即所预测的正样本中,真实的正样本的数量; 2)False positives(FP): 被错误分类到正样本的样本数量,即所预测的正样本中,实际上是负样本的样本数量; 3)False negatives(FN): 被错误分类到负样本的样本数量,即所预测的负样

NLP-信息抽取:关系抽取【即:三元组抽取,主要用于抽取实体间的关系】【基于命名实体识别、分词、词性标注、依存句法分析、语义角色标注】【自定义模板/规则、监督学习(分类器)、半监督学习、无监督学习】
信息抽取主要包括三个子任务: 实体抽取与链指:也就是命名实体识别关系抽取:通常我们说的三元组(triple)抽取,主要用于抽取实体间的关系事件抽取:相当于一种多元关系的抽取 一、关系抽取概述 关系抽取通常在实体抽取与实体链指之后。在识别出句子中的关键实体后,还需要抽取两个实体或多个实体之间的语义关系。语义关系通常用于连接两个实体,并与实体一起表达文本的主要含义。常见的关系抽取结果

NLP-文本处理:词性标注【使用成熟的第三方工具包:中文(哈工大LTP)、英文()】【对分词后得到的“词语列表”进行词性标注,词性标注的结果用于依存句法分析、语义角色标注】
词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果, 常见的词性有14种, 如: 名词, 动词, 形容词等. 顾名思义, 词性标注(Part-Of-Speech tagging, 简称POS)就是标注出一段文本中每个词汇的词性. 举个栗子: 我爱自然语言处理==>我/rr, 爱/v, 自然语言/n, 处理/vnrr: 人称代词v: 动词n: 名词vn

keras 实现dense prediction 逐像素标注 语义分割 像素级语义标注 pixelwise segmention labeling classification 3D数据
主要是keras的示例都是图片分类。而真正的论文代码,又太大了,不适合初学者(比如我)来学习。 所以我查找了一些资料。我在google 上捞的。 其中有个教程让人感觉很好.更完整的教程。另一个教程。 大概就是说,你的输入ground truth label需要是(width*height,class number),然后网络最后需要加个sigmoid,后面用binary_crossentro

NLP07:基于潜在隐语义索引的文本相似度计算
1.潜在隐语义索引(LSI)概述 潜在语义索引(Latent Semantic Indexing,以下简称LSI),有的文章也叫Latent Semantic Analysis(LSA)。其实是一个东西,后面我们统称LSI,它是一种简单实用的主题模型。LSI是基于奇异值分解(SVD)的方法来得到文本的主题的。 这里我们简要回顾下SVD:对于一个 m × n m \times n m×n的矩阵

基于Pytorch框架的深度学习HRnet网络人像语义分割系统源码
第一步:准备数据 头发分割数据,总共有5711张图片,里面的像素值为0和1,所以看起来全部是黑的,不影响使用 第二步:搭建模型 计算机视觉领域有很多任务是位置敏感的,比如目标检测、语义分割、实例分割等等。为了这些任务位置信息更加精准,很容易想到的做法就是维持高分辨率的feature map,事实上HRNet之前几乎所有的网络都是这么做的,通过下采样得到强语义信息,然后再上采样恢复

【Python机器学习】NLP词频背后的含义——隐性语义分析
隐性语义分析基于最古老和最常用的降维技术——奇异值分解(SVD)。SVD将一个矩阵分解成3个方阵,其中一个是对角矩阵。 SVD的一个应用是求逆矩阵。一个矩阵可以分解成3个最简单的方阵,然后对这些方阵求转置后再把它们相乘,就得到了原始矩阵的逆矩阵。它为我们提供了一个对大型复杂矩阵求逆的捷径。SVD适用于桁架结构的应力和应变分析等机械工程问题,它对电气工程中的电路分析也很有用,它甚至在数据科学中被用

图像字幕Image Captioning——使用语法和语义正确的语言描述图像
1. 什么是图像字幕 Image Captioning(图像字幕生成) 是计算机视觉和自然语言处理(NLP)领域的一个交叉研究任务,其目标是自动生成能够描述给定图像内容的自然语言句子。这项任务要求系统不仅要理解图像中的视觉内容,还要能够将这些视觉信息转化为具有连贯性和语义丰富的文本描述。 图像字幕任务的3个关键因素:图像中的显著对象;对象之间的相互作用;用自然语

【Unity Shader】Unity提供的CG/HLSL语义
主要参考《Unity Shader入门精要》一书,外加自己的一些总结 什么是语义 语义实际就是一个赋给Shader输入和输出的字符串,这个字符串表达了这个参数的含义。这些语义可以让Shader知道从哪里读取数据,并把数据输到哪里。 在DirectX10以后,有了一种新的语义类型,即系统数值语义(system-value semantics)。这类语义是以SV

Halcon20.11深度学习语义分割模型
1.前言:深度目标检测模型已经可以满足一大部分的检测需求,但是在逐像素精度分割方向是无法做到的。这时候就需要训练深度语义分割模型,标注工具依然使用的MVTec Deep Learning Tool 24.05。实现顺序依然是先用标注工具把所有的图标注完毕后,导出标注数据集,即可利用此数据集,在halcon代码中训练。 2.上干货,深度语义分割训练源码: 模型训练预处理准备阶段********

中山大学和联想研究院提出文本到服装生成模型GarmentAligner,解决服装生成中语义对齐、数量、位置和相互关系等问题。
中山大学和联想研究院提出一个能够根据文字描述生成服装图像的智能工具GarmentAligner。它可以从已有服装图像中提取出各个组成部分,并记录下它们的位置和数量。接着根据你的描述进行匹配,找出最吻合的服装组件进行组合。而为了确保生成的图像能够准确反映描述,不仅仅是看上去好看,还可以在细节上做到精准对齐。通过这种方法,GarmentAligner可以在时尚设计的过程中给你提供更多灵感和帮助!

C++基础面试题 | 什么是C++的移动语义和完美转发?
若待上林花似锦,出门俱是看花人。 - 《城东早春》(杨巨源) 2024.8.26 回答重点 移动语义(Move Semantics)和完美转发(Perfect Forwarding)都是C++11 引入的新特性。 移动语义实现了从传统的拷贝资源到转移将亡对象资源,减少了拷贝,提高了效率。而完美转发实现了一个可以接收任意类型参数的函数,并通过forward将原始的参数类型转发给最匹配的下
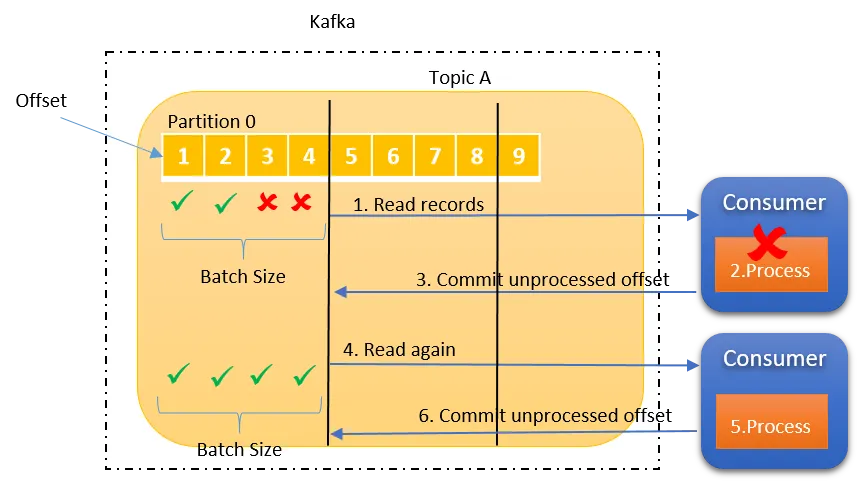
图解Kafka | 5张图讲透Kafka 消费者交付语义
Kafka 消费者交付语义指的是 Kafka 消费者在处理消息时如何保证消息的可靠性和一致性。这涉及到消息是否被丢失、重复处理或者按顺序消费。 Kafka消费者交付语义有三种,即: 最多一次至少一次精确一次 当消费者组/消费者从 Kafka 消费数据时,仅支持最多一次和至少一次这两种语义。但是您可以通过选择适当的数据存储来实现类似于精确一次的交付语义,例如,任何键值存储、RDBMS(主键)、

Unet改进8:在不同位置添加SpatialGroupEnhance||空间群智能增强:改进卷积网络中的语义特征学习
本文内容:在不同位置添加SpatialGroupEnhance 论文简介 卷积神经网络(Convolutional Neural Networks, cnn)通过收集分层的、不同部分的语义子特征来生成复杂对象的特征表示。这些子特征通常以分组的形式分布在每一层的特征向量中[43,32],代表各种语义实体。然而,这些子特征的激活往往受到相似模式和噪声背景的空间影响,导致错误的定位和识别。我们提

SemSegMap :基于3D点云语义信息的定位
点云PCL免费知识星球,点云论文速读。 文章:SemSegMap - 3D Segment-Based Semantic Localization 作者:Andrei Cramariuc, Florian Tschopp, Nikhilesh Alatur, Stefan Benz 代码:https://github.com/ethz-asl/segmap 编译:点云PCL 欢迎各位加入免费知识

Elasticsearch:使用 semantic_text 进行语义搜索
警告:截止 8.15 版本,此功能处于测试阶段,可能会发生变化。设计和代码不如官方 GA 功能成熟,并且按原样提供,不提供任何保证。测试版功能不受官方 GA 功能的支持 SLA 约束。 本教程向你展示如何使用 semantic text 功能对数据执行语义搜索。 语义文本通过在提取时提供推理并自动提供合理的默认值来简化推理工作流程。你无需定义与模型相关的设置和参数,也无需创建推理提取管道
