本文主要是介绍YOLOv5改进 | Conv篇 | 利用YOLOv10提出的UIB模块二次创新C3(附代码 + 完整修改教程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、本文介绍
本文给大家带来的改进机制是利用利用YOLOv10提出的UIB模块二次创新C3助力YOLOv5进行有效涨点,其中C2fUIB模块所用到的CIB模块是一种紧凑的倒置块结构,它采用廉价的深度卷积进行空间混合,并采用成本效益高的点卷积进行通道混合。本文针对该方法给出多种使用方法,大家可以根据自己的数据集来针对性的使用,同时本文附C3UIB网络结构图!
欢迎大家订阅我的专栏一起学习YOLO!
专栏目录:YOLOv5改进有效涨点目录 | 包含卷积、主干、检测头、注意力机制、Neck上百种创新机制
目录
一、本文介绍
二、C2fCIB介绍
三、核心代码
四、手把手教你添加C3CIB模块
4.1 C3CIB添加步骤
4.1.1 修改一
4.1.2 修改二
4.1.3 修改三
4.1.4 修改四
4.2 C3CIB的yaml文件
4.3 训练截图
五、本文总结
二、C2fCIB介绍

论文地址:官方论文地址点击此处即可跳转
代码地址:官方代码地址点击此处即可跳转

YOLO通常为所有阶段使用相同的基本构建块,例如YOLOv8中的瓶颈块。为全面检查这种同质设计的冗余,我们利用内在秩分析各阶段的冗余。具体而言,我们计算每个阶段最后一个基本块的最后一个卷积的数值秩,表示超过阈值的奇异值数量。图3.(a)展示了YOLOv8的结果,表明深层阶段和大模型往往表现出更多冗余。此观察表明,简单地为所有阶段应用相同的块设计对于最佳的容量-效率权衡来说是次优的。为此,我们提出了一种基于秩的块设计方案,旨在通过紧凑的架构设计减少冗余阶段的复杂性。我们首先提出了一种紧凑的倒置块(CIB)结构,它采用廉价的深度卷积进行空间混合,并采用成本效益高的点卷积进行通道混合,如图3.(b)所示。它可以作为高效的基本构建块,例如嵌入ELAN结构中。然后,我们倡导一种基于秩的块分配策略,以在保持竞争性容量的同时实现最佳效率。具体而言,给定一个模型,我们按内在秩从低到高排序其所有阶段。我们进一步检查用CIB替换领先阶段的基本块的性能变化。如果与给定模型相比没有性能下降,我们继续替换下一个阶段,否则停止该过程。这样,我们可以在各个阶段和模型规模中实现自适应紧凑块设计,在不影响性能的情况下实现更高的效率(这个结构外部结构是和C2f一样只是用CIB结构替换了C2f的Bottleneck结构)。

三、核心代码
核心代码的使用方式看章节四!
import torch
import torch.nn as nn__all__ = ['C3CIB']class Bottleneck(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, andexpansion."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):"""'forward()' applies the YOLO FPN to input data."""return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3CIB(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, lk=False, g=1, e=0.5):super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(CIB(c_, c_, shortcut, e=1.0, lk=lk) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))def autopad(k, p=None, d=1): # kernel, padding, dilation"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initialize Conv layer with given arguments including activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Apply convolution, batch normalization and activation to input tensor."""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""Perform transposed convolution of 2D data."""return self.act(self.conv(x))def fuse_conv_and_bn(conv, bn):"""Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/."""fusedconv = (nn.Conv2d(conv.in_channels,conv.out_channels,kernel_size=conv.kernel_size,stride=conv.stride,padding=conv.padding,dilation=conv.dilation,groups=conv.groups,bias=True,).requires_grad_(False).to(conv.weight.device))# Prepare filtersw_conv = conv.weight.clone().view(conv.out_channels, -1)w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))# Prepare spatial biasb_conv = torch.zeros(conv.weight.shape[0], device=conv.weight.device) if conv.bias is None else conv.biasb_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)return fusedconvclass RepVGGDW(torch.nn.Module):def __init__(self, ed) -> None:super().__init__()self.conv = Conv(ed, ed, 7, 1, 3, g=ed, act=False)self.conv1 = Conv(ed, ed, 3, 1, 1, g=ed, act=False)self.dim = edself.act = nn.SiLU()def forward(self, x):return self.act(self.conv(x) + self.conv1(x))def forward_fuse(self, x):return self.act(self.conv(x))@torch.no_grad()def fuse(self):conv = fuse_conv_and_bn(self.conv.conv, self.conv.bn)conv1 = fuse_conv_and_bn(self.conv1.conv, self.conv1.bn)conv_w = conv.weightconv_b = conv.biasconv1_w = conv1.weightconv1_b = conv1.biasconv1_w = torch.nn.functional.pad(conv1_w, [2, 2, 2, 2])final_conv_w = conv_w + conv1_wfinal_conv_b = conv_b + conv1_bconv.weight.data.copy_(final_conv_w)conv.bias.data.copy_(final_conv_b)self.conv = convdel self.conv1class CIB(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, e=0.5, lk=False):"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, andexpansion."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = nn.Sequential(Conv(c1, c1, 3, g=c1),Conv(c1, 2 * c_, 1),Conv(2 * c_, 2 * c_, 3, g=2 * c_) if not lk else RepVGGDW(2 * c_),Conv(2 * c_, c2, 1),Conv(c2, c2, 3, g=c2),)self.add = shortcut and c1 == c2def forward(self, x):"""'forward()' applies the YOLO FPN to input data."""return x + self.cv1(x) if self.add else self.cv1(x)四、手把手教你添加C3CIB模块
4.1 C3CIB添加步骤
4.1.1 修改一
首先我们找到如下的目录'yolov5-master/models',然后在这个目录下在创建一个新的目录然后这个就是存储改进的仓库,大家可以在这里新建所有的改进的py文件,对应改进的文件名字可以根据你自己的习惯起(不影响任何但是下面导入的时候记住改成你对应的即可),然后将C3CIB的核心代码复制进去。

4.1.2 修改二
然后在新建的目录里面我们在新建一个__init__.py文件(此文件大家只需要建立一个即可),然后我们在里面添加导入我们模块的代码。注意标记一个'.'其作用是标记当前目录。

4.1.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加)
注意的添加位置要放在common的导入上面!!!!!

4.1.4 修改四
然后我们找到parse_model方法,按照如下修改->

到此就修改完成了,复制下面的ymal文件即可运行。
4.2 C3CIB的yaml文件
# YOLOv9# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []],# conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4CIB, [256, 128, 64, 1]], # 3# conv down[-1, 1, Conv, [256, 3, 2]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4CIB, [512, 256, 128, 1]], # 5# conv down[-1, 1, Conv, [512, 3, 2]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4CIB, [512, 512, 256, 1]], # 7# conv down[-1, 1, Conv, [512, 3, 2]], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4CIB, [512, 512, 256, 1]], # 9]# YOLOv9 head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 10# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4CIB, [512, 512, 256, 1]], # 13# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4CIB, [256, 256, 128, 1]], # 16 (P3/8-small)# conv-down merge[-1, 1, Conv, [256, 3, 2]],[[-1, 13], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4CIB, [512, 512, 256, 1]], # 19 (P4/16-medium)# conv-down merge[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4CIB, [512, 512, 256, 1, True]], # 22 (P5/32-large)# routing[5, 1, CBLinear, [[256]]], # 23[7, 1, CBLinear, [[256, 512]]], # 24[9, 1, CBLinear, [[256, 512, 512]]], # 25# conv down[0, 1, Conv, [64, 3, 2]], # 26-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 27-P2/4# elan-1 block[-1, 1, RepNCSPELAN4CIB, [256, 128, 64, 1]], # 28# conv down fuse[-1, 1, Conv, [256, 3, 2]], # 29-P3/8[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30 # elan-2 block[-1, 1, RepNCSPELAN4CIB, [512, 256, 128, 1]], # 31# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 32-P4/16[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33 # elan-2 block[-1, 1, RepNCSPELAN4CIB, [512, 512, 256, 1]], # 34# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 35-P5/32[[25, -1], 1, CBFuse, [[2]]], # 36# elan-2 block[-1, 1, RepNCSPELAN4CIB, [512, 512, 256, 1, True]], # 37# detect[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]
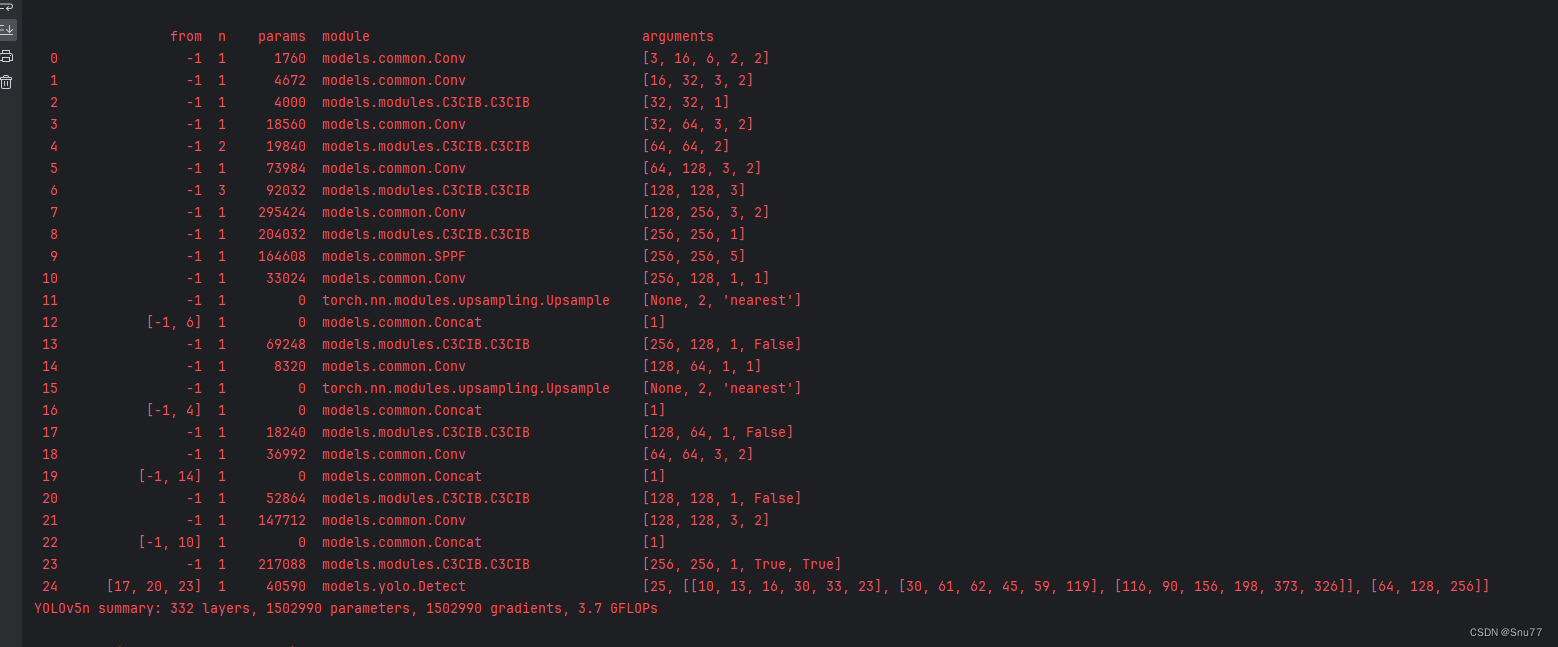
4.3 训练截图
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏目录:YOLOv5改进有效涨点目录 | 包含卷积、主干、检测头、注意力机制、Neck上百种创新机制
这篇关于YOLOv5改进 | Conv篇 | 利用YOLOv10提出的UIB模块二次创新C3(附代码 + 完整修改教程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







