改进专题

一种改进的red5集群方案的应用、基于Red5服务器集群负载均衡调度算法研究
转自: 一种改进的red5集群方案的应用: http://wenku.baidu.com/link?url=jYQ1wNwHVBqJ-5XCYq0PRligp6Y5q6BYXyISUsF56My8DP8dc9CZ4pZvpPz1abxJn8fojMrL0IyfmMHStpvkotqC1RWlRMGnzVL1X4IPOa_ 基于Red5服务器集群负载均衡调度算法研究 http://ww

YOLOv8改进实战 | 注意力篇 | 引入CVPR2024 PKINet 上下文锚点注意力CAAttention
YOLOv8专栏导航:点击此处跳转 前言 YOLOv8 是由 YOLOv5 的发布者 Ultralytics 发布的最新版本的 YOLO。它可用于对象检测、分割、分类任务以及大型数据集的学习,并且可以在包括 CPU 和 GPU 在内的各种硬件上执行。 YOLOv8 是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成功的 YOLO 版本的基础上,并引入了新的功能和改进,以

YOLOv8改进 | Conv篇 | YOLOv8引入DWR
1. DWR介绍 1.1 摘要:当前的许多工作直接采用多速率深度扩张卷积从一个输入特征图中同时捕获多尺度上下文信息,从而提高实时语义分割的特征提取效率。 然而,这种设计可能会因为结构和超参数的不合理而导致多尺度上下文信息的访问困难。 为了降低多尺度上下文信息的绘制难度,我们提出了一种高效的多尺度特征提取方法,将原始的单步方法分解为区域残差-语义残差两个步骤。 在该方法中,多速率深度扩张卷积

爆改YOLOv8|利用yolov10的SCDown改进yolov8-下采样
1, 本文介绍 YOLOv10 的 SCDown 方法来优化 YOLOv8 的下采样过程。SCDown 通过点卷积调整通道维度,再通过深度卷积进行空间下采样,从而减少了计算成本和参数数量。这种方法不仅降低了延迟,还在保持下采样过程信息的同时提供了竞争性的性能。 关于SCDown 的详细介绍可以看论文:https://arxiv.org/pdf/2405.14458 本文将讲解如何将SCDow

【数据分析案例】从XGBoost算法开始,更好地理解和改进你的模型
案例来源:@将门创投 案例地址: https://mp.weixin.qq.com/s/oeetxWMM3cr1BgvIaGU54A 1. 目标:使用xgb评估客户的信贷风险时,还希望得出揭示 2. xgb全局特征重要性度量

爆改YOLOv8|利用SCConv改进yolov8-即轻量又涨点
1,本文介绍 SCConv(空间和通道重构卷积)是一种高效的卷积模块,旨在优化卷积神经网络(CNN)的性能,通过减少空间和通道的冗余来降低计算资源的消耗。该模块由两个核心组件构成: 空间重构单元(SRU):通过分离和重构的方式,SRU 有效减少空间冗余。 通道重构单元(CRU):利用分割-变换-融合策略,CRU 旨在降低通道冗余 关于SCConv的详细介绍可以看论文:SCConv: S
YoloV10改进策略:下采样改进|自研下采样模块(独家改进)|疯狂涨点|附结构图
文章目录 摘要自研下采样模块及其变种第一种改进方法 YoloV10官方测试结果改进方法测试结果总结 摘要 本文介绍我自研的下采样模块。本次改进的下采样模块是一种通用的改进方法,你可以用分类任务的主干网络中,也可以用在分割和超分的任务中。已经有粉丝用来改进ConvNext模型,取得了非常好的效果,配合一些其他的改进,发一篇CVPR、ECCV之类的顶会完全没有问题。 本次我将这个模

等保测评后的持续改进:企业安全策略升级
等保测评并非终点,而是一个持续改进的起点。通过等保测评后,企业应将此作为信息安全升级的契机,不断优化安全策略,以适应不断变化的威胁环境。本文将探讨等保测评后的持续改进策略,助力企业实现安全策略的升级。 一、评估与分析 1. 测评结果分析:深入分析等保测评结果,识别存在的安全问题和不足,理解其对业务的影响。 2. 安全态势评估:定期进行安全态势评估,包括内外部威胁分析、安全漏洞扫描等,确保对当

YOLOv8改进实战 | 注意力篇 | 引入基于跨空间学习的高效多尺度注意力EMA,小目标涨点明显
YOLOv8专栏导航:点击此处跳转 前言 YOLOv8 是由 YOLOv5 的发布者 Ultralytics 发布的最新版本的 YOLO。它可用于对象检测、分割、分类任务以及大型数据集的学习,并且可以在包括 CPU 和 GPU 在内的各种硬件上执行。 YOLOv8 是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成功的 YOLO 版本的基础上,并引入了新的功能和改进
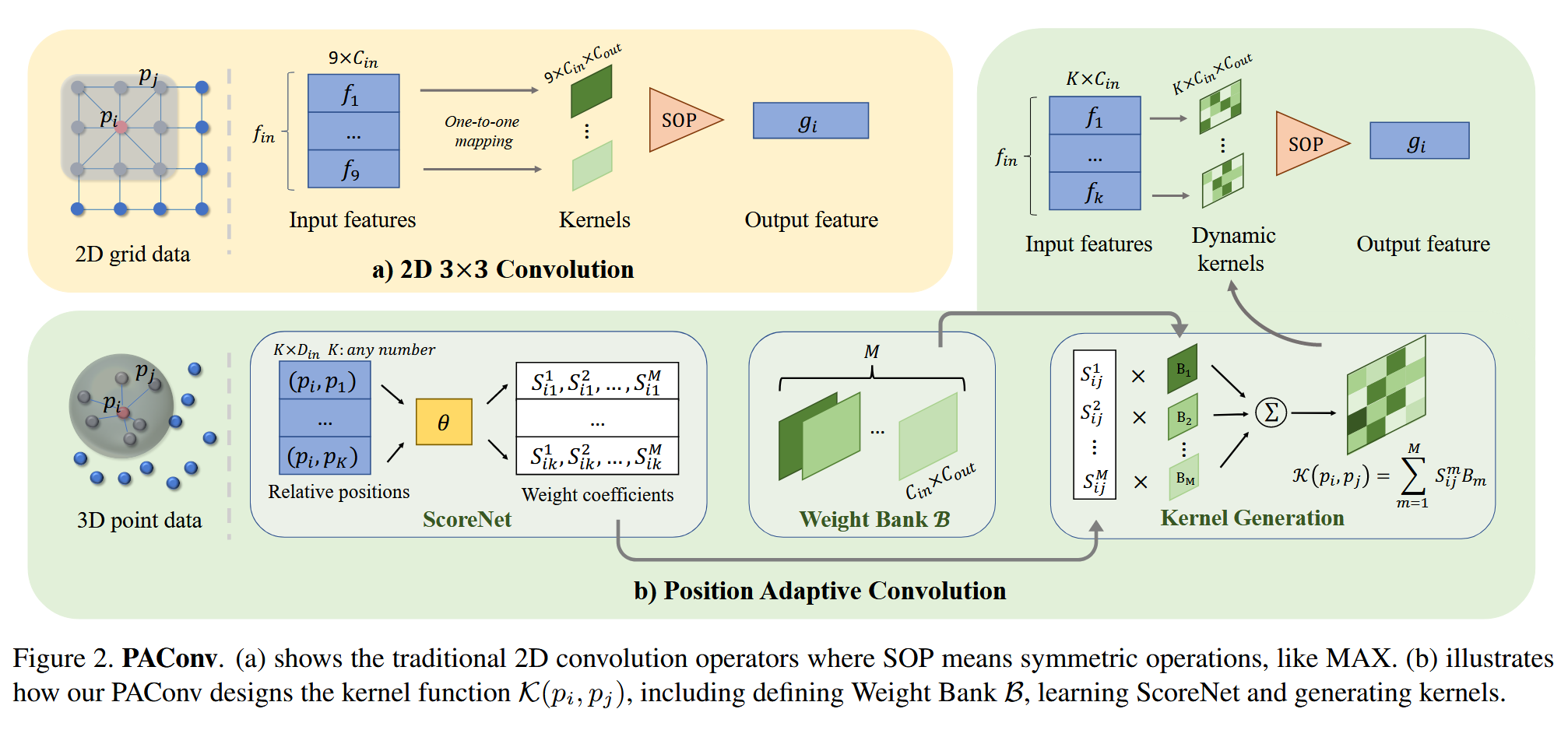
PointNet++改进策略 :模块改进 | PAConv,位置自适应卷积提升精度
题目:PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds来源:CVPR2021机构:香港大学论文:https://arxiv.org/abs/2103.14635代码:https://github.com/CVMI-Lab/PAConv 前言 PAConv,全称为位置自适应卷积

爆改YOLOv8|利用yolov10的PSA注意力机制改进yolov8-高效涨点
1,本文介绍 PSA是一种改进的自注意力机制,旨在提升模型的效率和准确性。传统的自注意力机制需要计算所有位置对之间的注意力,这会导致计算复杂度高和训练时间长。PSA通过引入极化因子来减少需要计算的注意力对的数量,从而降低计算负担。极化因子是一个向量,通过与每个位置的向量点积,确定哪些位置需要计算注意力。这种方法可以在保持模型准确度的前提下,显著减少计算量,从而提升自注意力机制的效率。 关于PS

企业架构对现代化组织的价值:改进流程、提高效率和更好地决策
在当今充满竞争和不确定性的商业环境中,企业必须不断寻求优化运营和提升决策能力的途径。企业架构(EA)作为一种系统化的管理框架,正在成为现代企业提升效能的关键工具。它不仅为组织提供了一种清晰的视角,以便更好地理解和管理复杂的业务流程,还通过优化资源配置、改进流程管理和加强决策支持,帮助企业在动态环境中保持竞争优势。 本文将探讨企业架构如何通过改进流程、提升效率和增强决策能力,成为现代企业在复杂

图像数据到网格数据-2——改进的SMC算法
概要 本篇接上一篇继续介绍网格生成算法,同时不少内容继承自上篇。上篇介绍了经典的三维图像网格生成算法MarchingCubes,并且基于其思想和三角形表实现了对样例数据的网格构建。本篇继续探讨网格生成算法,并且在MC的基础上进行进一步的简化和改进,形成Simple Marching Cubes(简称SMC算法)。本篇主要介绍SMC算法的思路以及与MC算法的对比。同时也介绍如何在MC三角形

YOLOv8改进 | 模块缝合 | C2f 融合REPVGGOREPA提升检测性能【详细步骤 完整代码】
秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转 💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 专栏目录 :《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有100+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进——点击即可跳转 结构重参数化技术在计算机视觉领域日益
openlayer的测量面积公式的改进
问题来源: 首先要注意到Polygon内可能含有内部线性环,所以在计算时需要减去环的面积,同时也会有MultiPolygon的存在。所以对之前的公式进行修改。 公式代码: formatArea: function(polygon) {var wgs84Sphere = new ol.Sphere(6362790); //6378137,取该值为了跟sql对应6362789.8747i
YOLOv8改进实战 | 引入混合局部通道注意力模块MLCA(2023轻量级)
YOLOv8专栏导航:点击此处跳转 前言 YOLOv8 是由 YOLOv5 的发布者 Ultralytics 发布的最新版本的 YOLO。它可用于对象检测、分割、分类任务以及大型数据集的学习,并且可以在包括 CPU 和 GPU 在内的各种硬件上执行。 YOLOv8 是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成功的 YOLO 版本的基础上,并引入了新的功能和改进

YoloV10改进策略:卷积篇|基于PConv的二次创新|附结构图|性能和精度得到大幅度提高(独家原创)
文章目录 摘要论文指导PConv在论文中的描述改进YoloV10的描述 改进代码与结构图改进方法测试结果总结 摘要 在PConv的基础上做了二次创新,创新后的模型不仅在精度和速度上有了质的提升,还可以支持Stride为2的降采样。 改进方法简单高效,需要发论文的同学不要错过! 论文指导 PConv在论文中的描述 论文: 下面我们展示了可以通过利用特征图的冗余来进一步优化成本
数据结构串的实现以及KMP改进算法
</pre><pre name="code" class="cpp">#include <stdio.h>#include <stdlib.h>#define OK 1#define ERROR 0#define TRUE 1#define FALSE 0#define MAXSIZE 40 /* 存储空间初始分配量 */typedef int Status; /* Status是
YoloV9改进策略:下采样改进|集成GCViT的Downsampler模块实现性能显著提升|即插即用
摘要 随着深度学习在计算机视觉领域的广泛应用,目标检测任务成为了研究热点之一。YoloV9作为实时目标检测领域的领先模型,凭借其高效性与准确性赢得了广泛的关注。然而,为了进一步提升YoloV9的性能,特别是在特征提取与下采样过程中的信息保留能力,我们引入了来自GCViT(Global Context Vision Transformers)模型中的Downsampler模块。本文将详细阐述这一改

改进YOLO的群养猪行为识别算法研究及部署(小程序-网站平台-pyqt)
概述 群养猪的运动信息和行为信息与其健康状况息息相关,但人工巡视费时费力,本实验提出采用行为识别算法于群养猪的养殖管理中,识别群养猪drink(饮水)、stand(站立)和lie(躺卧)行为,为自动化养殖提供基础。本项目最终以三种不同的形式进行部署,分别为: 网站平台微信小程序PyQt应用程序 实验流程 下图是基于改进YOLOv5s的群养猪行为识别模型建立流程,可概括为以下几个阶段:数

CV-CNN-2016:GoogleNet-V4【用ResNet模型的残差连接(Residual Connection)思想改进GoogleNet-V3的结构】
Inception V4研究了Inception模块与残差连接的结合。 ResNet结构大大地加深了网络深度,还极大地提升了训练速度,同时性能也有提升。 Inception V4主要利用残差连接(Residual Connection)来改进V3结构,得到Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4网络。 ResNet的残差结构如下

yolov8改进策略,有可以直接用的代码,80余种改进策略,有讲解
YOLOv8改进策略介绍 YOLOv8是在YOLOv7的基础上进一步发展的目标检测模型,继承了YOLO系列模型的优点,如实时性、准确性和灵活性。然而,任何模型都有进一步改进的空间,以提高其性能、准确性和鲁棒性。下面是针对YOLOv8的一些改进策略,这些策略可以帮助提高模型的性能,并附有一些示例代码。 改进策略概览 模型架构改进数据增强损失函数优化训练技巧推理优化 1. 模型架构改

YOLOv9改进策略【模型轻量化】| MoblieNetV3:基于搜索技术和新颖架构设计的轻量型网络模型
一、本文介绍 本文记录的是基于MobileNet V3的YOLOv9目标检测轻量化改进方法研究。MobileNet V3的模型结构是通过网络搜索得来的,其中的基础模块结合了MobileNet V1的深度可分离卷积、MobileNet V2的线性瓶颈和倒置残差结构以及MnasNet中基于挤压和激励的轻量级注意力模块,使模型在性能、效率和灵活性方面都具有显著的优势。 模型参数量计算量推理速度(bs

算法——K-means算法和算法改进
简介:个人学习分享,如有错误,欢迎批评指正。 一、什么是K-means算法? K-means算法是一种无监督的聚类算法,用于将一组数据点分为K个簇(cluster)。其核心目标是将数据点划分到K个不同的簇中,使得每个簇内的数据点之间的相似性最大化,而不同簇之间的相似性最小化。 具体而言,K-means算法通过以下方式实现聚类: 簇中心(质心):每个簇都有一个中心点,称为质心(cent
基于自适应狮群算法优化GRU神经网络进水量预测,gsclst-gru进水量预测,基于黄金正弦改进的狮群算法优化GRU进水量预测
目录 背影 摘要 LSTM的基本定义 LSTM实现的步骤 gru的原理 狮群群算法原理 基于自适应狮群算法优化BILSTM神经网络进水量预测,gsclst-gru进水量预测,基于黄金正弦改进的狮群算法优化BILSTM进水量预测 结果分析 展望 参考论文 背影 传统的方法回归分析容易陷入局部最优准确率低,为提高精度,本文用 ,gsclst-gru进水量预测,基于黄金正弦改进的狮群算法优化GRU