yolov5专题

基于 YOLOv5 的积水检测系统:打造高效智能的智慧城市应用
在城市发展中,积水问题日益严重,特别是在大雨过后,积水往往会影响交通甚至威胁人们的安全。通过现代计算机视觉技术,我们能够智能化地检测和识别积水区域,减少潜在危险。本文将介绍如何使用 YOLOv5 和 PyQt5 搭建一个积水检测系统,结合深度学习和直观的图形界面,为用户提供高效的解决方案。 源码地址: PyQt5+YoloV5 实现积水检测系统 预览: 项目背景
![[yolov5] --- yolov5入门实战「土堆视频」](https://i-blog.csdnimg.cn/direct/8e01ba7709e34acc929cfe32af9e4c41.png)
[yolov5] --- yolov5入门实战「土堆视频」
1 项目介绍及环境配置 下载yolov5 tags 5.0源码,https://github.com/ultralytics/yolov5/tree/v5.0,解压 Pycharm 中创建conda虚拟环境 激活conda虚拟环境 根据作者提供的requirements.txt文件,pip install -r requirements.txt 如果作者没有提供requirement.txt文件
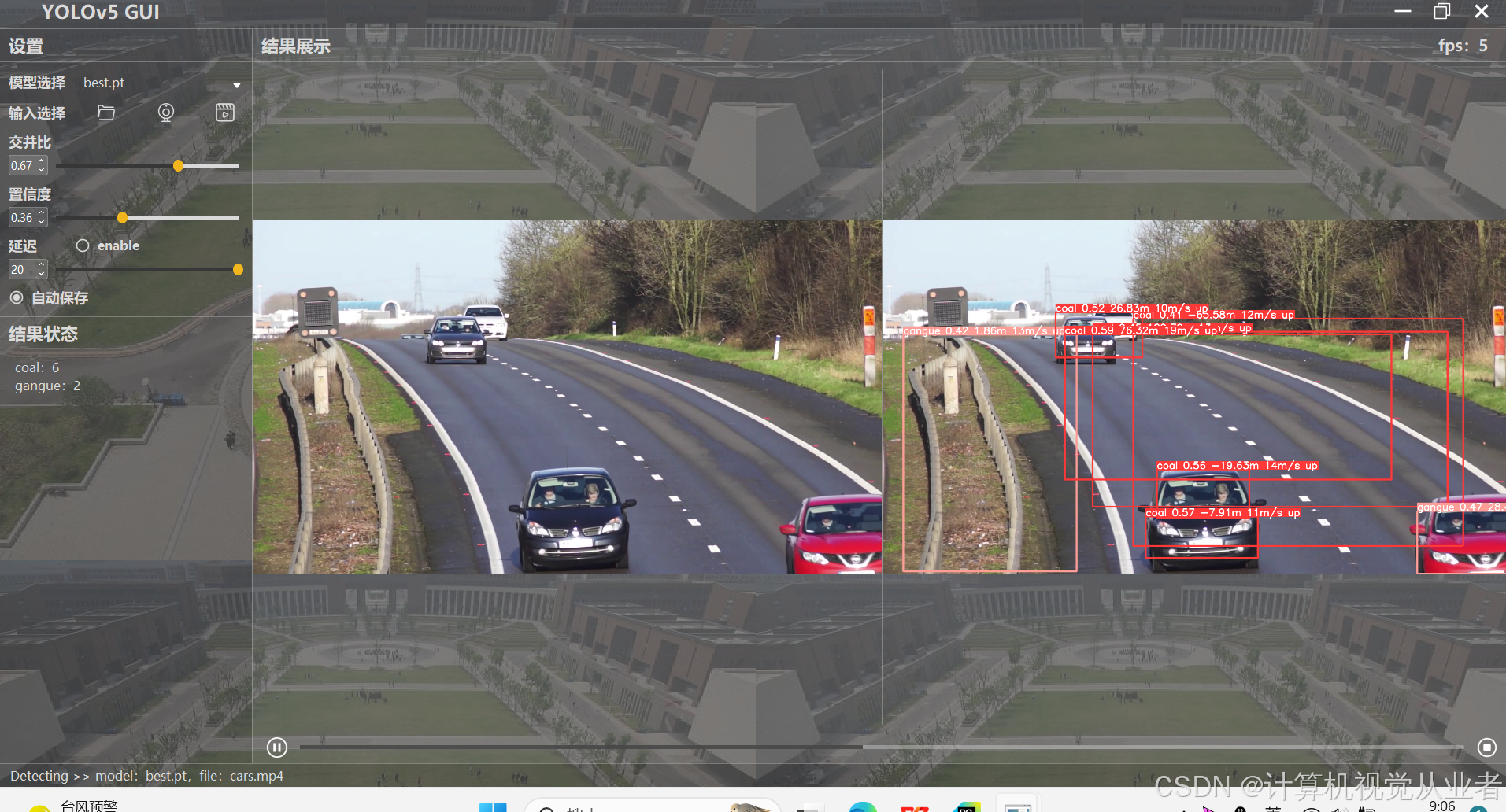
yolov5 +gui界面+单目测距 实现对图片视频摄像头的测距
可实现对图片,视频,摄像头的检测 项目概述 本项目旨在实现一个集成了YOLOv5目标检测算法、图形用户界面(GUI)以及单目测距功能的系统。该系统能够对图片、视频或实时摄像头输入进行目标检测,并估算目标的距离。通过结合YOLOv5的强大检测能力和单目测距技术,系统能够在多种应用场景中提供高效、准确的目标检测和测距功能。 技术栈 YOLOv5:用于目标检测的深度学习模型。Open

YOLOV5入门教学-common.py文件
在 YOLOv5 框架中,common.py 文件是一个核心组件,负责定义深度学习模型的基础模块和常用操作。无论是卷积层、激活函数、特征融合还是其他复杂的模型结构,common.py 都提供了灵活且高效的实现。在这篇文章中,我们将深入解析 common.py 的设计思想、各个模块的功能以及它在 YOLOv5 中的应用。通过理解该文件的实现细节,不仅可以帮助我们更好地掌握 YOLOv5 的内部结构,

基于yolov5的西红柿成熟度检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv5的西红柿成熟度检测系统是一个利用先进深度学习技术的创新项目,旨在提高西红柿成熟度检测的准确性和效率。该系统以YOLOv5为核心算法,该算法由Ultralytics公司于2020年发布,并在YOLOv3的基础上进行了显著改进。YOLOv5以其高效性和准确性在实时目标检测领域备受关注,特别适用于农业视觉检测任务。 该系统通过收集并预处理大量不同成熟度的西红柿图像数据,

在国产芯片上实现YOLOv5/v8图像AI识别-【4.2】RK3588获取USB摄像头图像推流RTSP更多内容见视频
本专栏主要是提供一种国产化图像识别的解决方案,专栏中实现了YOLOv5/v8在国产化芯片上的使用部署,并可以实现网页端实时查看。根据自己的具体需求可以直接产品化部署使用。 B站配套视频:https://www.bilibili.com/video/BV1or421T74f 前言 在实际生产过程中,有很多时候不光是通过网络获取rtsp视频流,通常会采用在板子上插上USB摄像头获取画面。 今天

基于yolov5的猪只识别计数检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv5的猪只识别计数检测系统是一种创新的农业应用解决方案,它结合了深度学习和计算机视觉技术,专为提高养猪业的管理效率和精确度而设计。该系统利用YOLOv5这一先进的目标检测模型,能够实时、准确地在图像或视频中识别并计数猪只。 YOLOv5以其轻量级、高速和准确的特点著称,特别适合用于复杂多变的农场环境。通过摄像头采集的图像数据,系统能够自动检测并标记出每一头猪的位置和数

基于yolov5的煤矿传送带异物检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv5的煤矿传送带异物检测系统是一种高效、智能的监测解决方案,专为煤矿等复杂工业环境设计。该系统利用YOLOv5深度学习算法,结合现场摄像头,对煤矿传送带上的异物进行实时监测与识别。 YOLOv5以其出色的检测速度和准确性著称,通过将原始图像划分为多个网格,并在每个网格中预测可能的目标边界框,实现对传送带上大块煤、矸石、锚杆、槽钢等异物的快速识别。系统能够自动区分正常物

YOLOV5入门教程day3
一. 导入包和基本配置 import argparseimport mathimport osimport randomimport subprocessimport sysimport timefrom copy import deepcopyfrom datetime import datetime, timedeltafrom pathlib import Pathtr

YOLOv5课堂行为识别系统+GUI界面
课堂行为检测 gui/课堂行为识别系统/YOLOv5课堂行为识别/ yolov5/opencv/计算机视觉/python程序/深度学习/pytorch 数据集+标注/配置好环境程序可直接运行/带UI界面/代码+数据集/代码+数据集 [功能]图片识别/视频识别/摄像头识别 损失/准确率等数据可在tensorboard中查看 [种类]可识别hand-raising/reading/writi

TPH-YOLOv5:基于Transformer预测头的改进YOLOv5,用于无人机捕获场景的目标检测
摘要 提出了TPH-YOLOv5。在YOLOv5的基础上,增加了一个预测头来检测不同尺度的目标。然后用Transformer Prediction Heads(TPH)代替原有的预测头,探索自注意机制的预测潜力。还集成了卷积块注意力模型(CBAM),用来发现密集对象场景中的注意力区域。为了实现所提出的TPH-YOLOv 5的更多改进,提供了一些有用的策略,如数据增强,多尺度测试,

基于yolov5的明厨亮灶阳光厨房老鼠检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv5的明厨亮灶阳光厨房老鼠检测系统是一种高效、智能的食品安全监测解决方案。该系统利用YOLOv5网络模型,结合深度学习技术,实现对厨房环境的实时监控与智能分析。 YOLOv5以其高速和高精度的特性,在实时目标检测任务中表现出色。该系统通过安装在前端的智能摄像头,实时采集厨房画面,并利用YOLOv5算法对视频流中的图像进行快速处理。一旦检测到老鼠生物,系统会立即检测到相
ncnn之yolov5(7.0版本)目标检测pnnx部署
一、pnxx介绍与使用 pnnx安装与使用参考: https://github.com/pnnx/pnnxhttps://github.com/Tencent/ncnn/wiki/use-ncnn-with-pytorch-or-onnxhttps://github.com/Tencent/ncnn/tree/master/tools/pnnx 支持python的首选pip,否则就源码编译。

瑞芯微RV1126平台----yolov5输出后处理C++实现
目录 1.前言 2.代码 2.1 padding resize 代码 2.2 瑞芯微yolov5后处理 2.3 坐标框的后处理 3.完整代码 3.1 postprocess.h 3.2 posrprocess.cc 1.前言 标准的yolov5-5.0的输出有三个,分别是 1x255x80x80 1x255x40x40 1x255x20x20 其中这里的255是85

yolov5转成rknn模型
目录 1 转换方法 2 yolov5版本问题 3 yolov5的输出格式问题 4 转成rknn模型时的格式问题 1 转换方法 将yolov5的pth模型转成rknn模型,具体方法分两步 利用yolov5工程中自带的export.py将pt模型转成onnx模型利用如下脚本生成rknn模型 将onnx模型转化为RV1126平台的rknn模型_cumtchw-CSDN博客 这篇笔

基于Atlas200DK部署yolov5(v6.0)
Atlas200_YOLOv5_DVPP_AIPP 在Atlas200DK平台上基于DVPP和AIPP实现部署YOLOv5(v6.0) · DVPP解码JPG,并Resize · AIPP实现颜色转换:YUV420sp_U8 to RGB 效果: 前处理推理后处理5.21ms1.09ms4.41ms 环境: CANN版本:6.0.0.alpha003 OS版本:Ubuntu18.0

YOLOv5改进 | 模块融合 | C3融合 ghost + DynamicConv 【两次融合 + 独家改进】
秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转 💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 专栏目录: 《YOLOv5入门 + 改进涨点》专栏介绍 & 专栏目录 |目前已有70+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进 本文介绍了一种C3_GhostDynamicCon

行为识别实战第二天——Yolov5+SlowFast+deepsort: Action Detection(PytorchVideo)
Yolov5+SlowFast+deepsort 一、简介 YoloV5+SlowFast+DeepSort 是一个结合了目标检测、动作识别和目标跟踪技术的视频处理框架。这一集成系统利用了各自领域中的先进技术,为视频监控、体育分析、人机交互等应用提供了一种强大的解决方案。 1. 组件说明: YoloV5: Yolo(You Only Look Once)是一个流行的实时目标检测

YOLOv5调用海康工业相机实时检测
目录 一、调用海康工业摄像头 1.1 DirectShow插件安装 1.2 查找摄像头编号 1.3 摄像头调用测试 二、修改YOLOv5相关参数 2.1 detect.py修改 2.2 datasets.py修改 一、调用海康工业摄像头 现在可直接利用cv2.VideoCapture()接口调用海康机器人工业相机,首先在官网下载机器视觉工业相机客户端MVS

YOlOV5入门教程
前言 因项目需求,所以要使用yolo进行操作,现在对yolov5进行教程,代码可以在这下载:https://github.com/ultralytics/yolov5 项目结构 下载完成后可以看到资源如图所示。 1.1.github文件夹 ISSUE_TEMPLATE 目录 这个目录下的文件是用于定义GitHub仓库中的问题模板(Issue Templates)。这些模板

垃圾分类笔记YOLOV5(一)-pip换源-口罩识别-训练自己的数据集
pip换源网址 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 不进行配置的是临时换源 1、从github上下载YOLOV5的代码 翻墙软件clash 数据集地址roboflow clash配置一键导入 哔哩哔哩视频地址 数据集的下载格式: 2、修改自己的数据集 将下载好的数据集放到

RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测-迅为电子
随着人工智能和大数据时代的到来,传统嵌入式处理器中的CPU和GPU逐渐无法满足日益增长的深度学习需求。为了应对这一挑战,在一些高端处理器中,NPU(神经网络处理单元)也被集成到了处理器里。NPU的出现不仅减轻了CPU和GPU的负担,还让复杂的计算任务得以高效处理。在典型的工作流中,CPU会首先接收任务,并根据任务的性质将其分配给合适的处理单元,图像处理任务由GPU处理,

yolov5和yolov7车牌识别检测(可检测黄牌、绿牌、双层车牌等各种车牌,准确率高,提供界面)
实现一个车牌识别系统,使用YOLOv5和YOLOv7这两种不同的模型来进行车牌的检测。下面我将提供一个完整的项目概述,包括模型训练脚本、车牌识别代码以及两个GUI界面,分别用于处理静态图片和实时视频流 1. 模型训练 YOLOv5 和 YOLOv7 的训练脚本。使用车牌数据集进行训练。 2. 车牌识别 Python 代码实现车牌的检测与识别。支持多种车牌类型,例如黄色、绿色、双层车牌等

基于yolov5 人体行为检测 对 跌倒 站立 蹲下 坐下 跑 五种行为检测目标检测
该项目使用YOLOv5深度学习框架来检测图像或视频中人体的五种基本行为:跌倒、站立、蹲下、坐下和跑步。YOLOv5(You Only Look Once v5)是一种高效的物体检测模型,能够快速准确地识别出图像中的目标。本项目具有以下特点: 图像检测:用户可以通过上传图片,系统将识别并标记出图像中人体的行为。视频检测:支持实时视频流或本地视频文件的行为检测,并实时显示检测结果。 技术栈

YOLOv5改进 | 融合改进 | C3融合ContextGuided增强分割效果
秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转 💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 专栏目录: 《YOLOv5入门 + 改进涨点》专栏介绍 & 专栏目录 |目前已有70+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进 本文介绍了一种名为CGNet的轻量级语义分割网络

C# Onnx Yolov5 水果识别,人员识别,物品识别 人工智能
目录 先上效果 来电废话,但实用 网络成功案例实践易失败的原因 万物检测涉及技术 下载合集 关键代码 全部代码 实操vs2022安装关键 YOLO V5核心库编译 编写自己识别软件 更新相关依赖 标注字库文件 测试效果 名词解释YOLO 名词解释ONNX 源码 直播教学和作者 先上效果 来电废话,但实用 为何照做网络成功案例仍失败?软件与男