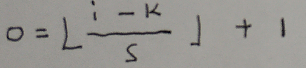conv专题

YOLOv8改进 | Conv篇 | YOLOv8引入DWR
1. DWR介绍 1.1 摘要:当前的许多工作直接采用多速率深度扩张卷积从一个输入特征图中同时捕获多尺度上下文信息,从而提高实时语义分割的特征提取效率。 然而,这种设计可能会因为结构和超参数的不合理而导致多尺度上下文信息的访问困难。 为了降低多尺度上下文信息的绘制难度,我们提出了一种高效的多尺度特征提取方法,将原始的单步方法分解为区域残差-语义残差两个步骤。 在该方法中,多速率深度扩张卷积

YOLOv10改进 | Conv篇 |YOLOv10引入SPD-Conv卷积
1. SPD-Conv介绍 1.1 摘要:卷积神经网络(CNN)在图像分类和目标检测等许多计算机视觉任务中取得了巨大的成功。 然而,在图像分辨率较低或物体较小的更艰巨的任务中,它们的性能会迅速下降。 在本文中,我们指出,这源于现有 CNN 架构中一个有缺陷但常见的设计,即使用跨步卷积和/或池化层,这会导致细粒度信息的丢失和学习效率较低的特征表示 。 为此,我们提出了一种名为 SPD-Conv

YOLOv8改进 | 卷积模块 | 用坐标卷积CoordConv替换Conv
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 专栏目录:《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有40+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进 CoordConv 是一种针对卷积神经网络(CNNs)的改进方法,旨在解决传统卷积在处理空间位置信息时的局限性。CoordConv 通过向卷积层
![【YOLOv8改进[CONV]】使用MSBlock二次创新C2f模块实现轻量化 + 含全部代码和详细修改方式 + 手撕结构图 + 轻量化 + 涨点](https://img-blog.csdnimg.cn/direct/8d649bf7673c4feb8ee5a9aecf11c909.png)
【YOLOv8改进[CONV]】使用MSBlock二次创新C2f模块实现轻量化 + 含全部代码和详细修改方式 + 手撕结构图 + 轻量化 + 涨点
本文将使用MSBlock二次创新C2f模块实现轻量化,助力YOLOv8目标检测效果的实践,文中含全部代码、详细修改方式以及手撕结构图。助您轻松理解改进的方法,实现有效涨点。 改进前和改进后的参数对比: 目录 一 MSBlock 二 使用MSBlock二次创新C2f模块实现轻量化 1 整体修改 ① 添加C2f_MSBlock.py文件 ② 修改ultralytics/nn/task
![【YOLOv10改进[CONV]】使用DualConv二次创新C2f模块实现轻量化 + 含全部代码和详细修改方式 + 手撕结构图 + 全网首发](https://img-blog.csdnimg.cn/direct/bfd81518969c4589841d99649a2e132f.png)
【YOLOv10改进[CONV]】使用DualConv二次创新C2f模块实现轻量化 + 含全部代码和详细修改方式 + 手撕结构图 + 全网首发
本文将使用DualConv二次创新C2f模块实现轻量化,助力YOLOv10目标检测效果的实践,文中含全部代码、详细修改方式以及手撕结构图。助您轻松理解改进的方法。 改进前和改进后的参数对比: 目录 一 DualConv 1 结合3×3卷积和1×1卷积核 2 DualConv 3 可视化 二 C2f_DualConv助力YOLOv10轻量化 1 整体修改 ① 添加C2f
![【YOLOv8改进[CONV]】SPDConv助力YOLOv8目标检测效果 + 含全部代码和详细修改方式 + 手撕结构图](https://img-blog.csdnimg.cn/direct/903b12dde8914e6e968782bc23431980.png)
【YOLOv8改进[CONV]】SPDConv助力YOLOv8目标检测效果 + 含全部代码和详细修改方式 + 手撕结构图
本文将使用SPDConv助力YOLOv8目标检测效果的实践,文中含全部代码、详细修改方式以及手撕结构图。助您轻松理解改进的方法。 改进前和改进后的参数对比: 目录 一 SPDConv 二 SPDConv助力YOLOv8目标检测效果 1 整体修改 ① 添加SPDConv.py文件 ② 修改ultralytics/nn/tasks.py文件 2 配置文件 3 训练 一
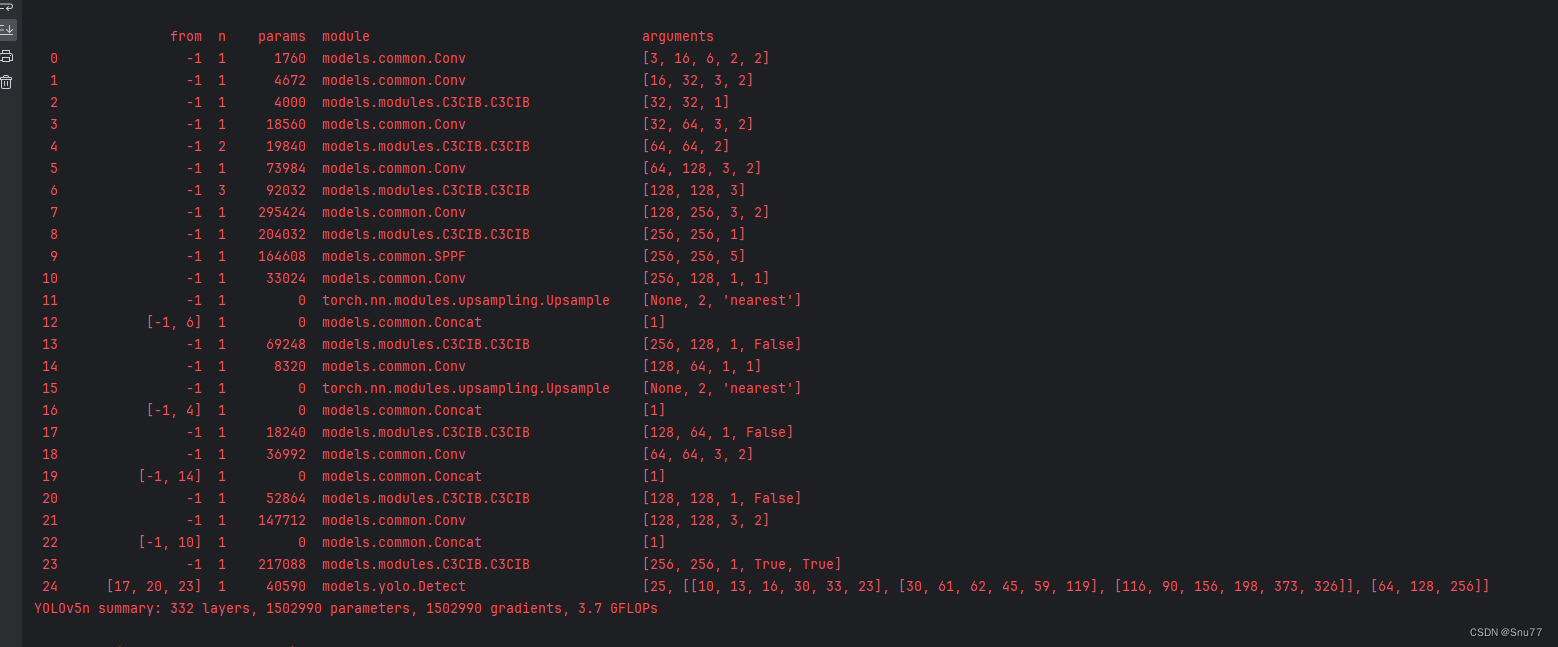
YOLOv5改进 | Conv篇 | 利用YOLOv10提出的UIB模块二次创新C3(附代码 + 完整修改教程)
一、本文介绍 本文给大家带来的改进机制是利用利用YOLOv10提出的UIB模块二次创新C3助力YOLOv5进行有效涨点,其中C2fUIB模块所用到的CIB模块是一种紧凑的倒置块结构,它采用廉价的深度卷积进行空间混合,并采用成本效益高的点卷积进行通道混合。本文针对该方法给出多种使用方法,大家可以根据自己的数据集来针对性的使用,同时本文附C3UIB网络结构图! 欢迎大家订阅我的专栏一起学习YOL

深入解析 YOLOv8 中的 `conv.py`(代码图文全解析-下)
😎 作者介绍:我是程序员行者孙,一个热爱分享技术的制能工人。计算机本硕,人工制能研究生。公众号:AI Sun,视频号:AI-行者Sun 🎈 本文专栏:本文收录于《yolov8》系列专栏,相信一份耕耘一份收获,我会详细的分享yolo系列目标检测详细知识点,yolov1到yolov9全系列,不说废话,祝大家早日中稿cvpr 🤓 欢迎大家关注其他专栏,我将分享Web前后端开发、人工智能、机器学习
![【YOLOv8改进[Conv]】使用YOLOv9中的Adown模块改进Conv模块的实践 + 含全部代码和修改方式 + 有效涨点](/front/images/it_default2.jpg)
【YOLOv8改进[Conv]】使用YOLOv9中的Adown模块改进Conv模块的实践 + 含全部代码和修改方式 + 有效涨点
本文中进行使用YOLOv9中的Adown模块改进Conv模块的实践 ,文中包含全部代码和修改方式 ,有效涨点。 目录 一 YOLOv9 1 信息丢失问题 2 PGI ① 信息瓶颈 ② 可逆函数<
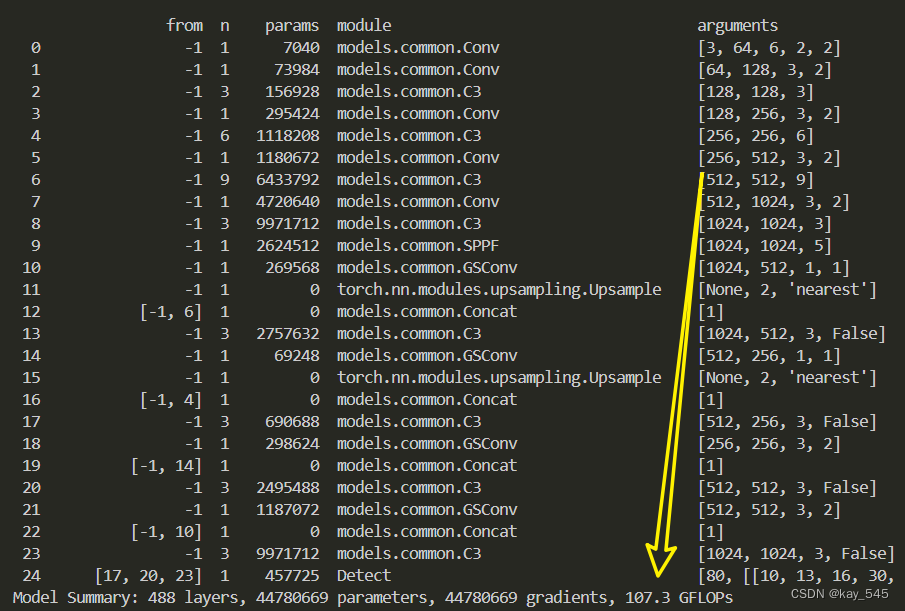
YOLOv5改进 | 卷积模块 | 将Conv替换为轻量化的GSConv【原理 + 完整代码】
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 目标检测是计算机视觉中一个重要的下游任务。对于边缘盒子的计算平台来说,一个大型模型很难实现实时检测的要求。而且,一个由大量深度可分离卷积层构建的轻量级模型无法达到足够的准确度。我们引入了一种新的轻量级卷积技术GSConv,以减轻模型但保持准确性。GSConv在模型的准确性和速度之间实现了优秀的权衡。在本文中,给大家带来的教程是将原来的
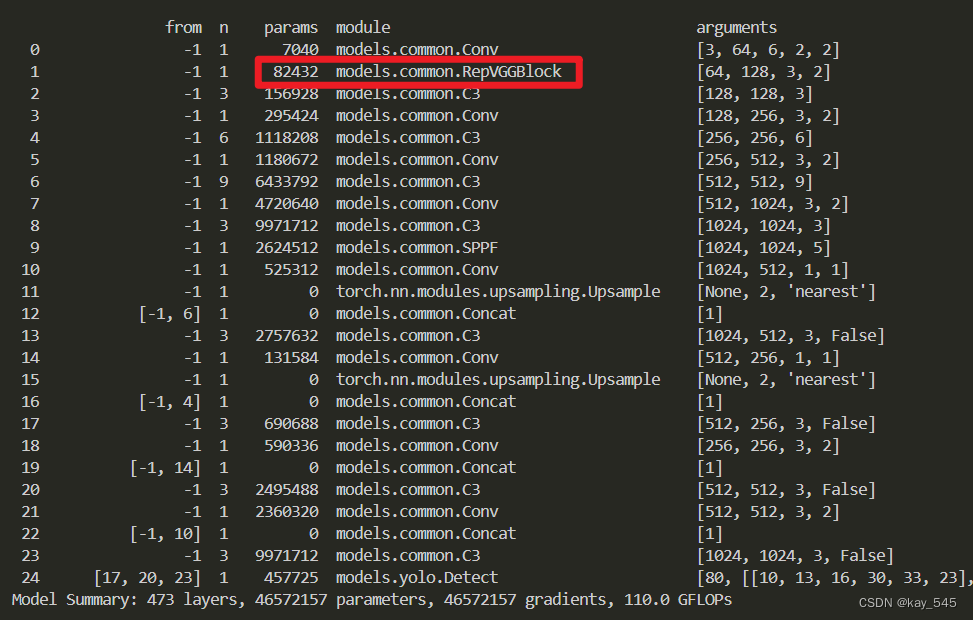
YOLOv5改进 | 主干网络 | 用repvgg模块替换Conv【教程+代码 】
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 尽管Ultralytics 推出了最新版本的 YOLOv8 模型。但YOLOv5作为一个anchor base的目标检测的算法,YOLOv5可能比YOLOv8的效果更好。注意力机制是提高模型性能最热门的方法之一,本文给大家带来的教程是将YOLOv5的backbone的Conv用repvgg模块替换来提取特征。文章在介绍主要的原理后,将
详细讲一下PYG 里面的torch_geometric.nn.conv.transformer_conv函数
1.首先先讲一下代码 这是官方给的代码:torch_geometric.nn.conv.transformer_conv — pytorch_geometric documentation import mathimport typingfrom typing import Optional, Tuple, Unionimport torchimport torch.nn.functio
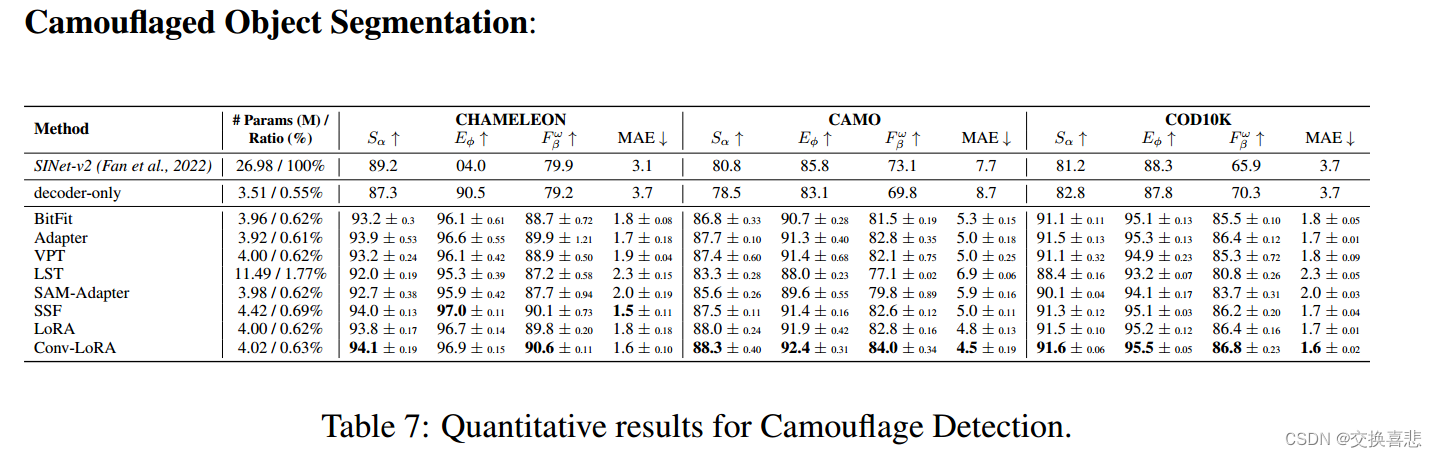
伪装目标检测论文阅读 SAM大模型之参数微调:Conv LoRA
paper:link code:还没公开 摘要 任意分割模型(SAM)是图像分割的基本框架。虽然它在典型场景中表现出显著的零镜头泛化,但当应用于医学图像和遥感等专门领域时,其优势就会减弱。针对这一局限性,本文提出了一种简单有效的参数高效微调方法Conv-Lora。通过将超轻量级卷积参数集成到低阶自适应(LORA)中,Conv-LoRa可以在普通VIT编码器中注入与图像相关的感应偏差,进一步
![【YOLOv9改进[Conv]】使用DualConv助力V9更优秀](https://img-blog.csdnimg.cn/direct/b8552b99a7b94f4c9c0f915472901564.png)
【YOLOv9改进[Conv]】使用DualConv助力V9更优秀
目录 一 DualConv(2022) 1 结合3×3卷积和1×1卷积核 2 DualConv 3 可视化 二 使用DualConv助力V9更优秀 1 整体修改 2 配置文件 3 训练 一 DualConv(2022) 官方论文地址:https://arxiv.org/pdf/2202.07481.pdf 论文中提出了结合3×3组卷积和1×1点卷积的DualConv,

YOLOv8改进 | Conv篇 | CVPR2024最新DynamicConv替换下采样(包含C2f创新改进,解决低FLOPs陷阱)
一、本文介绍 本文给大家带来的改进机制是CVPR2024的最新改进机制DynamicConv其是CVPR2024的最新改进机制,这个论文中介绍了一个名为ParameterNet的新型设计原则,它旨在在大规模视觉预训练模型中增加参数数量,同时尽量不增加浮点运算(FLOPs),所以本文的DynamicConv被提出来了,使得网络在保持低FLOPs的同时增加参数量,从而允许这些网络从大规模视觉预训练中
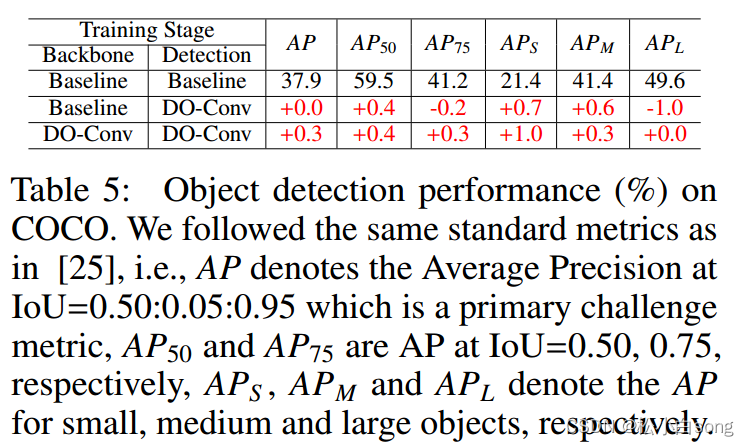
即插即用模块之DO-Conv(深度过度参数化卷积层)详解
目录 一、摘要 二、核心创新点 三、代码详解 四、实验结果 4.1Image Classification 4.2Semantic Segmentation 4.3Object Detection 五、总结 论文:DOConv论文 代码:DOConv代码 一、摘要 卷积层是卷积神经网络(cnn)的核心组成部分。在本文中,我们建议用额外的深度卷积来增强卷积层,其
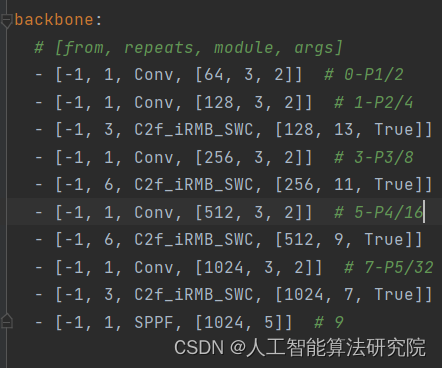
YOLOv8算法改进【NO.111】利用shift-wise conv对顶会提出EMO中的iRMB进行二次创新
前 言 YOLO算法改进系列出到这,很多朋友问改进如何选择是最佳的,下面我就根据个人多年的写作发文章以及指导发文章的经验来看,按照优先顺序进行排序讲解YOLO算法改进方法的顺序选择。具体有需求的同学可以私信我沟通: 首推,是将两种最新推出算法的模块进行融合形成最为一种新型自己提出的模块然后引入到YOLO算法中,可以起个新的名字,这种改进是最好发高水平期刊论文。后续改进将主要教大
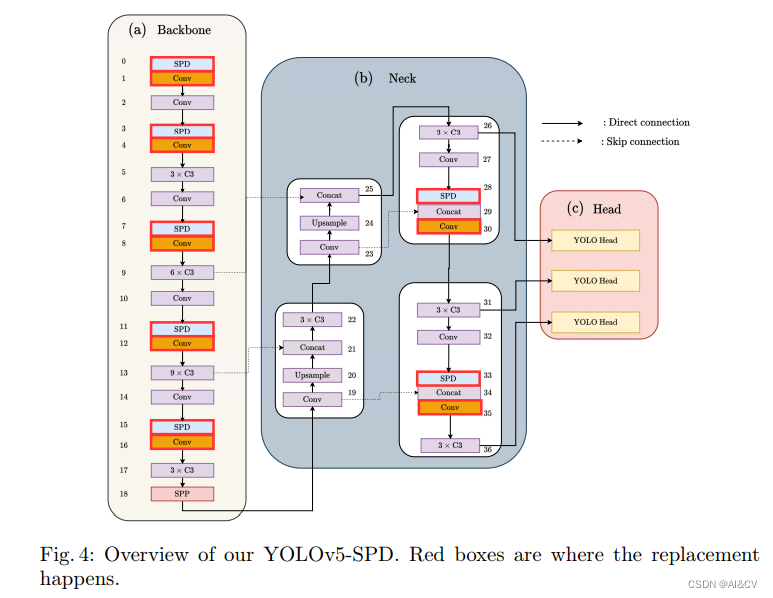
YOLOv9改进策略:卷积魔改 | SPD-Conv,低分辨率图像和小物体涨点明显
💡💡💡本文改进内容:SPD-Conv由一个空间到深度(SPD)层和一个无卷积步长(Conv)层组成,特别是在处理低分辨率图像和小物体等更困难的任务时。 💡💡💡SPD-Conv在多个数据集验证能够暴力涨点,适合急需要涨点的项目 YOLOv9魔术师专栏 ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁

MATLAB的函数conv()用法
例1、计算两个表达式0.03x+1和0.0025x+1的乘积展开式,就可以使用该函数计算? 编程如下: u=[0.03,1]; v=[0.0025,1]; w=conv(u,v); 运行结果: w = 0.0001 0.0325 1.0000 例2、计算两个表达式2x+1和x+1的乘积展开式(或者说是怎么表达)? 编程如下: u=[2,1]; v=[1,1

芒果YOLOv8改进106:卷积Conv篇:DO-DConv卷积提高性能涨点,使用over-parameterized卷积层提高CNN性能
芒果YOLOv8改进106:卷积Conv篇:DO-DConv卷积提高性能涨点,使用over-parameterized卷积层提高CNN性能 💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可 该专栏完整目录链接: 芒果YOLOv8深度改进教程 文章目录 DO-DConv论文理论部分 + 原创最新改进 YOLOv8 代码实践改进基本原理 部分实
![[转载] Conv Nets: A Modular Perspective](http://colah.github.io/posts/2014-07-Conv-Nets-Modular/img/Conv2-5x5-Conv2-XY.png)
[转载] Conv Nets: A Modular Perspective
原文地址:http://colah.github.io/posts/2014-07-Conv-Nets-Modular/ Conv Nets: A Modular Perspective Posted on July 8, 2014 neural networks, deep learning, convolutional neural networks, modular neural ne

yolo模型中神经节点Mul与Sigmoid 和 Conv、Concat、Add、Resize、Reshape、Transpose、Split
yolo模型中神经节点Mul与Sigmoid 和 Conv、Concat、Add、Resize、Reshape、Transpose、Split 在YOLO(You Only Look Once)模型中,具体作用和用途的解释:
物体检测-系列教程22:YOLOV5 源码解析12 (BottleneckCSP类、Conv类、Bottleneck类)
😎😎😎物体检测-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 点我下载源码 16、BottleneckCSP类 16.1 BottleneckCSP类 位置:yolov5/models/common.py/BottleneckCSP类 CSP Bottleneck 项目地址 CSP (Cross S
yolov7添加spd-conv注意力机制
一、spd-conv是什么? SPD-Conv(Symmetric Positive Definite Convolution)是一种新颖的卷积操作,它主要应用于处理对称正定矩阵(SPD)数据。在传统的卷积神经网络(CNN)中,卷积操作通常用于处理图像数据,而SPD-Conv的引入则将卷积扩展到了处理更加复杂的数据结构,例如在计算机视觉、医学影像分析和材料科学等领域中广泛存在的对称正定矩阵数据
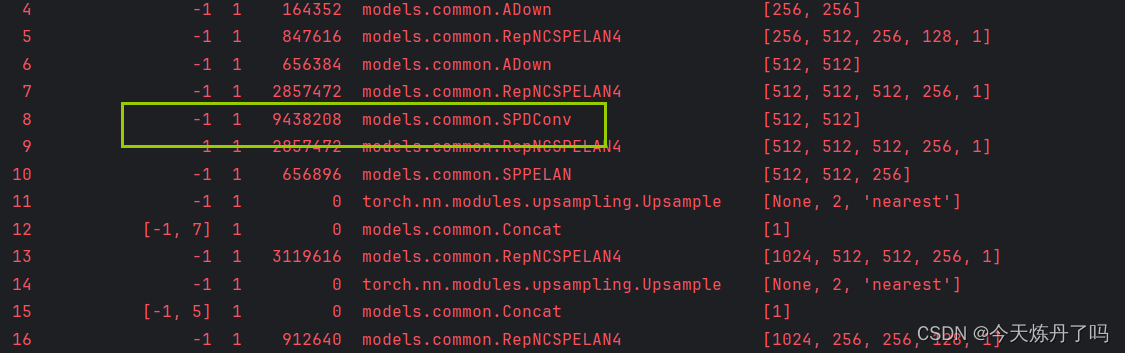
YOLOv9独家原创改进|增加SPD-Conv无卷积步长或池化:用于低分辨率图像和小物体的新 CNN 模块
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!! 一、文章摘要 卷积神经网络(CNNs)在计算即使觉任务中如图像分类和目标检测等取得了显著的成功。然而,当图像分辨率较低或物体较小时,它们的性能会灾难性下降。这是由于现有CNN常见的设计体系结构中有缺陷,即使用卷积步长和/或池化层,这导致了细粒度信息的丢失和较低效的特征表示的学习。为此,