本文主要是介绍即插即用模块之DO-Conv(深度过度参数化卷积层)详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、摘要
二、核心创新点
三、代码详解
四、实验结果
4.1Image Classification
4.2Semantic Segmentation
4.3Object Detection
五、总结

论文:DOConv论文
代码:DOConv代码
一、摘要
卷积层是卷积神经网络(cnn)的核心组成部分。在本文中,我们建议用额外的深度卷积来增强卷积层,其中每个输入通道与不同的二维核进行卷积。这两个卷积的组合构成了一个过度参数化,因为它增加了可学习的参数,而结果的线性操作可以用单个卷积层来表示。我们把这个深度过度参数化的卷积层称为DO-Conv。我们通过大量的实验表明,仅仅用DO-Conv层替换传统的卷积层就可以提高cnn在许多经典视觉任务上的性能,例如图像分类、检测和分割。此外,在推理阶段,深度卷积被折叠成常规卷积,将计算量减少到完全等同于卷积层的计算量,而没有过度参数化。由于DO-Conv在不增加推理计算复杂度的情况下引入了性能提升,我们主张将其作为传统卷积层的替代方案。
二、核心创新点
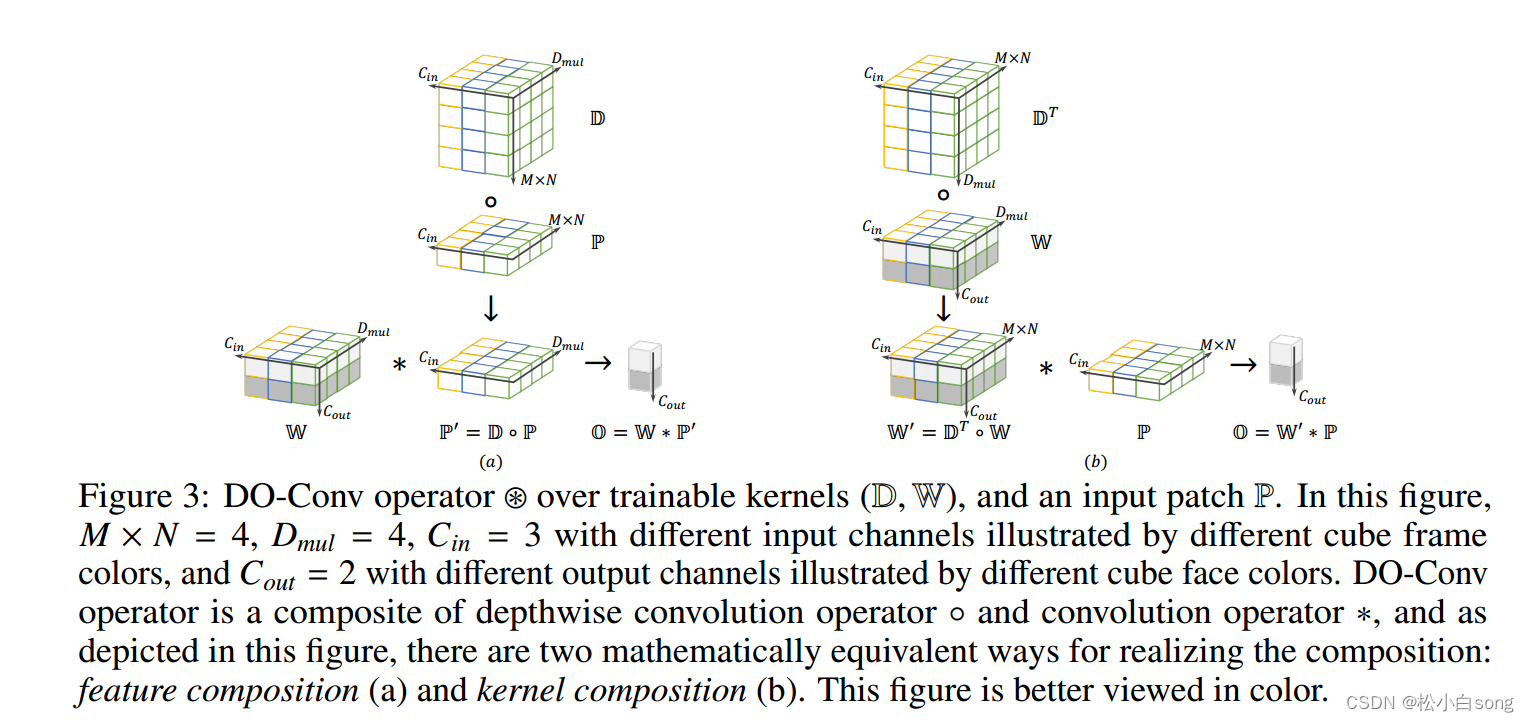
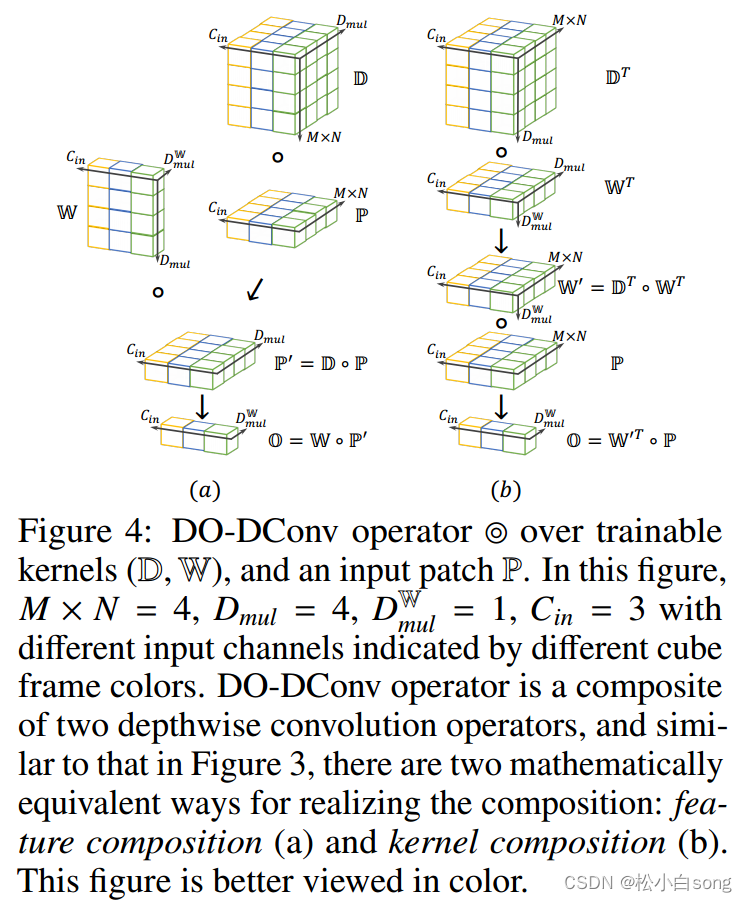
深度过参数化卷积层(DO-Conv)是一个具有可训练kernel深度卷积和一个具有可训练常规卷积的组合。给定一个输入, DO-Conv算子的输出与卷积层相同,是一个同维特征。DO-Conv算子是深度卷积算子和卷积算子的复合,如图所示,有两种数学上等价的方法来实现复合:特征复合(a)和核复合(b)。
三、代码详解
# 使用 utf-8 编码
# 导入必要的库
import math # 导入数学库
import torch # 导入 PyTorch 库
import numpy as np # 导入 NumPy 库
from torch.nn import init # 导入 PyTorch 中的初始化函数
from itertools import repeat # 导入 itertools 库中的 repeat 函数
from torch.nn import functional as F # 导入 PyTorch 中的函数式接口
from torch._jit_internal import Optional # 导入 PyTorch 中的可选模块
from torch.nn.parameter import Parameter # 导入 PyTorch 中的参数类
from torch.nn.modules.module import Module # 导入 PyTorch 中的模块类
import collections # 导入 collections 库# 定义自定义模块 DOConv2d
class DOConv2d(Module):"""DOConv2d 可以作为 torch.nn.Conv2d 的替代。接口与 Conv2d 类似,但有一个例外:1. D_mul:超参数的深度乘法器。请注意,groups 参数在 DO-Conv(groups=1)、DO-DConv(groups=in_channels)、DO-GConv(其他情况)之间切换。"""# 常量声明__constants__ = ['stride', 'padding', 'dilation', 'groups','padding_mode', 'output_padding', 'in_channels','out_channels', 'kernel_size', 'D_mul']# 注解声明__annotations__ = {'bias': Optional[torch.Tensor]}# 初始化函数def __init__(self, in_channels, out_channels, kernel_size, D_mul=None, stride=1,padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros'):super(DOConv2d, self).__init__()# 将 kernel_size、stride、padding、dilation 转化为二元元组kernel_size = _pair(kernel_size)stride = _pair(stride)padding = _pair(padding)dilation = _pair(dilation)# 检查 groups 是否合法if in_channels % groups != 0:raise ValueError('in_channels 必须能被 groups 整除')if out_channels % groups != 0:raise ValueError('out_channels 必须能被 groups 整除')# 检查 padding_mode 是否合法valid_padding_modes = {'zeros', 'reflect', 'replicate', 'circular'}if padding_mode not in valid_padding_modes:raise ValueError("padding_mode 必须为 {} 中的一种,但得到 padding_mode='{}'".format(valid_padding_modes, padding_mode))# 初始化模块参数self.in_channels = in_channelsself.out_channels = out_channelsself.kernel_size = kernel_sizeself.stride = strideself.padding = paddingself.dilation = dilationself.groups = groupsself.padding_mode = padding_modeself._padding_repeated_twice = tuple(x for x in self.padding for _ in range(2))#################################### 初始化 D & W ###################################M = self.kernel_size[0]N = self.kernel_size[1]self.D_mul = M * N if D_mul is None or M * N <= 1 else D_mulself.W = Parameter(torch.Tensor(out_channels, in_channels // groups, self.D_mul))init.kaiming_uniform_(self.W, a=math.sqrt(5))if M * N > 1:self.D = Parameter(torch.Tensor(in_channels, M * N, self.D_mul))init_zero = np.zeros([in_channels, M * N, self.D_mul], dtype=np.float32)self.D.data = torch.from_numpy(init_zero)eye = torch.reshape(torch.eye(M * N, dtype=torch.float32), (1, M * N, M * N))d_diag = eye.repeat((in_channels, 1, self.D_mul // (M * N)))if self.D_mul % (M * N) != 0: # 当 D_mul > M * N 时zeros = torch.zeros([in_channels, M * N, self.D_mul % (M * N)])self.d_diag = Parameter(torch.cat([d_diag, zeros], dim=2), requires_grad=False)else: # 当 D_mul = M * N 时self.d_diag = Parameter(d_diag, requires_grad=False)################################################################################################### 初始化偏置参数if bias:self.bias = Parameter(torch.Tensor(out_channels))fan_in, _ = init._calculate_fan_in_and_fan_out(self.W)bound = 1 / math.sqrt(fan_in)init.uniform_(self.bias, -bound, bound)else:self.register_parameter('bias', None)# 返回模块配置的字符串表示形式def extra_repr(self):s = ('{in_channels}, {out_channels}, kernel_size={kernel_size}'', stride={stride}')if self.padding != (0,) * len(self.padding):s += ', padding={padding}'if self.dilation != (1,) * len(self.dilation):s += ', dilation={dilation}'if self.groups != 1:s += ', groups={groups}'if self.bias is None:s += ', bias=False'if self.padding_mode != 'zeros':s += ', padding_mode={padding_mode}'return s.format(**self.__dict__)# 重新设置状态def __setstate__(self, state):super(DOConv2d, self).__setstate__(state)if not hasattr(self, 'padding_mode'):self.padding_mode = 'zeros'# 辅助函数,执行卷积操作def _conv_forward(self, input, weight):if self.padding_mode != 'zeros':return F.conv2d(F.pad(input, self._padding_repeated_twice, mode=self.padding_mode),weight, self.bias, self.stride,_pair(0), self.dilation, self.groups)return F.conv2d(input, weight, self.bias, self.stride,self.padding, self.dilation, self.groups)# 前向传播函数def forward(self, input):M = self.kernel_size[0]N = self.kernel_size[1]DoW_shape = (self.out_channels, self.in_channels // self.groups, M, N)if M * N > 1:######################### 计算 DoW ################## (input_channels, D_mul, M * N)D = self.D + self.d_diagW = torch.reshape(self.W, (self.out_channels // self.groups, self.in_channels, self.D_mul))# einsum 输出 (out_channels // groups, in_channels, M * N),# 重塑为# (out_channels, in_channels // groups, M, N)DoW = torch.reshape(torch.einsum('ims,ois->oim', D, W), DoW_shape)#######################################################else:# 在这种情况下 D_mul == M * N# 从 (out_channels, in_channels // groups, D_mul) 重塑为 (out_channels, in_channels // groups, M, N)DoW = torch.reshape(self.W, DoW_shape)return self._conv_forward(input, DoW)# 定义辅助函数
def _ntuple(n):def parse(x):if isinstance(x, collections.abc.Iterable):return xreturn tuple(repeat(x, n))return parse# 定义辅助函数,将输入转化为二元元组
_pair = _ntuple(2)
四、实验结果
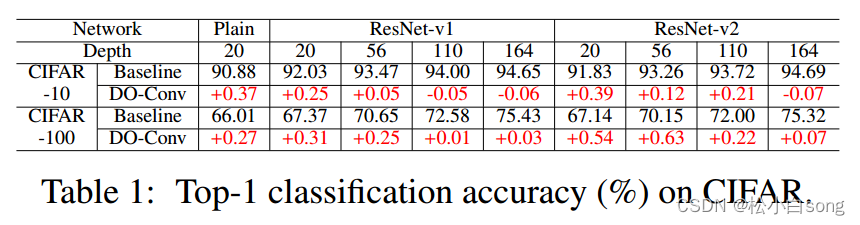
4.1Image Classification


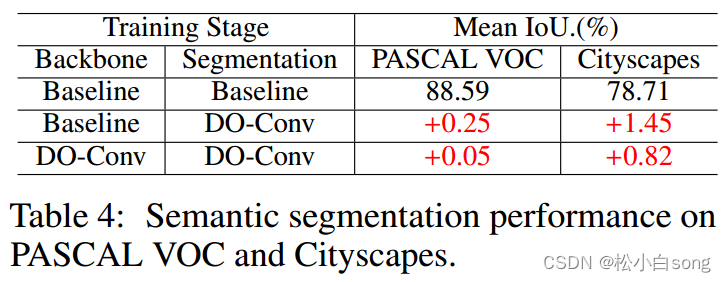
4.2Semantic Segmentation
4.3Object Detection
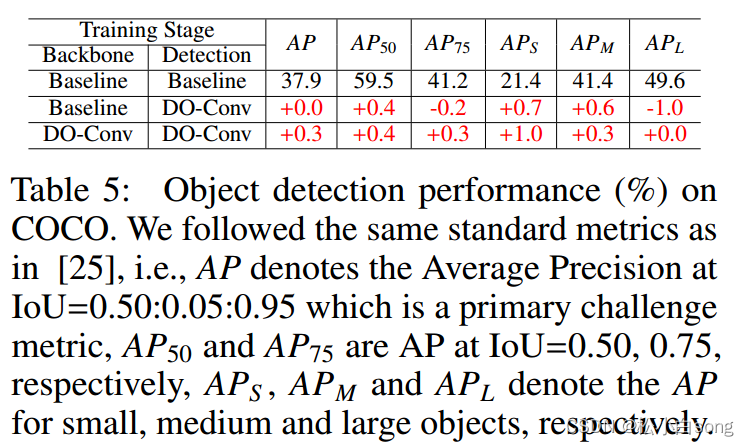
五、总结
DO-Conv是一种深度过参数化卷积层,是一种新颖、简单、通用的提高cnn性能的方法。除了提高现有cnn的训练和最终精度的实际意义之外,在推理阶段不引入额外的计算,我们设想其优势的揭示也可以鼓励进一步探索过度参数化作为网络架构设计的一个新维度。
在未来,对这一相当简单的方法进行理论理解,以在一系列应用中实现令人惊讶的非凡性能改进,将是有趣的。此外,我们希望扩大这些过度参数化卷积层可能有效的应用范围,并了解哪些超参数可以从中受益更多。
这篇关于即插即用模块之DO-Conv(深度过度参数化卷积层)详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



