本文主要是介绍深入解析 YOLOv8 中的 `conv.py`(代码图文全解析-下),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
😎 作者介绍:我是程序员行者孙,一个热爱分享技术的制能工人。计算机本硕,人工制能研究生。公众号:AI Sun,视频号:AI-行者Sun
🎈
本文专栏:本文收录于《yolov8》系列专栏,相信一份耕耘一份收获,我会详细的分享yolo系列目标检测详细知识点,yolov1到yolov9全系列,不说废话,祝大家早日中稿cvpr
🤓 欢迎大家关注其他专栏,我将分享Web前后端开发、人工智能、机器学习、深度学习从0到1系列文章。 🖥
随时欢迎您跟我沟通,一起交流,一起成长、进步!
YOLO目标检测框架中的conv.py文件包含作用:
-
构建卷积网络:
conv.py文件定义了YOLO模型中使用的卷积层,这些层负责从输入图像中提取特征。它包括设置卷积核、步长(stride)、填充(padding)等参数,以及可能的批量归一化层和激活函数,如ReLU。 -
特征提取与处理:该文件实现了对输入图像进行特征提取和处理的整个流程。通过堆叠多个卷积层,YOLO能够学习从简单到复杂的特征表示,这对于目标检测至关重要。
-
网络配置与灵活性:
conv.py通常还提供了一种灵活的方式,用于配置网络结构,允许研究人员和开发者根据特定应用调整网络的深度和复杂性。此外,它可能包含用于初始化网络权重的函数,这对于训练过程和最终模型性能非常重要。
以下是使用Mermaid语法编写的YOLO conv.py构建流程图的一个修正和简化版本:
- 初始化网络:设置网络的基本参数。
- 配置卷积层:定义每个卷积层的属性。
- 多层:决定是否重复配置多层网络结构。
- 构建网络:根据配置构建整个网络。
- 特征提取:通过卷积层提取图像特征。
- 特征融合:将不同层的特征图进行融合。
- 边界框预测:在网络的最后进行边界框的预测。
- 添加层:如果需要多层,可以选择添加的层类型。
- 选择层类型:选择要添加的层是卷积层、激活层还是归一化层。
注意力机制模块
注意力机制可以帮助模型集中于图像中的关键区域,提高检测精度。
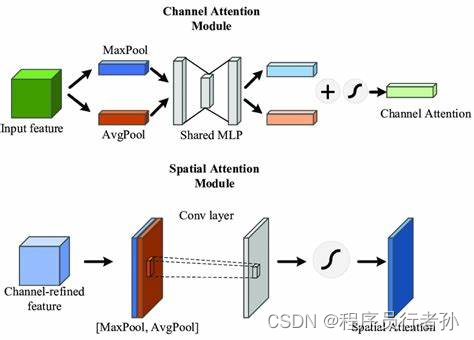
1. ChannelAttention 和 SpatialAttention 类
这两个类分别实现了通道注意力和空间注意力机制。它们通过学习通道和空间维度上的权重,增强了模型对特征的响应能力。
ChannelAttention 和 SpatialAttention 是两种常见的注意力机制,它们分别关注于特征图(feature maps)的通道(channel-wise)和空间(spatial-wise)信息。这些机制通常用于卷积神经网络(CNN)中,以增强模型对输入数据的特定部分的关注度,从而提高性能。
ChannelAttention
ChannelAttention,也称为通道注意力或特征通道注意力,专注于平衡不同通道的特征响应。这种注意力机制通常与SENet(Squeeze-and-Excitation Networks)中的SE块相关联。
工作原理:
-
Squeeze:通过全局平均池化(Global Average Pooling, GAP)将特征图的所有空间信息压缩成一个单一的通道响应。
-
Excitation:通过两层全连接(FC)层和激活函数ReLU及Sigmoid获取权重,这些权重用于重新加权原始特征图的每个通道。
代码示例:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ChannelAttention(nn.Module):def __init__(self, in_channels, reduction_ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),nn.ReLU(),nn.Linear(in_channels // reduction_ratio, in_channels, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()avg_out = self.fc(self.avg_pool(x).view(b, c))out = x * avg_out.expand_as(x)return out
SpatialAttention
SpatialAttention,也称为空间注意力,关注于特征图中的空间信息,允许模型专注于输入图像的特定区域。
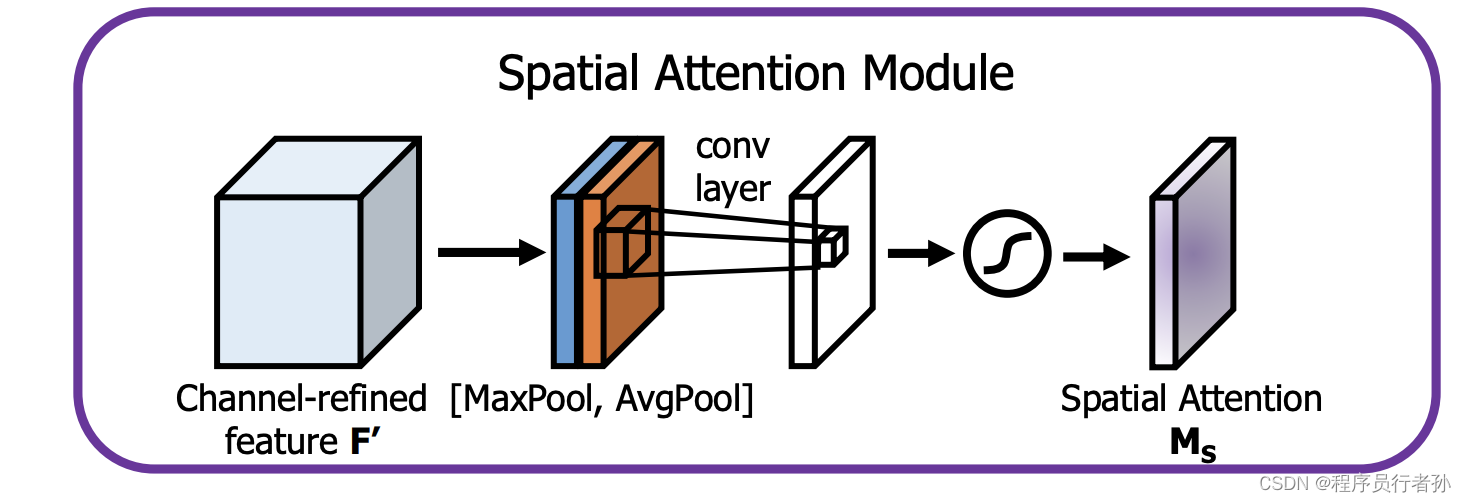
工作原理:
- 创建空间特征:使用卷积层创建空间特征图。
- 获取权重:通过激活函数(如softmax)对每个位置分配权重,通常在高度和宽度维度上独立应用。
代码示例:
class SpatialAttention(nn.Module):def __init__(self):super(SpatialAttention, self).__init__()self.conv1 = nn.Conv2d(2, 1, kernel_size=7, padding=3)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)x = torch.cat([avg_out, max_out], dim=1)x = self.conv1(x)x = self.sigmoid(x)return x * x
SpatialAttention类首先计算平均池化和最大池化来获取空间特征,然后通过一个卷积层和sigmoid激活函数来获取空间注意力权重,最后将这些权重应用于原始特征图。
2. CBAM 类
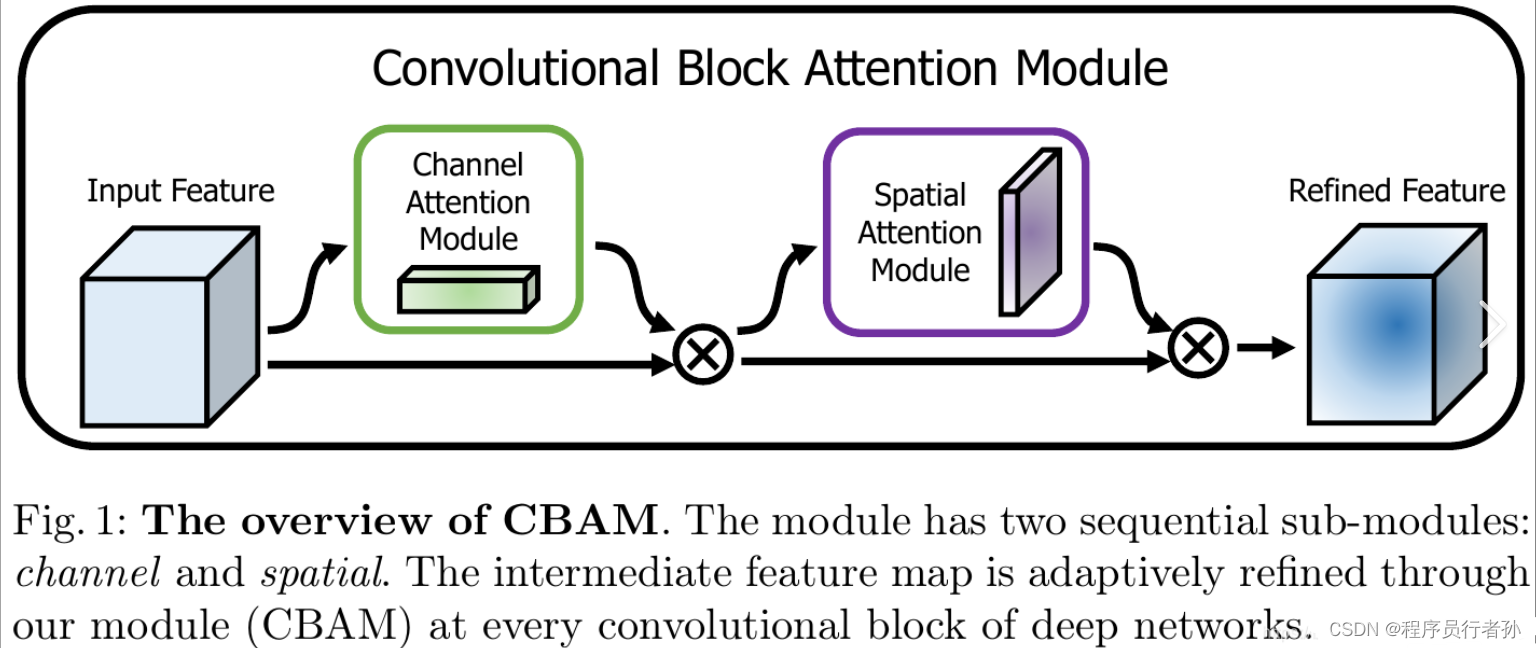
CBAM 类结合了通道注意力和空间注意力,提供了一种更全面的注意力机制,能够同时考虑通道和空间信息。
CBAM(Convolutional Block Attention Module)是一种集成了Channel Attention和Spatial Attention的注意力机制,用于增强卷积神经网络的特征表示能力。CBAM通过分别对通道和空间维度进行加权,使网络能够更加关注于重要的特征并忽略无关的特征。
CBAM的主要组件:
-
Channel Attention:
- 使用全局平均池化(GAP)和两层全连接(FC)层来学习通道间的相关性。
- 通过Sigmoid激活函数生成每个通道的权重。
-
Spatial Attention:
- 使用深度卷积(Depthwise Convolution)来学习空间位置间的相关性。
- 通过逐点卷积(Pointwise Convolution)和softmax激活函数生成每个位置的权重。
CBAM的工作流程:
- 卷积块:输入特征首先通过一个卷积块进行特征提取。
- Channel Attention:
- 应用GAP来聚合空间信息。
- 使用FC层和ReLU激活函数进行非线性变换。
- 使用第二个FC层和Sigmoid激活函数生成通道权重。
- Spatial Attention:
- 使用深度卷积来聚合通道信息。
- 使用逐点卷积来生成空间权重图。
- 应用softmax激活函数来获取归一化的权重。
- 组合注意力:将通道注意力和空间注意力的权重分别应用于输入特征的通道和空间维度。
代码示例:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ChannelAttention(nn.Module):def __init__(self, in_channels, reduction_ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),nn.ReLU(),nn.Linear(in_channels // reduction_ratio, in_channels, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()avg_out = self.fc(self.avg_pool(x).view(b, c))return avg_out.unsqueeze(2).unsqueeze(3).expand_as(x) * xclass SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()self.conv1 = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size//2)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)x = torch.cat([avg_out, max_out], dim=1)x = self.conv1(x)return self.sigmoid(x)class CBAM(nn.Module):def __init__(self, in_channels, reduction_ratio=16, kernel_size=49):super(CBAM, self).__init__()self.channel_attention = ChannelAttention(in_channels, reduction_ratio)self.spatial_attention = SpatialAttention(kernel_size)def forward(self, x):x = self.channel_attention(x) * self.spatial_attention(x)return x
ChannelAttention和SpatialAttention类分别实现了通道注意力和空间注意力机制,而CBAM类将它们结合起来,形成了完整的CBAM模块。通过这种方式,CBAM可以显著提升CNN模型的性能,特别是在处理复杂视觉任务时。
其他辅助模块
除了核心卷积和注意力机制外,conv.py 还包含了一些辅助模块,如 Focus、GhostConv 和 Concat 等,它们在特定的网络结构中发挥作用。
1. Focus 类
Focus 类用于将宽高维度的信息整合到通道维度,通常用于处理多尺度特征。
-
特征重标定:在SENet(Squeeze-and-Excitation Networks)中,"Focus"指的是通过SE块对特征图进行重标定,以加强重要特征并抑制不重要特征。
-
多尺度特征融合:在一些目标检测网络中,"Focus"是指将不同层级的特征图进行融合,以获得多尺度的特征表示。
import torch
import torch.nn as nnclass Focus(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0):super(Focus, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False)self.bn = nn.BatchNorm2d(out_channels)def forward(self, x):# 假设输入x是一个特征图# 应用卷积和批量归一化x = self.conv(x)x = self.bn(x)return x
这个Focus类定义了一个简单的卷积层,后接批量归一化。在实际的YOLO模型中,Focus`可能会更复杂,可能包含特定的特征融合技术或注意力机制。
2. GhostConv 类
GhostConv 类实现了 Ghost Convolution,这是一种有效的特征融合技术,可以在不显著增加参数的情况下增强模型的表示能力。
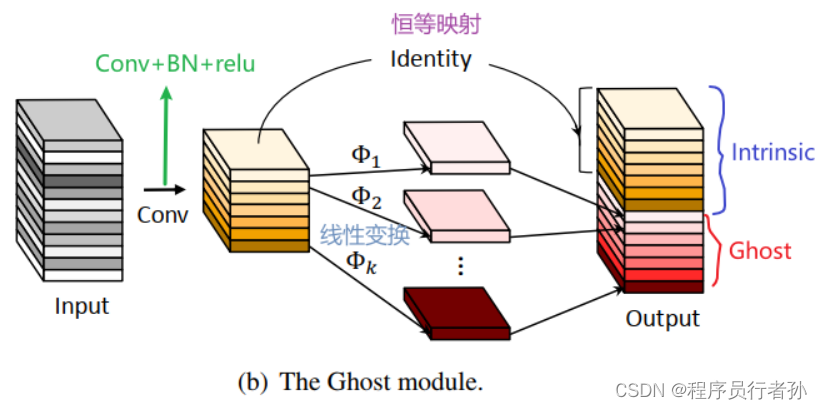
GhostNet是卷积神经网络(CNN)中的一种高效的组件,它通过引入Ghost模块来增加网络的宽度,而不需要显著增加参数数量和计算复杂度。Ghost模块的核心思想是利用廉价的1x1卷积核来生成额外的特征图,这些特征图随后与原始特征图组合,以增加网络的容量。
GhostConv组件:
- 1x1卷积:Ghost模块首先使用1x1的卷积核来生成原始特征图的副本。
- Dilation/Group卷积:然后,这些副本通过带有空洞(dilation)或分组(group)卷积的卷积层进一步处理。
- 特征融合:处理后的特征图与原始特征图合并,以增加特征的多样性。
GhostConv的优势:
- 参数效率:通过1x1卷积生成的特征图共享权重,因此可以以较少的参数增加网络宽度。
- 计算效率:相比传统的卷积层,Ghost模块的计算成本较低。
- 提高性能:增加的宽度可以帮助网络学习更复杂的特征表示,从而提高性能。
代码示例:
import torch
import torch.nn as nnclass GhostConv(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, dilation=1, groups=1):super(GhostConv, self).__init__()# 1x1 卷积核生成额外的特征图self.ghost_ch = out_channels // 2self.conv1 = nn.Conv2d(in_channels, self.ghost_ch, kernel_size=1, stride=1, padding=0, groups=1, bias=False)# 带有空洞或分组卷积的卷积层self.conv2 = nn.Conv2d(self.ghost_ch, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=False)def forward(self, x):# 1x1 卷积x = self.conv1(x)# 空洞/分组卷积x = self.conv2(x)return x# 示例:创建一个GhostConv模块
ghost_conv = GhostConv(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1, dilation=1, groups=1)# 假设有一个输入特征图
input_tensor = torch.randn(1, 64, 56, 56) # 假设batch size为1, 通道数为64, 空间维度为56x56# 前向传播
output_tensor = ghost_conv(input_tensor)
GhostConv类首先通过1x1卷积生成一半数量的输出通道,然后通过一个带有指定参数的卷积层进一步处理这些特征图。生成的特征图与原始输入特征图合并,以增加网络的宽度和容量。
3. Concat 类
Concat 类用于沿指定维度连接多个张量,是构建复杂网络结构时常用的操作。
Concat通常指的是在深度学习和编程中将两个或多个张量(tensors)沿指定的维度连接起来的操作。在PyTorch和TensorFlow等深度学习框架中,Concat操作是构建复杂神经网络模型时的一个常见操作,用于合并特征图(feature maps)或数据。
工作原理:
Concatenation操作沿着指定的维度将多个张量拼接在一起。在图像处理中,这通常用于合并来自不同层的特征图,以便在后续的网络层中一起处理。
代码示例(使用PyTorch):
import torch
import torch.nn as nn# 假设有两个特征图 feature_map1 和 feature_map2,它们具有相同的尺寸
feature_map1 = torch.randn(1, 3, 64, 64) # 假设batch size为1, 通道数为3, 空间维度为64x64
feature_map2 = torch.randn(1, 3, 64, 64)# 使用torch.cat进行拼接,dim=1表示沿通道方向拼接
concatenated_feature_maps = torch.cat((feature_map1, feature_map2), dim=1)# 现在 concatenated_feature_maps 的尺寸是 [1, 6, 64, 64]
# 即通道数从3增加到了6,其他维度保持不变
代码示例(使用TensorFlow):
import tensorflow as tf# 假设有两个特征图 feature_map1 和 feature_map2,它们具有相同的尺寸
feature_map1 = tf.random.normal([1, 64, 64, 3]) # 假设batch size为1, 空间维度为64x64, 通道数为3
feature_map2 = tf.random.normal([1, 64, 64, 3])# 使用tf.concat进行拼接,axis=-1表示沿通道方向拼接(在TensorFlow中,通道是最后一个维度)
concatenated_feature_maps = tf.concat([feature_map1, feature_map2], axis=-1)# 现在 concatenated_feature_maps 的尺寸是 [1, 64, 64, 6]
# 即通道数从3增加到了6,其他维度保持不变
在这两个示例中,我们演示了如何将两个具有相同空间维度的特征图沿通道维度进行拼接。在PyTorch中,torch.cat函数用于拼接张量,而在TensorFlow中,tf.concat函数用于此目的。注意在TensorFlow中通道维度是最后一个维度,而在PyTorch中是第二个维度,这是两个框架在处理图像数据时的一个主要区别。
Concatenation是一种简单但强大的技术,可以增加网络的容量,允许网络同时学习多种特征表示。

祝大家实验顺利,有效涨点~
以上是yolov8的conv.py解析,欢迎评论区留言讨论,如果有用欢迎点赞收藏文章,博主才有动力持续分享笔记!!!
免费资料获取
关注博主公众号,获取更多粉丝福利。
这篇关于深入解析 YOLOv8 中的 `conv.py`(代码图文全解析-下)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




