本文主要是介绍YOLOv5改进 | 卷积模块 | 将Conv替换为轻量化的GSConv【原理 + 完整代码】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
目标检测是计算机视觉中一个重要的下游任务。对于边缘盒子的计算平台来说,一个大型模型很难实现实时检测的要求。而且,一个由大量深度可分离卷积层构建的轻量级模型无法达到足够的准确度。我们引入了一种新的轻量级卷积技术GSConv,以减轻模型但保持准确性。GSConv在模型的准确性和速度之间实现了优秀的权衡。在本文中,给大家带来的教程是将原来的网络中的Conv模块修改为GSConv。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址: YOLOv5改进+入门——持续更新各种有效涨点方法 点击即可跳转
目录
1.原理
2. GSConv、VoVGSCSP代码实现
2.1 将GSConv、VoVGSCSP添加到YOLOv5中
2.2 新增yaml文件
2.3 注册模块
2.4 执行程序
3. 完整代码分享
4. GFLOPs
5. 总结
1.原理

论文地址:Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles——点击即可跳转
官方代码:代码仓库地址——点击即可跳转
Slim-neck by GSConv 是一种基于 GSConv(Grouped Spatial Convolution)的神经网络结构改进技术,主要用于减小模型的计算复杂度和参数量,同时保持或提高模型的性能。以下是对 Slim-neck by GSConv 的详细讲解:
背景和动机
随着深度学习的快速发展,模型的规模和复杂度也在不断增加,这给计算资源带来了巨大的挑战。为了在保证性能的同时减少计算开销,研究人员提出了多种方法,Slim-neck by GSConv 就是其中之一。
GSConv 的基本概念
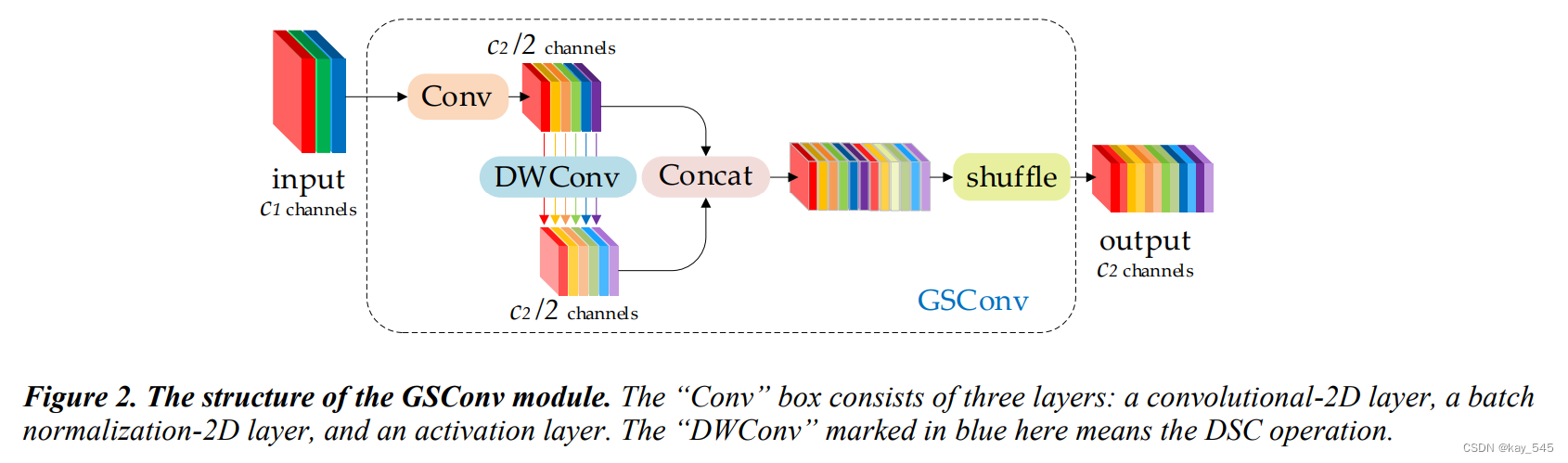
GSConv 是 Grouped Spatial Convolution 的缩写,其核心思想是通过分组卷积(Grouped Convolution)和空间卷积(Spatial Convolution)的结合来减少计算量。具体来说,GSConv 将常规卷积分解为两个步骤:
-
分组卷积(Grouped Convolution):将输入特征图分成若干组,每组分别进行卷积操作。这样可以减少每组卷积的计算量。
-
空间卷积(Spatial Convolution):在每组卷积后的输出上再进行空间卷积操作,以捕捉跨组的特征。
Slim-neck 的改进
Slim-neck 是在 GSConv 的基础上进行的改进,旨在进一步简化模型结构,特别是在网络的颈部(neck)部分。网络的颈部通常是特征提取和特征聚合的关键部分,对模型性能有重要影响。Slim-neck 通过以下几方面进行优化:
-
通道压缩:在网络的颈部部分,采用 GSConv 进行通道压缩,以减少特征图的通道数,从而降低计算量。
-
高效连接:通过引入跳跃连接(skip connection)和高效的连接策略,确保特征信息的有效传递和利用。
-
轻量化设计:在设计上注重轻量化,尽可能减少参数量和计算复杂度,同时保持或提高模型的性能。
Slim-neck by GSConv 的应用
Slim-neck by GSConv 在多种计算资源受限的场景下具有广泛应用,例如:
-
移动设备:由于移动设备的计算资源有限,Slim-neck by GSConv 能够在不显著降低模型性能的前提下,减少计算量和功耗。
-
嵌入式系统:嵌入式系统通常需要在低功耗和有限计算资源下运行,Slim-neck by GSConv 可以提供一种高效的解决方案。
-
实时应用:在需要实时处理的应用场景中,Slim-neck by GSConv 通过减少计算延迟,提高了模型的响应速度。
实验结果与性能
通过在实际任务中的实验,Slim-neck by GSConv 通常能在保持甚至提升模型精度的同时,显著减少计算开销。例如,在图像分类、目标检测等任务中,采用 Slim-neck by GSConv 的模型相较于传统模型,计算量和参数量都有明显减少,同时性能并未显著下降,甚至在某些情况下有所提升。
总结
Slim-neck by GSConv 是一种有效的神经网络优化技术,通过分组卷积和空间卷积的结合,以及在网络颈部部分的优化,达到了降低计算复杂度和参数量的目的,适用于多种计算资源受限的应用场景。
2. GSConv、VoVGSCSP代码实现
2.1 将GSConv、VoVGSCSP添加到YOLOv5中
关键步骤一: 将下面代码粘贴到/projects/yolov5-6.1/models/common.py文件中

class GSConv(nn.Module):# GSConv https://github.com/AlanLi1997/slim-neck-by-gsconvdef __init__(self, c1, c2, k=1, s=1, g=1, act=True):super().__init__()c_ = c2 // 2self.cv1 = Conv(c1, c_, k, s, None, g, act)self.cv2 = Conv(c_, c_, 5, 1, None, c_, act)def forward(self, x):x1 = self.cv1(x)x2 = torch.cat((x1, self.cv2(x1)), 1)# shuffle# y = x2.reshape(x2.shape[0], 2, x2.shape[1] // 2, x2.shape[2], x2.shape[3])# y = y.permute(0, 2, 1, 3, 4)# return y.reshape(y.shape[0], -1, y.shape[3], y.shape[4])b, n, h, w = x2.data.size()b_n = b * n // 2y = x2.reshape(b_n, 2, h * w)y = y.permute(1, 0, 2)y = y.reshape(2, -1, n // 2, h, w)return torch.cat((y[0], y[1]), 1)class GSConvns(GSConv):# GSConv with a normative-shuffle https://github.com/AlanLi1997/slim-neck-by-gsconvdef __init__(self, c1, c2, k=1, s=1, g=1, act=True):super().__init__(c1, c2, k=1, s=1, g=1, act=True)c_ = c2 // 2self.shuf = nn.Conv2d(c_ * 2, c2, 1, 1, 0, bias=False)def forward(self, x):x1 = self.cv1(x)x2 = torch.cat((x1, self.cv2(x1)), 1)# normative-shuffle, TRT supportedreturn nn.ReLU(self.shuf(x2))class VoVGSCSP(nn.Module):# VoVGSCSP module with GSBottleneckdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)# self.gc1 = GSConv(c_, c_, 1, 1)# self.gc2 = GSConv(c_, c_, 1, 1)# self.gsb = GSBottleneck(c_, c_, 1, 1)self.gsb = nn.Sequential(*(GSBottleneck(c_, c_, e=1.0) for _ in range(n)))self.res = Conv(c_, c_, 3, 1, act=False)self.cv3 = Conv(2 * c_, c2, 1) #def forward(self, x):x1 = self.gsb(self.cv1(x))y = self.cv2(x)return self.cv3(torch.cat((y, x1), dim=1))class VoVGSCSPC(VoVGSCSP):# cheap VoVGSCSP module with GSBottleneckdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__(c1, c2)c_ = int(c2 * 0.5) # hidden channelsself.gsb = GSBottleneckC(c_, c_, 1, 1)Slim-neck by GSConv 的主要流程可以分为几个关键步骤
1. 输入特征提取
首先,输入图像通过一个特征提取模块(通常是几个卷积层和池化层的组合),生成初步的特征图。这部分可以使用常见的卷积神经网络(如 ResNet、MobileNet 等)进行处理。
2. 分组卷积(Grouped Convolution)
在特征提取之后,特征图进入分组卷积层:
-
特征图分组:将输入特征图分成若干组,每组包含一部分通道。
-
分组卷积:对每一组分别进行卷积操作。这样可以减少每组卷积的计算量,同时保持局部特征的提取能力。
3. 空间卷积(Spatial Convolution)
在分组卷积之后,进行空间卷积操作:
-
跨组特征融合:通过空间卷积操作,在每组卷积后的输出上进行进一步的卷积,以捕捉跨组的特征。
-
信息整合:空间卷积有助于整合分组卷积后不同组之间的信息,提高特征表达的完整性。
4. 通道压缩(Channel Compression)
在网络的颈部部分,通过 GSConv 进行通道压缩:
-
通道数减少:通过适当设计的 GSConv,减少特征图的通道数,从而降低计算量。
-
信息保持:在减少通道数的同时,通过优化卷积核和连接方式,尽量保持特征信息的完整性和表达能力。
5. 高效连接策略(Efficient Connection Strategies)
在网络的设计中,采用高效的连接策略:
-
跳跃连接(Skip Connections):在适当的位置引入跳跃连接,确保梯度的有效传递,防止梯度消失问题。
-
残差连接(Residual Connections):利用残差连接提高特征的传递效率,增强网络的学习能力。
6. 输出层
经过上述处理后的特征图进入最终的分类或回归层:
-
分类层:对于分类任务,通过全连接层或其他分类层对特征图进行分类。
-
回归层:对于回归任务,通过适当的回归层(如全连接层或卷积层)输出结果。
流程图示例
以下是 Slim-neck by GSConv 的流程图示例:
输入图像 -> 特征提取模块 -> 分组卷积层 -> 空间卷积层 -> 通道压缩层 -> 高效连接层 -> 输出层
总结
Slim-neck by GSConv 通过分组卷积和空间卷积的结合,优化网络的颈部部分,减少计算复杂度和参数量。通过高效的连接策略和通道压缩技术,确保特征信息的有效传递和表达,提高模型的计算效率和性能。

2.2 新增yaml文件
关键步骤二:在下/projects/yolov5-6.1/models下新建文件 GSConv-yolov5.yaml并将下面代码复制进去
*注:因为涉及到多个结构的替换,因此会有多种不通的yaml文件,在此只放一个,完整的请下拉下载完整代码。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicle
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, GSConv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, GSConv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, GSConv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, GSConv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]温馨提示:本文只是对yolov5l基础上添加swin模块,如果要对yolov8n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.3 注册模块
关键步骤三:在yolo.py中注册, 大概在260行左右分别添加 ‘ GSConv, VoVGSCSP, VoVGSCSPC’

2.4 执行程序
在train.py中,将cfg的参数路径设置为GSConv-yolov5.yaml的路径
建议大家写绝对路径,确保一定能找到

🚀运行程序,如果出现下面的内容则说明添加成功🚀

3. 完整代码分享
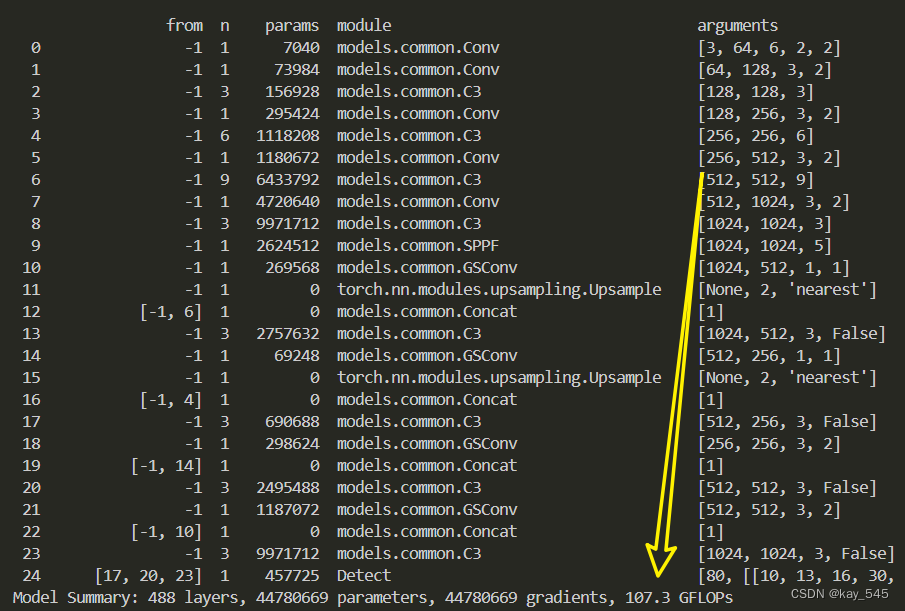
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的GFLOPs

改进后的GFLOPs
5. 总结
Slim-neck by GSConv 是一种优化神经网络结构的技术,其主要流程包括以下步骤:首先,输入图像通过特征提取模块生成初步特征图。然后,特征图进入分组卷积层,通过将特征图分成若干组并对每组进行卷积来减少计算量。接着,进行空间卷积,以捕捉和融合跨组特征。之后,利用 GSConv 在网络颈部部分进行通道压缩,减少特征图通道数并降低计算量,同时保持特征信息的完整性。高效连接策略(如跳跃连接和残差连接)在适当位置引入,确保梯度有效传递和特征高效传输。最终,处理后的特征图进入分类或回归层,输出相应结果。通过定义合适的损失函数和采用优化算法对模型进行训练,Slim-neck by GSConv 实现了在减少计算复杂度和参数量的同时,保持l 模型性能的目标。
这篇关于YOLOv5改进 | 卷积模块 | 将Conv替换为轻量化的GSConv【原理 + 完整代码】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



