本文主要是介绍YOLOv8改进 | 卷积模块 | 用坐标卷积CoordConv替换Conv,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录:《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有40+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
CoordConv 是一种针对卷积神经网络(CNNs)的改进方法,旨在解决传统卷积在处理空间位置信息时的局限性。CoordConv 通过向卷积层引入额外的坐标信息通道,使网络能够更有效地学习空间变换,从而提高在需要理解空间布局的任务上的性能。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址:YOLOv8改进——更新各种有效涨点方法——点击即可跳转
目录
1. 原理
2. 代码实现
2.1 添加CoordConv到YOLOv8代码中
2.2 更改init.py文件
2.3 新增yaml文件
2.4 注册模块
2.5 执行程序
3. 完整代码分享
4. 进阶
5. 总结
1. 原理

官方论文:An intriguing failing of convolutional neural networks and the CoordConv solution——点击即可跳转
官方代码:官方代码仓库——点击即可跳转
CoordConv,即坐标卷积,解决了标准卷积神经网络 (CNN) 的一个重大限制。传统 CNN 难以完成需要转换空间表示的任务,例如将密集的笛卡尔坐标转换为稀疏的基于像素的表示或反之亦然。CoordConv 通过在卷积层中引入显式坐标信息解决了这个问题。以下是 CoordConv 背后原理的详细解释:
传统卷积及其局限性
标准 CNN 非常适合处理平移不变性有益的任务,例如图像分类。但是,当任务需要了解输入中的空间位置时,例如在生成模型或某些基于坐标的转换中,CNN 表现不佳。这是因为卷积层本身缺乏有关输入空间内绝对位置的信息。卷积在本地运行,在整个输入中应用相同的过滤器,这使得网络难以有效地学习位置信息。
CoordConv:使用坐标信息增强卷积
CoordConv 通过添加编码每个像素坐标的额外输入通道来修改标准卷积运算。这使卷积滤波器能够知道它们在输入空间中的位置,从而显著提高网络学习空间变换的能力。
CoordConv 的工作原理
-
坐标通道:CoordConv 层为输入引入了两个额外通道:一个用于 x 坐标,一个用于 y 坐标。这些通道包含输入中每个像素的归一化坐标。
-
连接:这些坐标通道与原始输入通道连接,为卷积滤波器提供特征信息和空间坐标。
-
学习:通过访问坐标信息,滤波器可以学习空间相关特征,从而提高网络在需要理解空间布局的任务上的性能。
优势
CoordConv 论文通过各种实验证明了这种方法的有效性:
-
监督坐标分类:在网络必须学习根据其坐标输出特定像素的任务中,即使在所有方面都提供监督,标准 CNN 也难以推广。另一方面,CoordConv 模型可以快速实现完美的准确性,并且参数更少。
-
监督坐标回归:从基于像素的表示转换为笛卡尔坐标对于传统 CNN 来说同样具有挑战性,但使用 CoordConv 就变得轻而易举。
-
监督渲染:从坐标输入创建图像是另一项 CoordConv 远远优于传统卷积的任务。
应用和推广
CoordConv 已在各个领域显示出改进,包括:
-
物体检测:CoordConv 通过提供更好的空间信息提高了 Faster R-CNN 等模型的准确性,从而获得更精确的边界框。
-
生成模型:在使用 GAN 和 VAE 进行图像生成等任务中,CoordConv 有助于减少模式崩溃并提高生成图像的质量。
-
强化学习:使用 CoordConv 的代理在某些 Atari 游戏中获得更高的分数,表明具有更好的空间理解和决策能力。
结论
CoordConv 对卷积层进行了简单但功能强大的修改,使其能够更好地处理需要空间感知的任务。通过嵌入显式坐标信息,CoordConv 层允许网络更有效地学习空间变换,从而显著提高各种应用程序的性能。
2. 代码实现
2.1 添加CoordConv到YOLOv8代码中
关键步骤一:将下面代码粘贴到在/ultralytics/ultralytics/nn/modules/conv.py中,并在该文件的__all__中添加“CoordConv”
class AddCoords(nn.Module):def __init__(self, with_r=False):super().__init__()self.with_r = with_rdef forward(self, input_tensor):"""Args:input_tensor: shape(batch, channel, x_dim, y_dim)"""batch_size, _, x_dim, y_dim = input_tensor.size()xx_channel = torch.arange(x_dim).repeat(1, y_dim, 1)yy_channel = torch.arange(y_dim).repeat(1, x_dim, 1).transpose(1, 2)xx_channel = xx_channel.float() / (x_dim - 1)yy_channel = yy_channel.float() / (y_dim - 1)xx_channel = xx_channel * 2 - 1yy_channel = yy_channel * 2 - 1xx_channel = xx_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)yy_channel = yy_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)ret = torch.cat([input_tensor,xx_channel.type_as(input_tensor),yy_channel.type_as(input_tensor)], dim=1)if self.with_r:rr = torch.sqrt(torch.pow(xx_channel.type_as(input_tensor) - 0.5, 2) + torch.pow(yy_channel.type_as(input_tensor) - 0.5,2))ret = torch.cat([ret, rr], dim=1)return retclass CoordConv(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, with_r=False):super().__init__()self.addcoords = AddCoords(with_r=with_r)in_channels += 2if with_r:in_channels += 1self.conv = Conv(in_channels, out_channels, k=kernel_size, s=stride)def forward(self, x):x = self.addcoords(x)x = self.conv(x)return xCoordConv(坐标卷积)通过将坐标信息集成到网络中来修改标准卷积操作,这有助于网络更有效地处理空间变换。下面逐步分解 CoordConv 所涉及的主要过程:
1. 输入准备
-
原始输入:从原始输入图像或特征图开始。
-
坐标生成:为 x 和 y 坐标生成坐标通道。
-
X 坐标通道:一个 2D 数组,其中每个元素代表像素的归一化 x 坐标。
-
Y 坐标通道:一个 2D 数组,其中每个元素代表像素的归一化 y 坐标。
2. 坐标连接
-
连接通道:沿通道维度将原始输入与 x 和 y 坐标通道连接起来。如果原始输入有 (C) 个通道,而坐标又增加了 2 个通道,那么 CoordConv 层的新输入将有 (C+2) 个通道。
3. CoordConv 层操作
-
卷积:使用标准卷积滤波器对连接输入执行卷积操作。这些滤波器现在可以访问坐标信息以及原始特征信息。
4. 学习和适应
-
训练:在训练期间,网络学习可以有效利用特征和坐标信息的滤波器。这使得网络能够比标准卷积更有效地理解和利用空间信息。
5. 集成到网络中
-
替换标准卷积:CoordConv 层可以替换现有架构中的标准卷积层。这种替换在网络中空间感知至关重要的部分尤其有益,例如在生成模型、对象检测和强化学习任务中。
2.2 更改init.py文件
关键步骤二:修改modules文件夹下的__init__.py文件,先导入函数

然后在下面的__all__中声明函数

2.3 新增yaml文件
关键步骤三:在 \ultralytics\ultralytics\cfg\models\v8下新建文件 yolov8_CoordConv.yaml并将下面代码复制进去
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [ 0.33, 0.25, 1024 ] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [ -1, 1, CoordConv, [ 64, 3, 2 ] ] # 0-P1/2- [ -1, 1, CoordConv, [ 128, 3, 2 ] ] # 1-P2/4- [ -1, 3, C2f, [ 128, True ] ]- [ -1, 1, CoordConv, [ 256, 3, 2 ] ] # 3-P3/8- [ -1, 6, C2f, [ 256, True ] ]- [ -1, 1, CoordConv, [ 512, 3, 2 ] ] # 5-P4/16- [ -1, 6, C2f, [ 512, True ] ]- [ -1, 1, CoordConv, [ 1024, 3, 2 ] ] # 7-P5/32- [ -1, 3, C2f, [ 1024, True ] ]- [ -1, 1, SPPF, [ 1024, 5 ] ] # 9# YOLOv8.0n head
head:- [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ]- [ [ -1, 6 ], 1, Concat, [ 1 ] ] # cat backbone P4- [ -1, 3, C2f, [ 512 ] ] # 12- [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ]- [ [ -1, 4 ], 1, Concat, [ 1 ] ] # cat backbone P3- [ -1, 3, C2f, [ 256 ] ] # 15 (P3/8-small)- [ -1, 1, CoordConv, [ 256, 3, 2 ] ]- [ [ -1, 12 ], 1, Concat, [ 1 ] ] # cat head P4- [ -1, 3, C2f, [ 512 ] ] # 18 (P4/16-medium)- [ -1, 1, CoordConv, [ 512, 3, 2 ] ]- [ [ -1, 9 ], 1, Concat, [ 1 ] ] # cat head P5- [ -1, 3, C2f, [ 1024 ] ] # 21 (P5/32-large)- [ [ 15, 18, 21 ], 1, Detect, [ nc ] ] # Detect(P3, P4, P5)温馨提示:因为本文只是对yolov8基础上添加模块,如果要对yolov8n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv8n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple# YOLOv8s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple# YOLOv8l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# YOLOv8m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple# YOLOv8x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.4 注册模块
关键步骤四:在parse_model函数中进行注册,添加CoordConv,
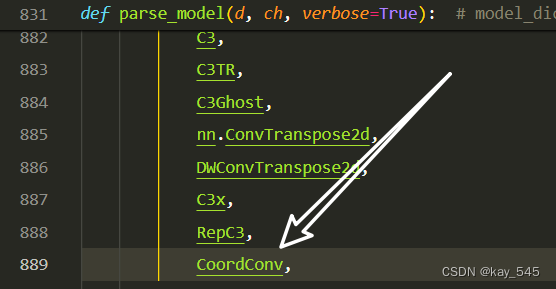
2.5 执行程序
在train.py中,将model的参数路径设置为yolov8_CoordConv.yaml的路径
建议大家写绝对路径,确保一定能找到
from ultralytics import YOLO# Load a model
# model = YOLO('yolov8n.yaml') # build a new model from YAML
# model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)model = YOLO(r'/projects/ultralytics/ultralytics/cfg/models/v8/yolov8_CoordConv.yaml') # build from YAML and transfer weights# Train the model
model.train(device = [3], batch=16)🚀运行程序,如果出现下面的内容则说明添加成功🚀

3. 完整代码分享
https://pan.baidu.com/s/1EUh4JiCj4Jhc31BeH3eSOQ?pwd=utvm提取码: utvm
4. 进阶
可以与其他的注意力机制或者损失函数等结合,进一步提升检测效果
5. 总结
CoordConv(坐标卷积)通过将显式坐标信息集成到卷积层来增强标准卷积神经网络。它引入了两个额外的通道,分别表示每个像素的归一化 x 和 y 坐标,并与原始输入通道连接。这使得卷积滤波器能够访问特征和位置信息,从而使网络能够更有效地学习空间相关特征。因此,CoordConv 显著提高了需要精确空间感知的任务(例如物体检测、生成建模和强化学习)的性能。
这篇关于YOLOv8改进 | 卷积模块 | 用坐标卷积CoordConv替换Conv的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






