yolov10专题

基于YOLOv10的垃圾检测系统
基于YOLOv10的垃圾检测系统 (价格90) 包含 ['CardBoard', 'Glass', 'Metal', 'Paper', 'Plastic'] 5个类 ['纸板', '玻璃', '金属', '纸张', '塑料'] 通过PYQT构建UI界面,包含图片检测,视频检测,摄像头实时检测。 (该系统可以根据数据训练出的yolov10的权

目标检测-YOLOv10
YOLOv10 是 YOLO 系列的最新版本,进一步推动了目标检测技术的发展。它在前代(YOLOv9)的基础上进行了更多优化和改进,使得模型在复杂场景、实时性以及精度方面取得了更高的突破。YOLOv10 将高效的架构设计与新颖的技术结合,适应各种应用场景,包括自动驾驶、智能监控、机器人视觉等。 YOLOv10 的主要改进与特点 全新的 Backbone 主干网络 YOLOv10 采用了 Ef

使用YOLOv10训练自定义数据集之二(数据集准备)
0x00 前言 经过上一篇环境部署的介绍【传送门】,我们已经得到了一个基本可用的YOLOv10的运行环境,还需要我们再准备一些数据,用于模型训练。 0x01 准备数据集 1. 图像标注工具 数据集是训练模型基础素材。 对于小白来说,一般推荐从一些开放网站中下载直接使用,官方推荐了一个名为Roboflow的数据集网站。Roboflow是一个免费开源数据集管理平台,它不仅提供免费的数据集,还

爆改YOLOv8|利用yolov10的SCDown改进yolov8-下采样
1, 本文介绍 YOLOv10 的 SCDown 方法来优化 YOLOv8 的下采样过程。SCDown 通过点卷积调整通道维度,再通过深度卷积进行空间下采样,从而减少了计算成本和参数数量。这种方法不仅降低了延迟,还在保持下采样过程信息的同时提供了竞争性的性能。 关于SCDown 的详细介绍可以看论文:https://arxiv.org/pdf/2405.14458 本文将讲解如何将SCDow

YoloV10改进策略:下采样改进|自研下采样模块(独家改进)|疯狂涨点|附结构图
文章目录 摘要自研下采样模块及其变种第一种改进方法 YoloV10官方测试结果改进方法测试结果总结 摘要 本文介绍我自研的下采样模块。本次改进的下采样模块是一种通用的改进方法,你可以用分类任务的主干网络中,也可以用在分割和超分的任务中。已经有粉丝用来改进ConvNext模型,取得了非常好的效果,配合一些其他的改进,发一篇CVPR、ECCV之类的顶会完全没有问题。 本次我将这个模

爆改YOLOv8|利用yolov10的PSA注意力机制改进yolov8-高效涨点
1,本文介绍 PSA是一种改进的自注意力机制,旨在提升模型的效率和准确性。传统的自注意力机制需要计算所有位置对之间的注意力,这会导致计算复杂度高和训练时间长。PSA通过引入极化因子来减少需要计算的注意力对的数量,从而降低计算负担。极化因子是一个向量,通过与每个位置的向量点积,确定哪些位置需要计算注意力。这种方法可以在保持模型准确度的前提下,显著减少计算量,从而提升自注意力机制的效率。 关于PS

YoloV10改进策略:卷积篇|基于PConv的二次创新|附结构图|性能和精度得到大幅度提高(独家原创)
文章目录 摘要论文指导PConv在论文中的描述改进YoloV10的描述 改进代码与结构图改进方法测试结果总结 摘要 在PConv的基础上做了二次创新,创新后的模型不仅在精度和速度上有了质的提升,还可以支持Stride为2的降采样。 改进方法简单高效,需要发论文的同学不要错过! 论文指导 PConv在论文中的描述 论文: 下面我们展示了可以通过利用特征图的冗余来进一步优化成本

最新!yolov10+deepsort的目标跟踪实现
目录 yolov10介绍——实时端到端物体检测 概述 主要功能 型号 性能 方法 一致的双重任务分配,实现无 NMS 培训 效率-精度驱动的整体模型设计 提高效率 精度提升 实验和结果 比较 deepsort介绍: yolov10结合deepsort实现目标跟踪 效果展示 训练与预测 UI设计 其他功能展示 完整代码实现+UI界面 此次yolov10

基于yolov10的PCB检测算法研究
内容:项目将YOLOV10创新后的PCB检测算法成功部署到GD32H757上,实现PCB缺陷的工业产线实时检测。 项目主要支持开源代码:HomiKetalys/gd32ai-modelzoo: Provide deployable deep learning models on gd32 (github.com) (想了解将AI模型部署到边缘MCU设备上,比如STM32/GD32,可以跟着这个

YOLOv8改进 | 科研必备 | 计算YOLOv8、YOLOv10模型的FPS的脚本【复制 - 粘贴 - 运行】
秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转 💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 专栏目录 :《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有100+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进——点击即可跳转 FPS(Frames Per Sec

【论文阅读】YOLOv10: Real-Time End-to-End Object Detection
文章目录 摘要一、介绍二、相关工作三、方法3.1无nms培训的一致性双重任务3.2 整体效率-精度驱动的模型设计 四、实验4.1实现细节4.2与最先进水平的比较4.3模型分析 五、结论 YOLOv10:实时端到端对象检测 摘要 在过去的几年里,由于在计算成本和检测性能之间取得了有效的平衡,YOLOs已经成为实时目标检测领域的主导范式。研究人员已经对yolo的架构设计、优化目
YOLOv10:面向下一代目标检测模型的创新探索
随着计算机视觉技术的飞速发展,目标检测模型在各类应用场景中的重要性与日俱增。从自动驾驶到智能监控,目标检测的准确性和实时性都直接影响着应用的效果和用户体验。YOLO(You Only Look Once)系列作为实时目标检测的代表性模型,自发布以来便因其速度与精度的平衡性得到了广泛关注和应用。如今,随着YOLOv10的即将推出,我们站在技术的前沿,思考如何对这一模型进行革新,使其在面对复杂多变的场

目标检测 | yolov10 原理和介绍
相关系列: 目标检测 | yolov1 原理和介绍 目标检测 | yolov2/yolo9000 原理和介绍 目标检测 | yolov3 原理和介绍 目标检测 | yolov4 原理和介绍 目标检测 | yolov5 原理和介绍 目标检测 | yolov6 原理和介绍 目标检测 | yolov7 原理和介绍 目标检测 | yolov8 原理和介绍 目标检测 | yolov9 原理和介绍 目标检测
ultralytics官方更新 | 添加YOLOv10到ultralytics
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 专栏目录:《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有40+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进 对YOLOv10感兴趣的同学可以先看YOLOv8,因为改进方式大部分一样,我也会尽快更新相关的教程 论文地址:YOLOv10: Real

YOLOv10目标检测算法的使用
目录 一、环境安装 1、创建虚拟环境 2、安装依赖 二、数据集准备 1、预训练权重 2、数据划分 3、建立数据集的yaml文件 三、训练 1、终端运行指令 2、建立一个 python 文件运行 四、验证 1、终端运行指令 2、建立一个 python 文件运行 五、模型推理 1、单张图片推理 2、视频推理 六、导出报告 七、报错处理 1、提示数据集.yaml文

YOLOv10改进 | 注意力篇 | YOLOv10引入MLCA
1. MLCA介绍 1.1 摘要:注意力机制是计算机视觉中使用最广泛的组件之一,可以帮助神经网络强调重要元素并抑制不相关的元素。然而,绝大多数信道注意力机制只包含信道特征信息,忽略了空间特征信息,导致模型表示效果或目标检测性能较差,且空间注意力模块往往复杂且成本高昂。为了在性能和复杂度之间取得平衡,该文提出一种轻量级的混合局部信道注意力(MLCA)模块来提高目标检测网络的性能,该模块可以同

YOLOv10改进 | Conv篇 |YOLOv10引入SPD-Conv卷积
1. SPD-Conv介绍 1.1 摘要:卷积神经网络(CNN)在图像分类和目标检测等许多计算机视觉任务中取得了巨大的成功。 然而,在图像分辨率较低或物体较小的更艰巨的任务中,它们的性能会迅速下降。 在本文中,我们指出,这源于现有 CNN 架构中一个有缺陷但常见的设计,即使用跨步卷积和/或池化层,这会导致细粒度信息的丢失和学习效率较低的特征表示 。 为此,我们提出了一种名为 SPD-Conv
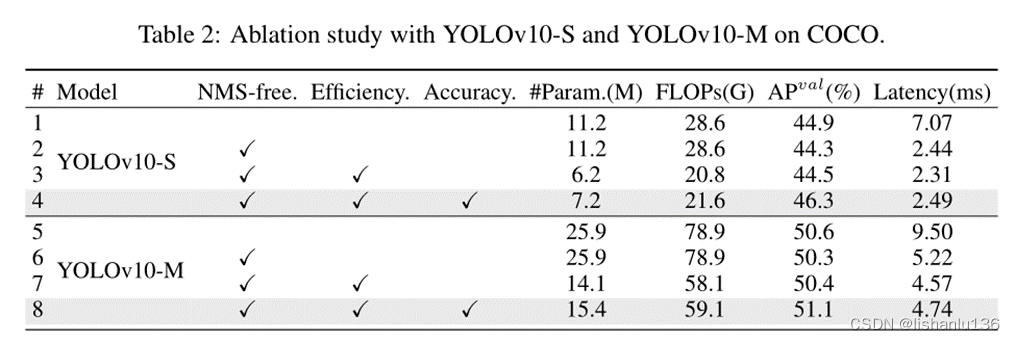
目标检测——YOLOv10算法解读
论文:YOLOv10: Real-Time End-to-End Object Detection (2024.5.23) 作者:Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding 链接:https://arxiv.org/abs/2405.14458 代码:https://github.co
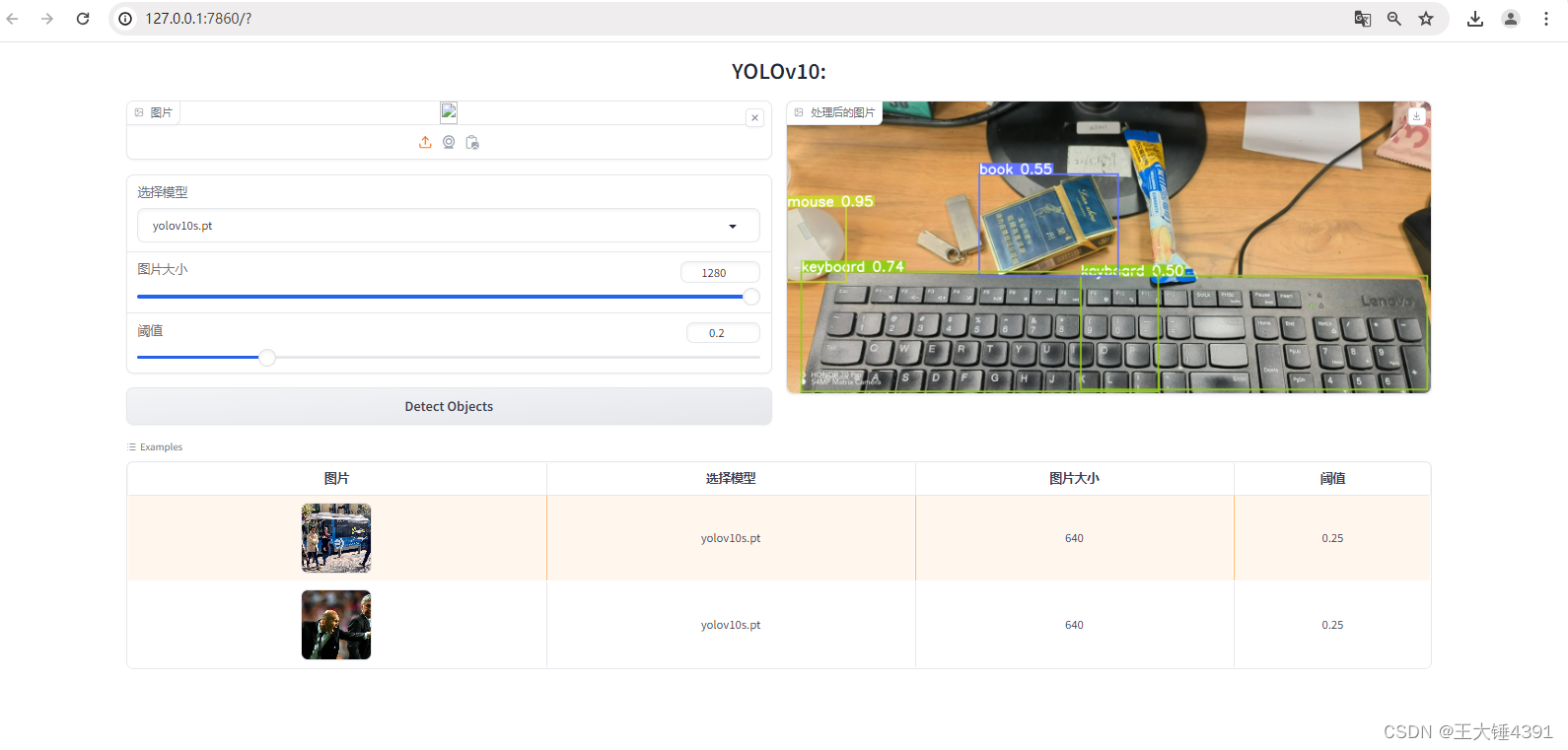
yolov10官方demo
python环境3.9 GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection 将模型移动到项目目录下 项目执行导入依赖 conda create -n yolov10 python=3.9conda activate yolov10pip install -r requirement

【YOLOv10:在简约中发现卓越,VanillaNet定义目标检测新标准】
本文改进:神经网络模型VanillaNet 1.YOLOv10介绍 论文:[https://arxiv.org/pdf/2405.14458] 代码: https://gitcode.com/THU-MIG/yolov10?utm_source=csdn_github_accelerator&isLogin=1 摘要:在过去的几年里,由于其在计算成本和检测性能之间的有效平衡,YOLOS已经成

YOLOv10改进 | 注意力篇 | YOLOv10引入HAttention(HAT)注意力
1. HAT介绍 1.1 摘要:基于 Transformer 的方法在低级视觉任务(例如图像超分辨率)中表现出了令人印象深刻的性能。 然而,我们发现这些网络通过归因分析只能利用有限的输入信息空间范围。 这意味着 Transformer 的潜力在现有网络中仍未得到充分发挥。 为了激活更多的输入像素以实现更好的重建,我们提出了一种新颖的混合注意力变换器(HAT)。 它结合了通道注意力和基于窗口
![【YOLOv10改进[注意力]】使用注意力MLCA改进C2f + 含全部代码和详细修改方式 + 手撕结构图](https://img-blog.csdnimg.cn/direct/72fdccaa605c4bb88d16bd92bde4bee4.png)
【YOLOv10改进[注意力]】使用注意力MLCA改进C2f + 含全部代码和详细修改方式 + 手撕结构图
本文将进行使用注意力MLCA改进C2f的实践,助力YOLOv10目标检测效果的实践,文中含全部代码、详细修改方式以及手撕结构图。助您轻松理解改进的方法。 改进前和改进后的参数对比: 目录 一 MLCA 二 使用注意力MLCA改进C2f 1 整体修改 2 配置文件

YOLOv10涨点改进轻量化双卷积DualConv,完成涨点且计算量和参数量显著下降
本文独家改进:双卷积由组卷积和异构卷积组成,执行3x3 和 1x1 卷积运算Q代替其他卷积核仅执行 1x1 卷积。 DualIConv 显着降低了深度神经网络的计算成本和参数数量,同时在某些情况下令人惊讶地实现了比原始模型略高的精度。 我们使用 DualConv 将轻量级 MobileNetV2 的参数数量进一步减少了 54% 目录 1)替换原始的Conv 2,YOLOv10介绍 1.1

YOLOv10涨点改进:改进检测头(Partial_C_v10Detect)检测头结构创新,实现涨点
目录 1,YOLOv10介绍 1.1 C2fUIB介绍 1.2 PSA介绍 1.3 SCDown 1.Partial C v10Detect原理介绍 1.1 Partial Convolution 3.v10Detect二次创新引入到yolov10 3.1 修改ultralytics/nn/modules/head.py 第一处修改:PConv加入以下代码 1,
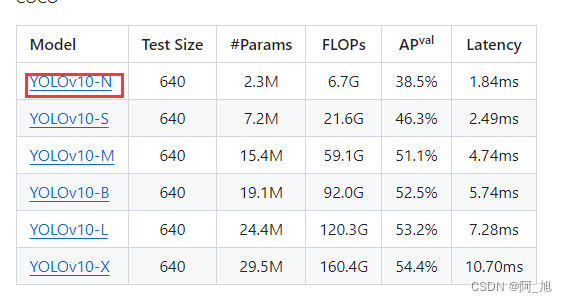
实战 | 基于YOLOv10的车辆追踪与测速实战【附源码+步骤详解】
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识

YOLOv10独家涨点改进:轻量化双卷积DualConv,有效减少参数和涨点
目录 1 C2fUIB介绍 2.DualConv原理 3.如何将Dualconv将入到YOLOv10 3.1 新建ultralytics/nn/Conv/DualConv.py 3.2 注册ultralytics/nn/tasks.py 论文 https://arxiv.org/pdf/2405.14458 代码 GitHub - THU-MIG/yolov10: YO