本文主要是介绍目标检测——YOLOv10算法解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:YOLOv10: Real-Time End-to-End Object Detection (2024.5.23)
作者:Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding
链接:https://arxiv.org/abs/2405.14458
代码:https://github.com/THU-MIG/yolov10
YOLO系列算法解读:
YOLOv1通俗易懂版解读、SSD算法解读、YOLOv2算法解读、YOLOv3算法解读、YOLOv4算法解读、YOLOv5算法解读、YOLOR算法解读、YOLOX算法解读、YOLOv6算法解读、YOLOv7算法解读、YOLOv8算法解读、YOLOv9算法解读、YOLOv10算法解读
PP-YOLO系列算法解读:
PP-YOLO算法解读、PP-YOLOv2算法解读、PP-PicoDet算法解读、PP-YOLOE算法解读、PP-YOLOE-R算法解读
文章目录
- 1、算法概述
- 2、YOLOv10细节
- 2.1 Consistent Dual Assignments for NMS-free Training
- 2.2 Holistic Efficiency-Accuracy Driven Model Design
- 3、实验
- 3.1 与现如今其他检测算法对比
- 3.2 模型分析
- 3.3 模型限制
1、算法概述
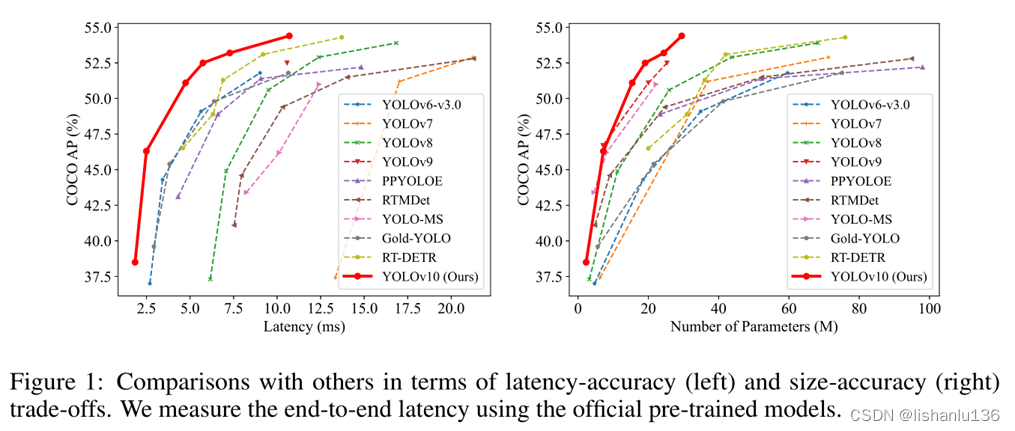
YOLOv10出自清华大学,论文指出过去人们对YOLO的优化,主要集中在架构设计、优化目标、数据增强策略,然而并没有人试图去掉后处理步骤NMS,这对YOLO系列的端到端部署是不利的而且会增加推理时间。此外,各版本YOLO中各部件的设计缺乏全面彻底的检查,导致计算冗余明显,限制了模型的能力。所以YOLOv10的目标就是从后处理和模型架构两个方面进一步推进YOLO系列的性能。为此,作者提出一致双标签分配NMS-free训练法,带来了高性能和低延时。在模型架构设计方面,作者引入整体高效-精度驱动的模型设计策略,从YOLOv10的全面优化各组件来看达到了高效-精度最优,这大大降低了计算开销,提高了性能。在COCO数据集相同mAP情况下,YOLOv10-S比RT-DETR-R18快1.8倍,同时比后者小2.8倍的参数量和flops。与YOLOv9-C相比,在相同性能下,YOLOv10-B的延迟减少了46%,参数减少了25%。
之前的YOLO改进版本均是采用一对多的标签分配策略,即一个标注框对应多个正样本,这样在检测的后处理阶段就必须应用NMS选择最佳检测结果。想去掉NMS,就可参考DETR的算法框架,例如RT-DETR提出了一种高效的混合编码器和最小不确定性查询选择,将DETR推进到实时应用领域。然而,由于DETR的内在复杂性,导致部署困难,很难在精度和延时找到平衡。所以还是回到CNN-based 检测器的探索。
回顾之前YOLO系列的结构方面的改进,为增强主干特征提取能力,提出了多种主计算单元如:DarkNet,CSPNet,EfficientRep和ELAN等等,针对Neck部分,有PAN,BiC,GD和RepGFPN等等,还探索了增强多尺度特征融合的方法,模型缩放方法和模型重参数化技术。虽然这些改进都对最终的模型性能取得了提升,但从效率和精度的角度上来讲,仍然缺乏对各个YOLO版本中各种组件的全面评估。换句话讲,各版本YOLO内部仍然存在相当大的计算冗余,导致参数利用率低,效率次优。
2、YOLOv10细节
2.1 Consistent Dual Assignments for NMS-free Training
在训练阶段,之前版本的YOLO大多采用TAL标签分配策略,为一个目标标注框一次分配多个正样本,采用一对多分配,可以产生丰富的监控信号,便于优化,实现更优的性能。然而,这种一对多训练策略需要YOLO依赖NMS的后处理,这导致部署的推理效率不理想。虽然以前也有论文探索一对一匹配来抑制冗余预测,但它们通常会引入额外的推理开销或产生次优性能。
- Dual label assignments
一对一的标签分配策略可以避免后处理的NMS操作,但是它导致训练过程中的弱监督问题,优化精度和推理时间不能达到最优。有幸的是,这些缺陷都可以通过一对多的标签分配策略弥补,所以作者提出了双标签分配策略来有效结合两种标签分配方式的优势。如下图a所示,作者在原来版本的YOLO基础上新增加一个一对一分配策略的检测头;在训练过程中,两个检测头与模型共同优化,使backbone和neck享受到一对多分配所提供的丰富监督信息。在推理过程中,作者抛弃了一对多检测头,利用一对一检测头进行预测。这使得YOLOv10能够进行端到端部署,而不会产生任何额外的推理成本。在一对一匹配中,作者采用了top 1的选择,达到了与匈牙利匹配相同的效果,并且减少了额外的训练时间。
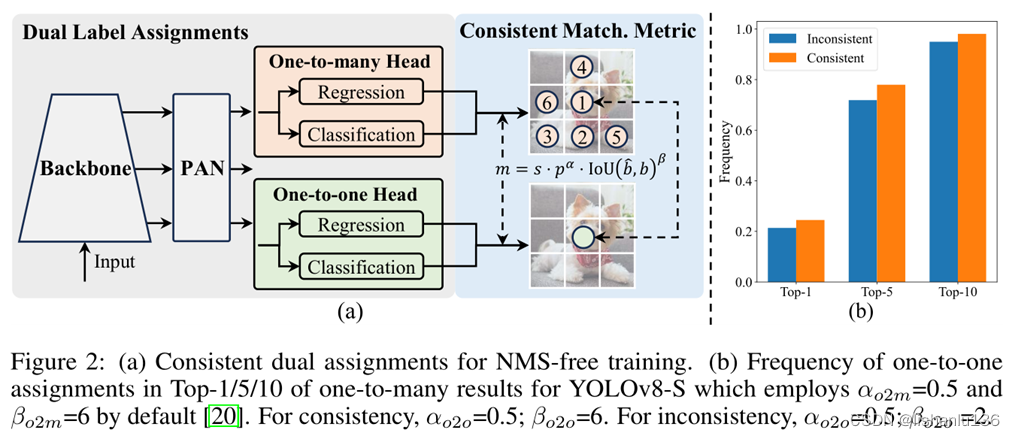
- Consistent matching metric
在标签分配过程中,一对一和一对多方法都利用一个度量来定量地评估预测和实例之间的一致性水平。为了实现两个分支的预测感知匹配,作者采用了统一的匹配度量公式如下:

其中P是类别预测分数,b^ 和b是bounding box的预测和实例,s代表指示预测锚点是否在实例内的空间先验,α和β是两个超参数,用于平衡语义预测任务和回归定位任务。
在双标签分配中,一对多分支比一对一分支提供更丰富的监控信号。所以,如果我们能够将一对一检测头的监督与一对多检测头的监督协调起来,我们就可以朝着一对多检测头优化的方向去优化一对一检测头,这样就可以让一对一检测头在推理过程中提供更好的预测质量,从而获得更好的性能。
2.2 Holistic Efficiency-Accuracy Driven Model Design
除了后处理之外,YOLO的模型架构也在效率和精度上存在较大的改进空间。之前YOLO模型体系结构表现出不可忽略的计算冗余和约束能力,这为实现高效率和高性能提供了潜力。作者从效率和准确性的角度全面地执行YOLO的模型设计。
- Efficiency driven model design
YOLO的组件包括stem、downsampling layers、包含数个基本block的stages和检测头。由于stem部分计算成本很少,因此作者对其他三个部分进行了效率驱动的模型设计。
(1)、Lightweight classification head:通常来说,分类头和回归头采用相同的预测架构,但作者通过分析YOLOv8-S发现,他们计算开销方面表现出显著的差异(分类头占比大),而且它们对整个YOLO模型的性能提升的贡献也不一样(回归头对YOLO性能更重要),所以作者减少了分类头的计算开销,采用轻量级架构,它由两个深度可分离的卷积组成,深度可分离卷积核大小为3×3,然后是一个1×1卷积。
(2)、Spatial-channel decoupled downsampling:之前版本的YOLO通常是用3x3卷积并应用stride等于2实现下采样,同时输出channel变成两倍,这样做引入了较大计算量和参数量。作者这里将下采样和channel数量解耦,利用点卷积(pointwise convolution)来调制channel维度,然后利用深度卷积(depthwise convolution)来执行空间下采样,这样做大大减小了计算量和参数量。
(3) 、Rank-guided block design:之前版本的YOLO通过在每个stage中应用相同的基础block;通过分析YOLOv8各个版本每个stage的冗余度,如下图a所示,从图中结果表明,简单地在所有阶段采用相同的block设计并不能达到最佳的产能效率平衡。
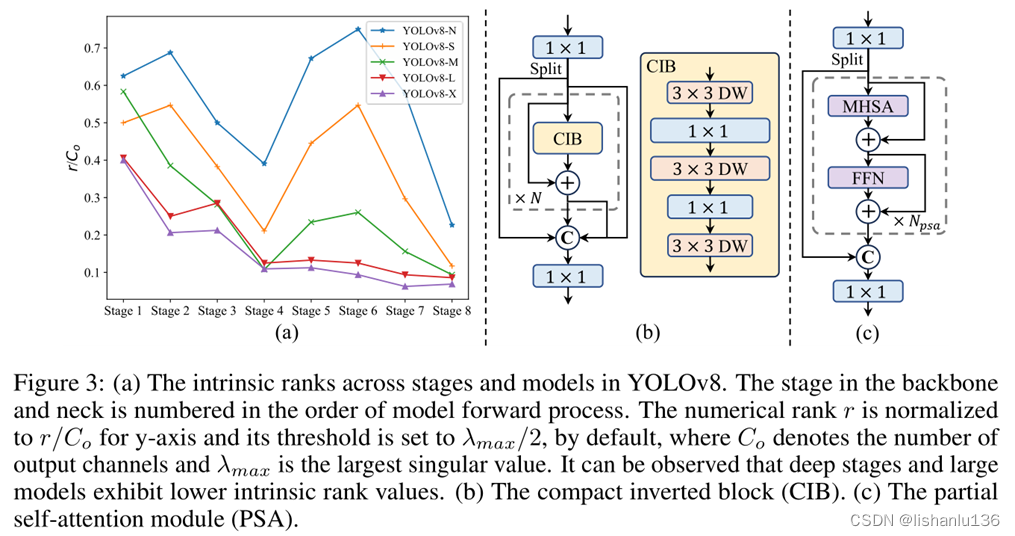
为了解决这个问题,作者提出了一个等级引导的块设计方案,旨在减少使用紧凑的架构设计显示冗余的阶段的复杂性。作者首先提出了一种紧凑的倒块(CIB)结构,如上图b所示,该结构采用深度卷积进行空间混合,采用的点卷积进行信道混合。 - Accuracy driven model design
作者进一步探索了精度驱动设计的大核卷积和自注意力,旨在以最小的成本提高性能。
(1) 、Large-kernel convolution:采用大核深度卷积(depthwise convolution)是扩大接受野和增强模型能力的有效方法。然而,在所有阶段简单地利用它们可能会导致用于检测小物体的浅层特征受到污染,同时在高分辨率stage也会带来显著的I/O开销和延迟。因此,作者建议在较小分辨率stage时利用CIB中的大核深度卷积。具体来说,作者将CIB中第二个3×3深度卷积的核大小增加到7×7,此外,作者采用结构重参数化技术引入另一个3×3深度卷积分支来缓解优化问题,而不需要推理开销。此外,随着模型大小的增加,其接受域自然会扩大,使用大核卷积的好处会减少。因此,作者只对小模型尺度采用大核卷积。
(2) 、Partial self-attention (PSA):作者提出了高效的部分自注意力结构,如上图c所示。作者在1×1卷积后将通道上的特征均匀地划分为两部分,只将其中一部分输入到由多头自注意模块(MHSA)和前馈网络(FFN)组成的N PSA模块中。然后通过1×1的卷积将两个部分连接并融合。PSA仅放置在分辨率最低的stage4之后,避免了自注意的二次计算复杂性带来的过多开销。这样可以将全局表示学习能力融入到YOLO中,计算成本较低,很好地增强了模型的能力,从而提高了性能。
3、实验
实验设置:作者以YOLOv8作为baseline模型,为方便对比,YOLOv10也开发了一系列规模不同的网络结构如:N/S/M/L/X,更在M的基础上稍微提升宽度比例因子得到YOLOv10-B,实验都用COCO2017训练集训练,用其验证集选择最佳模型,用COCO2017测试集评估模型性能。所有模型的延迟时间均在T4 GPU上使用TensorRT FP16进行测试得到。
3.1 与现如今其他检测算法对比
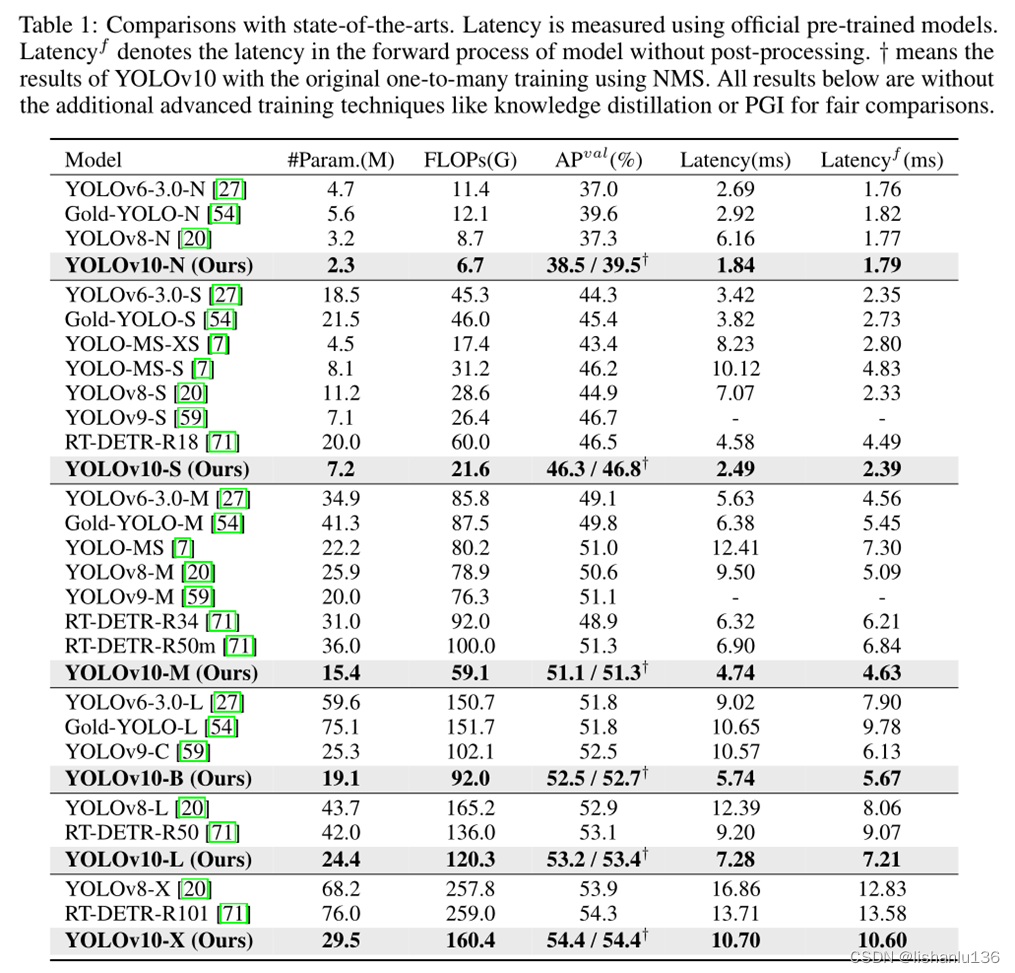
从表1中可以看出,在同等规模网络结构下,YOLOv10的参数量和flops均是最小,但AP是最高的,同时推理时间也是最短的。值得注意的是,AP这一列,对于YOLOv10的行,AP有两个值,右上角带加号标注的为检测器一对多检测头的输出,看以看出,模型规模越小,一对多输出的AP比前者一对一输出的AP高得越多,在YOLOv10-X时,两者达到相同的AP效果。
3.2 模型分析
消融实验,作者对所提改进方式,一致双标签分配NMS-free训练策略和模型效率-精度设计策略进行了消融实验,实验在YOLOv10-S和YOLOv10-M两个规模结构下完成,结果如下表所示。
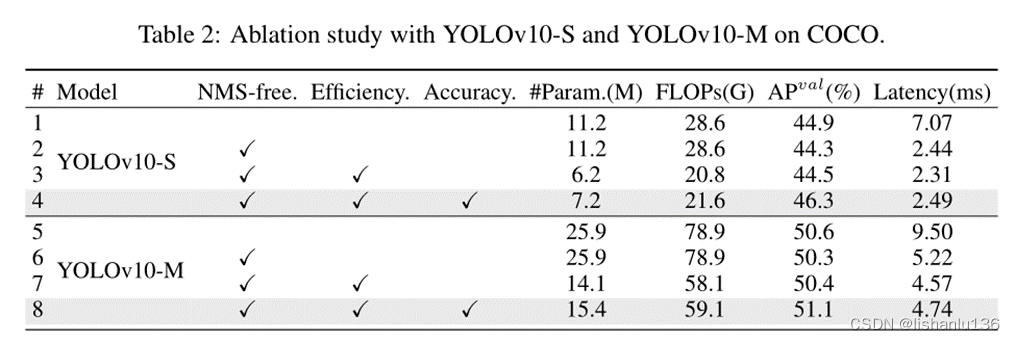
可以看出,若单独采用一致双标签分配NMS-free训练策略,AP会有少许下降,但推理时间大大减小;若再结合高效网络结构设计,会减小模型参数的同时进一步减小模型推理时间,最后再结合精度网络结构设计策略,能在不增加推理时间的情况下,将AP提升1到两个点左右。从以上结果可以看出,作者提出的改进方式是有效果的。
3.3 模型限制
- 作者没有研究YOLOv10在大规模数据集上的预训练模型的表现怎么样;
- 在YOLOv10小规模模型如:YOLOv10-N和YOLOv10-S中,一对一检测头NMS-free的AP仍然与一对多检测头采用NMS的AP表现有差距,分别为1%和0.5%,这种差距可以在3.1的表中可以看出,模型规模越小,差距越大。
这篇关于目标检测——YOLOv10算法解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






