本文主要是介绍ReF:斯坦福提出的新型语言模型微调方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着预训练语言模型(LMs)在各种自然语言处理(NLP)任务中的广泛应用,模型微调成为了一个重要的研究方向。传统的全参数微调方法虽然有效,但计算成本高昂,尤其是在大型模型上。为了解决这一问题,来自斯坦福大学和 Pr(Ai)⊃2;R Group 的研究团队推出一种全新的微调方法——表征微调(ReFT)。ReFT方法的核心优势在于,它不直接对模型权重进行更新,而是通过学习对隐藏层表征的特定干预来适应下游任务。这种方法不仅能够保持模型参数的高效性,还能够更深入地挖掘和利用模型内部的语义结构,从而实现更精准、更有效的模型行为调整。通过直接编辑模型的内部表征,ReFT方法为我们提供了一种更为灵活和强大的工具,以更低的成本实现对模型行为的精细调控。本文意在介绍ReFT方法的工作原理、实现方式以及在多个NLP任务上的应用效果。
方法
在深度学习模型的黑箱特性逐渐被揭开的过程中,模型解释性研究提供了对内部工作机制的洞察。特别是在自然语言处理领域,模型的表征能力——即如何将输入文本转换为高维空间中的向量表示——是理解其语义处理能力的关键。基于此,ReFT(Representation Finetuning)方法应运而生,它通过直接干预这些表征来优化模型行为,为模型微调提供了一种新颖且高效的途径。
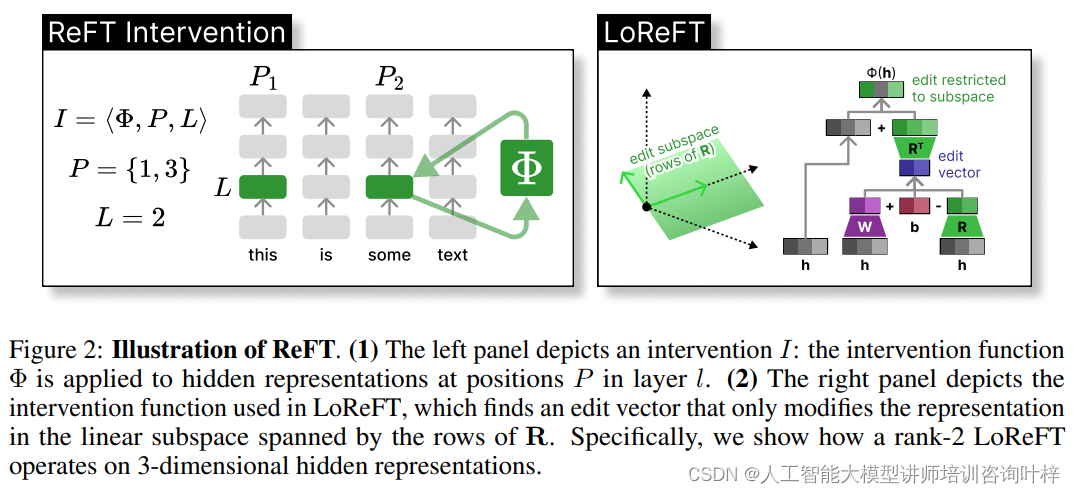
Figure 2展示了如何在模型的隐藏层表示中应用干预函数,介绍了LoReFT(低秩线性子空间ReFT)的干预机制。
图2(左面板):ReFT干预的一般过程
在左面板中,展示了一个名为I的干预过程,其中干预函数Φ被应用于层l中位置集P的隐藏表示。这个过程是ReFT方法的核心,它允许研究者在模型的特定层和特定位置对隐藏表示进行精确的调整。这种干预可以是增加、减少或改变表示的某些方面,以此来影响模型的最终预测。
图2(右面板):LoReFT特定的干预函数
右面板更详细地描述了LoReFT中使用的干预函数。LoReFT通过找到一个仅在由矩阵R的行张成的线性子空间内修改表示的编辑向量。具体来说,这里展示了一个秩为2的LoReFT如何在3维隐藏表示上操作。
-
线性子空间:在LoReFT中,干预不是在整个表示空间中进行,而是限制在一个较低维的线性子空间内。这个子空间由一个低秩矩阵R定义,其中R的行是正交的,并且共同构成了干预发生的空间。
-
编辑向量:LoReFT学习一个编辑向量,该向量仅在这个子空间内对隐藏表示进行修改。这种方法不仅减少了参数的数量,而且因为干预被限制在较小的子空间内,所以可以更精确地控制模型的行为。
-
秩-2 LoReFT:图2中特别展示了秩为2的LoReFT操作。在这种情况下,子空间由两个正交向量定义,LoReFT通过在这个2维空间内调整表示来影响模型的预测。
我们可以看到ReFT方法提供了一种非常灵活的方式来调整和优化语言模型的行为,而LoReFT则展示了如何在保持参数效率的同时实现这种调整。这种干预机制为提高模型在特定任务上的性能提供了一种有效手段,同时也为理解模型内部工作方式提供了新的视角。
ReFT方法的动机根植于模型解释性研究中的因果抽象框架。通过干预模型的内部表征,研究者能够测试和验证模型中特定概念的编码方式。例如,通过交换干预(interchange intervention)技术,可以固定某个表征为模型处理某个反事实输入时的值,进而观察这种干预对模型行为的影响。这种干预不仅帮助我们理解模型内部的因果机制,也启发了通过直接编辑表征来控制模型输出的可能性。
ReFT方法的一个关键创新是利用低秩矩阵来实现对表征的高效干预。这种方法的两个实例化——LoReFT(Low-rank Linear Subspace ReFT)和DiReFT(一种LoReFT的简化版本)——展示了如何通过干预隐藏层表征的低维线性子空间来调整模型行为。
-
LoReFT:这种方法通过学习一个低秩投影矩阵来干预隐藏表征,使其在保持参数效率的同时,能够对模型的预测行为产生显著影响。LoReFT的干预函数利用了分布式对齐搜索(DAS)技术来找到最能提升预期输出概率的子空间。
-
DiReFT:作为LoReFT的一个变体,DiReFT在牺牲一些性能的同时,通过去除正交性约束和差异操作来提高训练效率。这种简化使得DiReFT在计算上更加高效,同时仍然保持了较低的参数开销。
ReFT方法不仅限于上述两种低秩实例化,它实际上定义了一类更广泛的表征干预方法。这些方法通过修改Transformer模型中的隐藏表征来实现对模型行为的控制,而无需改变模型的原始权重。
-
一般概念:ReFT方法通过定义一个干预函数,该函数在模型的前向传播过程中修改特定的隐藏表征。干预可以针对模型的任何层和任何输入位置,提供了极大的灵活性。
-
应用多样性:ReFT方法的一般性使其能够应用于各种不同的NLP任务,包括但不限于文本生成、分类和问答系统。通过精心设计的干预策略,ReFT能够针对特定任务优化模型的表征能力,从而提高性能。
ReFT方法的提出,不仅为语言模型的微调提供了一种新的视角,也为模型的可解释性和可控性研究开辟了新的道路。随着进一步的研究和开发,ReFT有望成为提高语言模型性能和应用范围的关键技术。
实验
在实验之前,研究者们首先需要确定ReFT方法的超参数配置。这包括决定干预的层数、干预在序列中的位置、干预的维度(即低秩矩阵的秩),以及其他神经网络训练的超参数,如学习率、批次大小和优化器等。他们采用了一个简化的超参数搜索空间,并通过在开发集上的性能来选择最佳的超参数组合。这一过程确保了ReFT方法能够在不同的任务和数据集上实现良好的泛化能力。
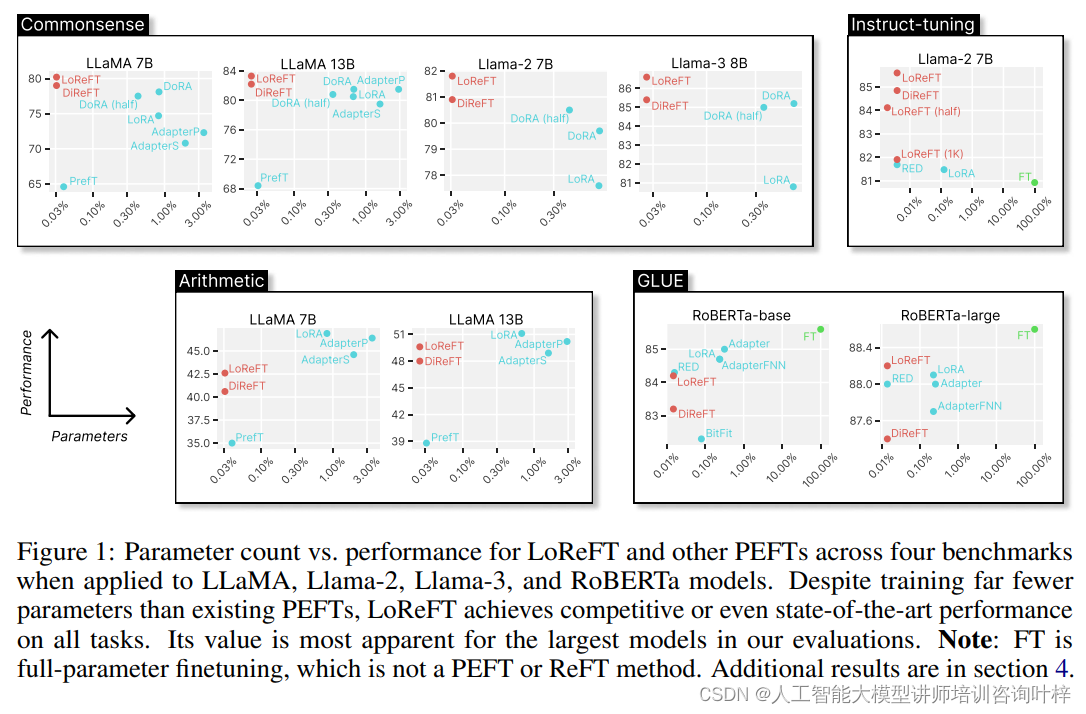
常识推理是评估语言模型理解和应用日常知识的能力。研究者们在包括BoolQ、PIQA、SIQA、HellaSwag、WinoGrande、ARC和OBQA在内的多个常识推理数据集上测试了ReFT方法。实验结果表明,LoReFT和DiReFT在这些任务上均展现出了卓越的性能,特别是在参数数量远少于其他PEFT方法的情况下,仍然能够达到或超越当前最佳性能。

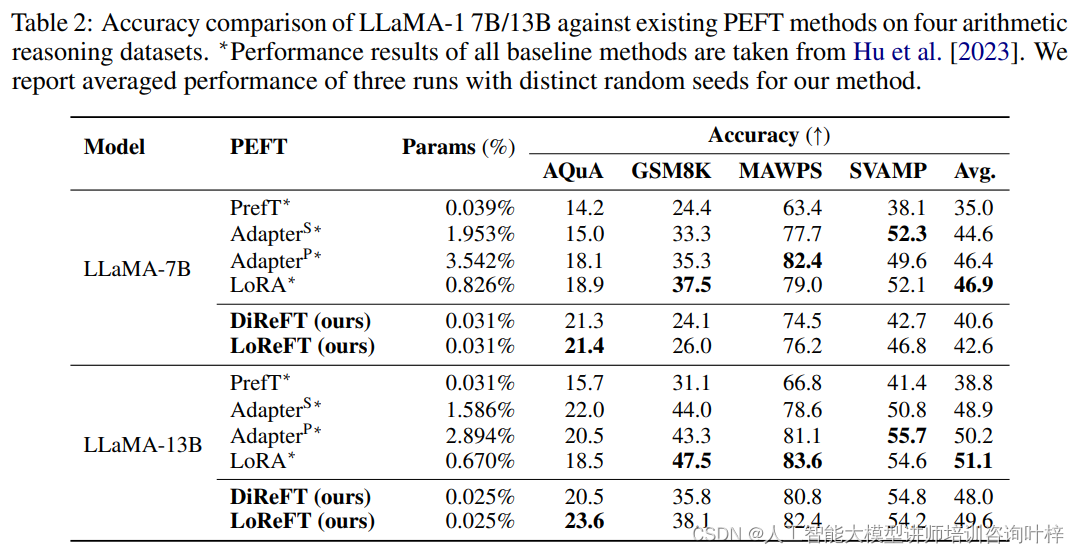
算术推理任务要求模型解决数学问题并生成解题步骤。研究者们在AQuA、GSM8K、MAWPS和SVAMP等数据集上进行了实验。尽管ReFT方法在这类任务上的表现不如某些PEFT方法,但它们在模型规模较大时仍然能够提供竞争力的性能,显示出ReFT方法在处理复杂推理任务上的潜力。
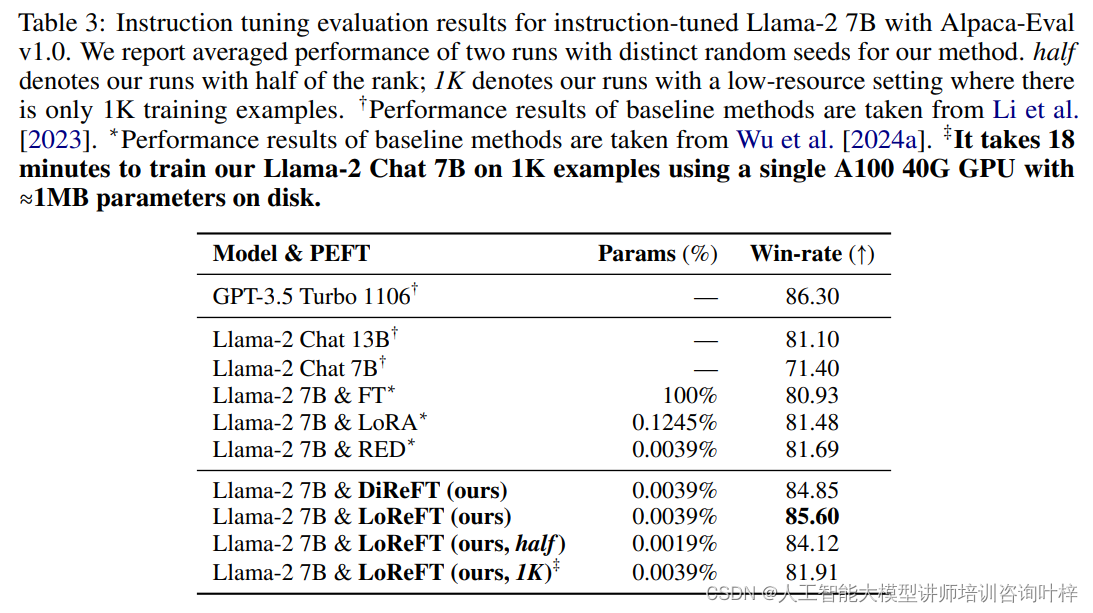
指令遵循任务测试模型根据给定指令生成响应的能力。研究者们使用了Ultrafeedback数据集,并与全参数微调、LoRA和RED等方法进行了比较。LoReFT在参数数量相同的情况下,不仅在性能上超越了其他方法,而且在减少参数数量或使用较少训练数据时仍然保持了较高的性能。
自然语言理解是NLP中的核心任务之一,涉及多个子领域,如情感分析、自然语言推理等。研究者们在GLUE基准测试中评估了ReFT方法,该基准测试包括了多个不同的自然语言理解任务。实验结果显示,LoReFT在这些任务上与现有的PEFT方法相比具有竞争力,证明了ReFT方法在小规模语言模型上的有效性。
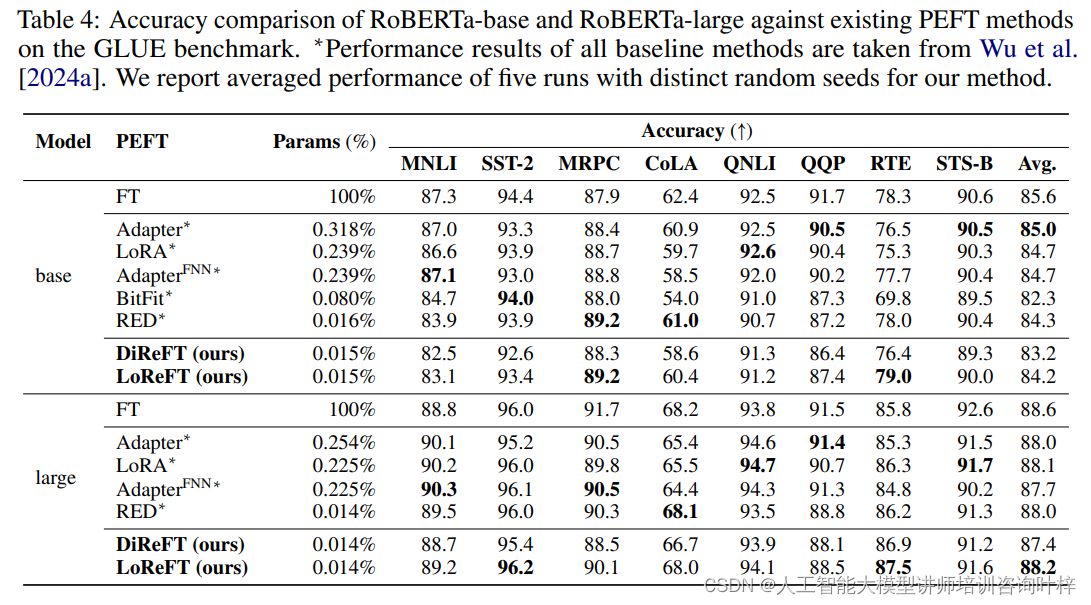
通过一系列实验证明了ReFT方法不仅在常识推理、算术推理、指令遵循和自然语言理解等任务上取得了优异的性能,而且相比于传统的参数高效微调方法,ReFT展现出了更高的参数效率和更好的泛化能力。
尽管ReFT方法取得了令人鼓舞的成果,但也存在一些问题,如,ReFT方法的超参数选择对最终性能有显著影响,而找到最优的超参数组合可能需要大量的实验和调整。尽管ReFT在多个任务上表现良好,但其在某些特定类型的任务上可能不如其他专门设计的PEFT方法。ReFT方法的干预机制虽然提供了对模型行为的控制,但这种控制的精确性和可解释性仍需进一步研究和改进。
未来的工作将集中在以下几个方面:一是自动化超参数调优过程,以减少手动调整的工作量并提高效率;二是探索ReFT在更多类型的任务和不同规模的模型上的应用,以验证其泛化能力;三是深入研究ReFT干预的可解释性,以及如何更好地理解和利用这些干预来改进模型的决策过程。
论文链接:https://arxiv.org/abs/2404.03592
GitHub 地址:https://github.com/stanfordnlp/pyreft
这篇关于ReF:斯坦福提出的新型语言模型微调方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



