新型专题

【IEEE出版】2024博鳌新型电力系统国际论坛——电力系统与新能源技术创新论坛(NPSIF 2024,10月30-11月1)
2024博鳌新型电力系统国际论坛——电力系统与新能源技术创新论坛将于2024年10月30-11月1日于海南博鳌举办。 会议的历史悠久,致力于促进电力系统领域的研究和开发活动,同时也着眼于促进全球各地研究人员、开发人员、工程师、学生和从业人员之间的科学信息交流,推动新能源技术的创新和应用,为全球能源领域的可持续发展贡献力量。期待着各方专家学者的共同参与和卓越贡献,共同开创电力系统未来的新篇章。

新型 RAMBO 侧信道攻击通过 RAM 无线电波泄露数据
内盖夫本·古里安大学的研究人员发现了一种从隔离系统中泄露敏感数据的方法。 引入了一种称为 RAMBO(基于 RAM 的电磁隐蔽通道)的新型攻击技术。 该攻击利用计算机 RAM 产生的电磁辐射,使攻击者能够窃取加密密钥、密码、生物特征数据和文件等信息。 即使在系统与外部网络物理隔离的环境中,这种攻击也能实现。 信息泄露速度达 7.5 kB/分钟 该研究由 Morde

新型PyPI攻击技术可能导致超2.2万软件包被劫持
一种针对 Python 软件包索引(PyPI)注册表的新型供应链攻击技术已在野外被利用,并且目前正试图渗透到下游组织中。 软件供应链安全公司 JFrog 将其代号定为Revival Hijack,并称这种攻击方法可用于劫持 2.2万个现有 PyPI 软件包,并导致数十万次恶意软件包下载。这些易受攻击的软件包下载量已超过 10 万次,或已活跃超过 6 个月。 JFrog安全研究人员And

谷歌提出新型半监督方法 MixMatch
事实证明,半监督学习可以很好地利用无标注数据,从而减轻对大型标注数据集的依赖。而谷歌的一项研究将当前主流的半监督学习方法统一起来,得到了一种新算法 MixMatch。该算法可以为数据增强得到的无标注样本估计(guess)低熵标签,并利用 MixUp 来混合标注和无标注数据。实验表明,MixMatch 在许多数据集和标注数据上获得了 STOA 结果,展现出巨大优势。例如,在具有 250

面向新型工业化的国产工业软件架构!
尽管我国工业软件技术体系化、系统化与产品化水平还比较低,但是基于我国极其全面的工业门类、高水平的工业装备和深入的产学研用合作模式,我国几乎在所有的工业软件技术领域都存在大量具有一定水平的技术成果和系统。我国工业软件并非要解决从无到有的问题,而是要解决小而散、产品化水平低以及没有形成产业生态的发展性问题。

新型蜜罐有哪些?未来方向如何?
前言:技术发展为时代带来变革,同时技术创新性对蜜罐产生推动力。 一、新型蜜罐的诞生 技术发展为时代带来变革,同时技术创新性对蜜罐产生推动力,通过借鉴不同技术思想、方法,与其它技术结合形成优势互补,如引入兵家作战思想的阵列蜜罐,结合生物保护色与警戒色概念的拟态蜜罐,利用人工智能、大数据等工具提高防护能力的蜜罐等,实验证实创新思想结合或技术优势集成后的系统具有较高的防御性能、诱骗能力。 创
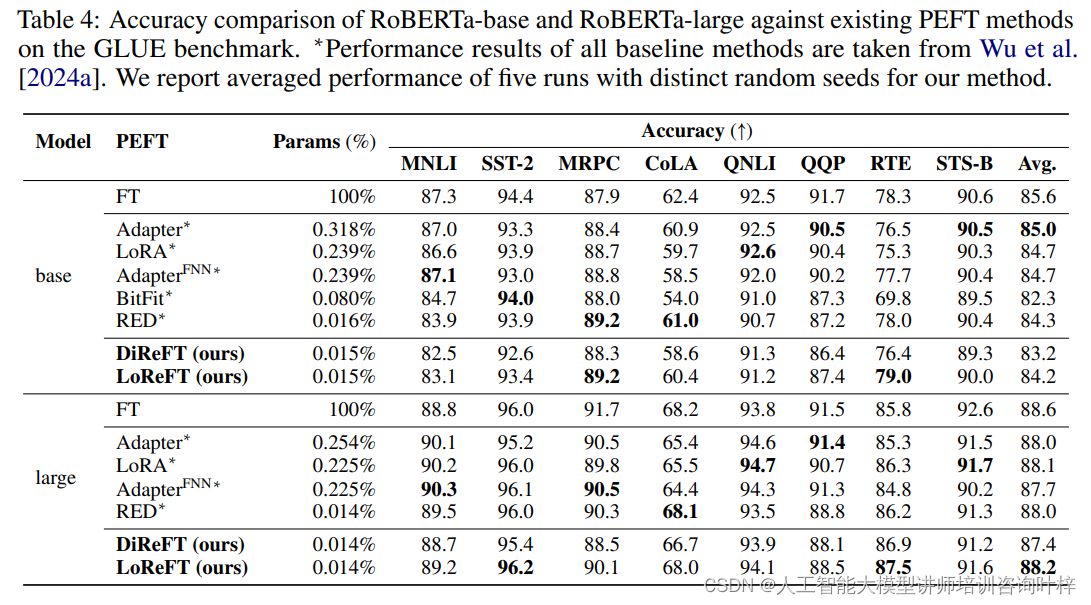
ReF:斯坦福提出的新型语言模型微调方法
随着预训练语言模型(LMs)在各种自然语言处理(NLP)任务中的广泛应用,模型微调成为了一个重要的研究方向。传统的全参数微调方法虽然有效,但计算成本高昂,尤其是在大型模型上。为了解决这一问题,来自斯坦福大学和 Pr(Ai)⊃2;R Group 的研究团队推出一种全新的微调方法——表征微调(ReFT)。ReFT方法的核心优势在于,它不直接对模型权重进行更新,而是通过学习对隐藏层表征的特定干预来适应下


Latte:新型【开源】的视频扩散变换器
在人工智能的浪潮中,视频生成技术正逐渐从梦想走向现实。Latte,一种新型的视频扩散变换器(Video Diffusion Transformer),以其独特的技术架构和卓越的性能,正在引领这一领域的新潮流。视频生成技术的核心挑战在于如何从零开始,生成既连贯又逼真的视频内容。随着深度学习技术的不断进步,一种新型的视频生成模型——Latte,以其基于扩散机制的变换器架构,为这一挑战提供了全新的解决方

基于新型切片轮廓转换超分辨率的深度生成网络的高分辨率3D MRI重建
高分辨率磁共振成像(MRI)序列,如3D Turbo或快速自旋回波(TSE/FSE)成像,在临床上备受欢迎,但在转换成首选方向时往往因扫描时间过长而产生模糊问题。因此,常常采用多层面二维(2D)TSE成像,因其高平面分辨率而被广泛使用,但在临床上由于体素拉长和由于阶梯状伪影而导致的横向分辨率不佳,以及由于无法生成多平面重建而受到限制。因此,需要在不同的正交成像平面上获取多个2D TSE扫描,而这样

国资委指明国企数字化转型方向:构建数据中台新型IT架构
在稳步迈入数字经济时代的大背景下,数字生产、数字生活触手可及,企业为保证高质量发展,构建智慧企业,数字化转型势在必行。 国务院国资委正式印发《关于加快推进国有企业数字化转型工作的通知》,系统明确国有企业数字化转型的基础、方向、重点和举措,开启了国有企业数字化转型的新篇章。 《通知》明确指出,要探索构建适应企业业务特点和发展需求的“数据中台”等新型IT架构模式,建设敏捷高效可复用的新一代数
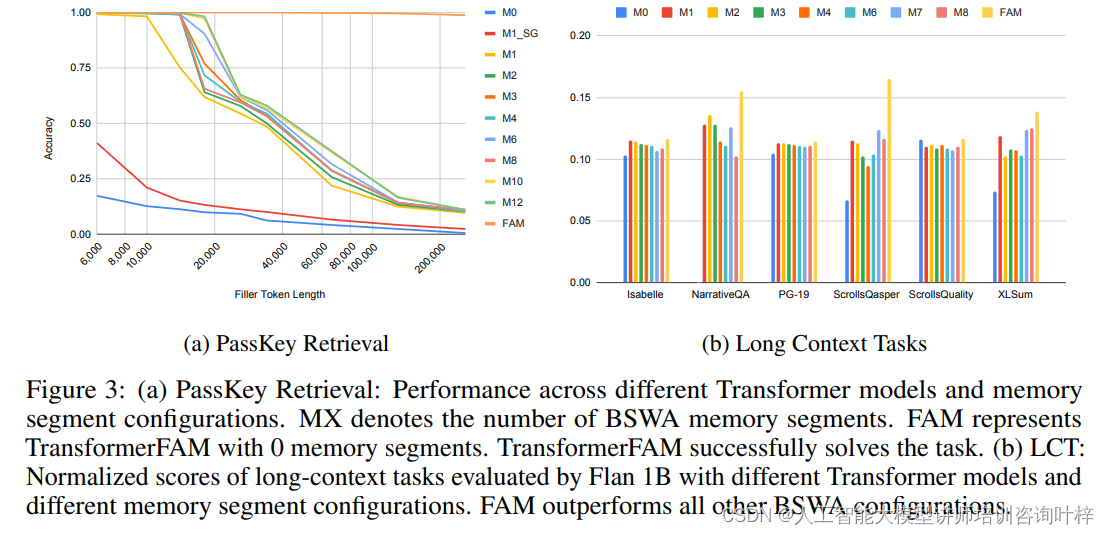
TransformerFAM:革新深度学习的新型注意力机制
深度学习领域的一项突破性技术——Transformer架构,已经彻底改变了我们处理序列数据的方式。然而,Transformer在处理长序列数据时面临的二次复杂度问题,限制了其在某些应用场景下的潜力。针对这一挑战,研究者们提出了一种名为TransformerFAM(Feedback Attention Memory)的新型架构,旨在通过引入反馈循环,使网络能够关注自身的潜在表示,从而在Transfo


超越传统AI 新型多智能体系统MESA,探索效率大幅提升
探索多智能体强化学习的协同元探索 —— MESA 算法深度解读在多智能体强化学习(MARL)的征途中,如何高效探索以发现最优策略一直是研究者们面临的挑战。特别是在稀疏奖励的环境中,这一问题变得更加棘手。《MESA: Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action S
如何科学检测新型冠状病毒?
在全国的这场战疫中,我们每个人都密切关注着每时每刻的疫情动态,尤其是物质供应和新型冠状病毒的确诊情况。其中,作为检测新冠病毒的主力,核酸检测试剂盒常常出现在大家的视野中,那么它是怎么检测疑似患者携带有新型冠状病毒? 知己知彼 在识别新型冠状病毒之前我们先了解一下它: 这种病毒是一类具有包膜、基因组为线性单股正链的RNA病毒,颗粒呈圆形或椭圆形,直径约60-140nm。 需要注意的是
新型冠状病毒的信息汇总与分析 (形态,分类,基因组,进化,变异,流行病学)
文章目录 介绍冠状病毒形态分类基因组参考基因组序列蛋白质三维结构基因组流行病学分析基因组变异及进化树 介绍 新型冠状病毒,是一类具有包膜、基因组为线性单股正链的RNA病毒,颗粒呈圆形或椭圆形,直径约60-140nm。 正链意味着病毒进入细胞后就可以直接指导蛋白质合成,而且通过RNA聚合酶生成负链来进行自我复制 此次武汉发现的冠状病毒是新发现的在人类中传播的病毒株
重庆一号通V2011官方版[新型电信服务]
软件名称:重庆一号通 V2011官方版 [新型电信服务] 授权方式:免费软件 界面语言:简体中文 软件大小:1.34MB 所属专题:图形图像 运行环境:WinXP,Win2003,Vista,Win7系统 推荐星级: 发布时间:2013-07-09 11:28:14 来源网址:XP系统下载之家 杀毒检测:通过卡巴斯基、360杀毒、瑞星、金山毒霸等杀毒软件测试 重庆一号通业务是一项新

Aya 23 是 Cohere For AI 推出的一款最先进的新型多语言开放重量模型
相信一些对LLM关注较高的同学们,应该对这家加拿大的Cohere不会太陌生。毕竟此前,它就开源过 Aya 101 和 Command R 这两款大模型。 Cohere 的非营利性研究实验室 Cohere for AI 发布了 Aya 23,这是其多语言大型语言模型 (llm) 的第二次迭代。这个最先进的 LLM 有 8B 和 35B 开放权重两种版本,支持 23 种语言,优于其前身 Aya 10

每日AIGC最新进展(10):符号音乐生成SYMPLEX、新型图像编辑数据集ReasonPix2Pix、角色一致性插画生成、高级的风格个性化扩散模型
Diffusion Models专栏文章汇总:入门与实战 SYMPLEX: Controllable Symbolic Music Generation using Simplex Diffusion with Vocabulary Priors http://arxiv.org/abs/2405.12666v1 本文介绍了一种新的符号音乐生成方法,名为SYMPLEX,它基于单纯
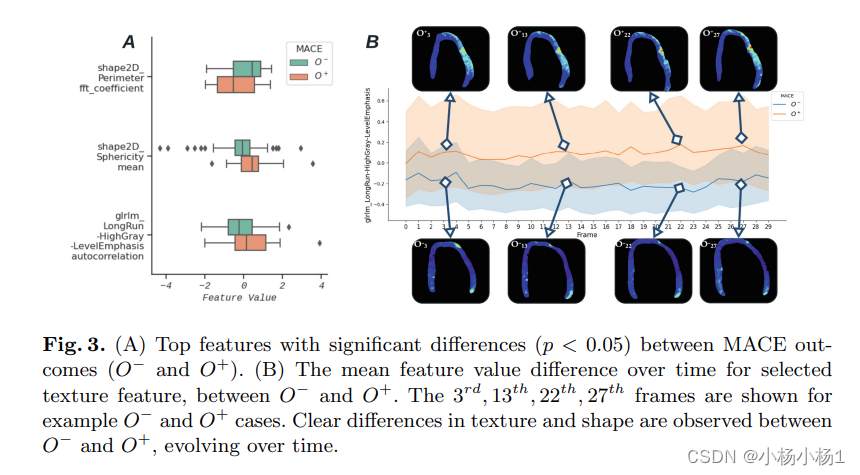
STAR-Echo:一种使用时空分析和基于Transformer的影像组学模型预后慢性肾脏病患者 MACE 预后的新型生物标志物
文章目录 STAR-Echo: A Novel Biomarker for Prognosis of MACE in Chronic Kidney Disease Patients Using Spatiotemporal Analysis and Transformer-Based Radiomics Models摘要方法实验结果 STAR-Echo: A Novel Biom

2019新型冠状病毒来势汹汹我们无需恐慌(可防可控),但也不得不防(存在的“人传人”的风险)
【作为一个普通市民想要了解的“新型冠状病毒”的知识点整理】 一、病毒传染途径 1、病毒简介 冠状病毒是一个大型病毒家族,已知可引起感冒以及中东呼吸综合征(MERS)和严重急性呼吸综合征(SARS)等较严重疾病。冠状病毒分为α、β、γ三个属,是一类主要引起呼吸道、肠道疾病的病原体。这类病毒颗粒的表面有许多规则排列的突起,整个病毒颗粒就像一顶帝王的皇冠,因此得名“冠状病毒”。目前已知的感染人的冠
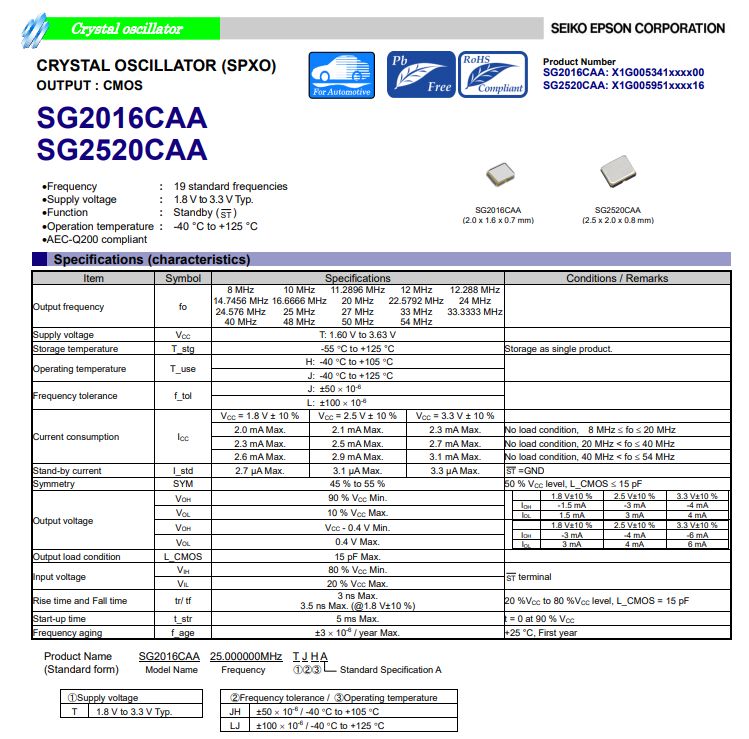
具有CMOS输出,高速响应特点的新型汽车级晶振SG2520CAA
爱普生推出的汽车级晶振SG2520CAA。SG2520CAA是一款CMOS输出的,具有高响应速度的2520封装汽车级晶振,具有低电流消耗,1.6 V至3.63 V的宽工作电压,以及-40°C至85°C的宽工作温度范围,此外还可提供高达125°C的工作温度。符合AEC-Q200标准,是汽车和高可靠性应用的理想选择SG2520CAA晶体振荡器输出频率范围在1

4D 成像毫米波雷达:新型传感器助力自动驾驶
1 感知是自动驾驶的首要环节,高性能传感器必不可少 感知环节负责对侦测、识别、跟踪目标,是自动驾驶实现的第一步。自动驾驶的实现,首先要能够准确理解驾驶环境信息,需要对交通主体、交通信号、环境物体等信息进行有效捕捉,根据实时感知的环境信息,自动驾驶系统得以完成接下来的决策、规划与控制等环节。传感器的性能会直接影响到感知信息的质量,目前广泛搭载的传感器有摄像头、激光雷达、毫米波雷达、

Bumblebee X系列用于高精度机器人应用的新型立体视觉产品
Bumblebee X是最新的GigE驱动立体成像解决方案,为机器人引导和拾取应用带来高精度和低延迟。 近日,51camera的合作伙伴Teledyne FLIR IIS推出一款用于高精度机器人应用的新型立体视觉产品Bumblebee X系列。 Bumblebee X产品图 Bumblebee®X系列,一个基于一流立体视觉产品组合的先进立体视觉解决方案。FLIR研究立体视觉解决方案的

作为新型锂离子电池正极材料 磷酸锰铁锂(LMFP)行业发展空间有望扩展
作为新型锂离子电池正极材料 磷酸锰铁锂(LMFP)行业发展空间有望扩展 磷酸锰铁锂(LMFP)指在磷酸铁锂基础上添加锰元素而制成的新型磷酸盐类锂离子电池正极材料。磷酸锰铁锂含有橄榄石型结构,生产成本低、能量密度高、绿色环保、结构稳定性好等为其主要优势,在消费电子、新能源汽车以及储能系统等领域拥有广阔应用前景。 锂离子电池正极材料种类丰富,主要包括磷酸铁锂、锰酸锂、钴酸锂以

拥抱新质生产力,助力新型工业化!CMM电子展暨IARS机器人展5月东莞盛大起航
2024年5月15-17日,东浩兰生会展集团旗下CMM电子展&IARS机器人展将在广东现代国际展览中心(东莞厚街)举办。展会面积达50000平方米,展示品牌700余个,同期论坛峰会30余场,预计专业观众超50000人次。千家智能制造行业企业高管、专业买家、技术骨干汇聚一堂,共同见证新技术,展望新未来。 拥抱新质生产力,助力新型工业化 CMM电子展&IARS华南机器人展是东浩兰生展会集团