本文主要是介绍超越传统AI 新型多智能体系统MESA,探索效率大幅提升,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

探索多智能体强化学习的协同元探索 —— MESA 算法深度解读在多智能体强化学习(MARL)的征途中,如何高效探索以发现最优策略一直是研究者们面临的挑战。特别是在稀疏奖励的环境中,这一问题变得更加棘手。《MESA: Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action Space Structure》这篇论文为我们带来了一种新颖的解决方案——MESA算法,它通过利用状态-动作空间的结构,实现了多智能体间的协同元探索,显著提升了在复杂任务中的探索效率。Zhicheng Zhang、Yancheng Liang、Yi Wu和Fei Fang等研究者们精心设计的MESA算法,在多步矩阵游戏和连续控制任务中展现了其卓越的性能。它不仅能够有效地促进智能体在测试任务中的学习,还能泛化至更具挑战性的未见任务。
通过这篇文章,您将获得:
高效探索策略:了解MESA如何通过元探索方法提升多智能体学习的探索效率。
结构化学习方法:探索MESA如何识别高奖励的状态-动作子空间,并训练多样化的探索策略。
实际应用案例:通过MESA在多智能体粒子环境和MuJoCo环境中的实验,见证其在实际应用中的显著成效。
引言:多智能体系统中的探索挑战
在多智能体系统(MAS)中,探索是一个核心问题,尤其是在合作或竞争环境下。有效的探索策略可以显著提高学习效率,帮助智能体更快地适应环境并找到最优策略。然而,多智能体环境的复杂性,如状态空间的指数增长和部分可观测性,使得传统的单智能体探索方法往往不再适用。
在多智能体环境中,每个智能体的行为不仅影响自己的收益,还可能影响其他智能体的收益,这增加了探索的难度。例如,一个智能体的探索行为可能会导致环境状态变化,从而影响到其他智能体的决策。此外,智能体需要在探索新策略和利用已知策略之间找到平衡,这在多智能体设置中尤为复杂。
为了应对这些挑战,研究者们提出了多种多智能体探索策略,旨在通过协作或竞争来优化整体或个体的性能。这些方法通常需要在探索效率和计算复杂性之间做出权衡。有效的多智能体探索不仅能加速学习过程,还能在复杂的环境中促进更高级别的策略和协作形成。
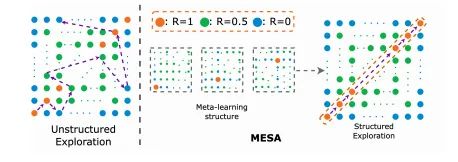
论文基本信息
标题:MESA: Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action Space Structure
作者:
- Zhicheng Zhang, Carnegie Mellon University, Pittsburgh, Pennsylvania, United States
- Yancheng Liang, University of Washington, Seattle, Washington, United States
- Yi Wu, Tsinghua University, Beijing, China
- Fei Fang, Carnegie Mellon University, Pittsburgh, Pennsylvania, United States
机构:
- Carnegie Mellon University
- University of Washington
- Tsinghua University
论文链接:https://arxiv.org/pdf/2405.00902.pdf
MESA方法概述
MESA(Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action Space Structure)是一种针对多智能体学习的元探索方法,旨在通过利用状态-动作空间结构来提高探索效率。在多智能体强化学习(MARL)中,探索效率尤为关键,因为环境的复杂性和智能体间的交互增加了学习的难度。MESA通过在元训练阶段识别高奖励的状态-动作子空间,并训练一组多样化的探索策略来覆盖这一子空间,从而实现高效的探索。这些探索策略在元测试阶段被用来辅助智能体在新任务中的学习。
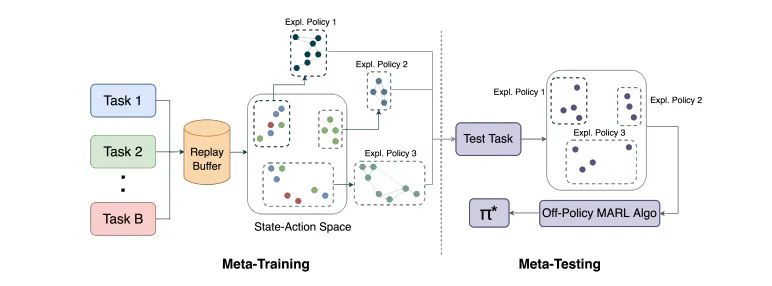
元训练阶段详解
1. 高奖励状态-动作子空间的识别
在元训练阶段的第一步,MESA需要确定哪些状态-动作对能够带来高奖励。这一过程涉及到在多个训练任务中收集数据,并从中筛选出奖励高于某个阈值的状态-动作对。这些被认为是有价值的状态-动作对将被存储在一个数据集M*中,用于后续的探索策略训练。对于目标导向的任务,这个阈值可以是达到目标状态的奖励。
2. 探索策略的训练和奖励机制
在识别了高奖励的状态-动作子空间后,MESA将训练一组探索策略来有效覆盖这一子空间。这些探索策略的训练使用了基于距离高奖励子空间的距离来诱导的奖励机制。具体来说,如果一个访问的状态-动作对足够接近已识别的高奖励子空间(即,它与子空间中的某个点的距离小于某个阈值ε),它将获得一个正的派生奖励。为了鼓励探索策略覆盖更广泛的子空间并避免模式崩溃,MESA采用了一种奖励分配方案,确保对相似的状态-动作对的重复访问会得到递减的奖励。
通过这种方式,MESA不仅提高了探索的效率,还通过元学习框架使得智能体能够在面对新任务时迅速适应,展现出良好的泛化能力。这一方法已在多种任务中得到了验证,包括矩阵攀爬游戏和连续控制任务,与现有的多智能体学习和探索算法相比,MESA显示出了优越的性能。
元测试阶段应用
在元测试阶段,MESA(Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action Space Structure)利用在元训练阶段学习到的探索策略来辅助多智能体在未见过的任务中的学习。这些探索策略是从一组训练任务中学习得到的,这些任务在状态-动作空间中具有内在的结构特征。在元测试阶段,MESA通过随机选择已学习的探索策略来收集有价值的经验,从而帮助智能体更有效地学习良好的联合策略。
1. 探索策略的应用:在每个回合中,MESA以一定的概率执行一个随机选取的探索策略。这些探索策略在初始阶段提供更多的回合,以帮助智能体快速适应新环境,随后逐渐减少探索策略的使用,转而让智能体依赖其自身的学习成果。
2. 策略的效果评估:MESA的探索策略在多个环境中表现出色,包括矩阵攀登游戏及其多阶段变体和连续控制任务。这些策略不仅提高了探索效率,还显示出对未见测试任务的泛化能力,这些测试任务比任何训练任务都要具有挑战性。
实验设计与评估
MESA的实验设计旨在评估元学习探索策略在新任务中的表现,并与其他多智能体学习和探索算法进行比较。实验在不同的环境中进行,包括矩阵攀登游戏的变体、多智能体粒子环境(MPE)和多智能体MuJoCo基准测试。
1. 实验设置:实验比较了MESA与其他几种多智能体强化学习算法,如MADDPG、MAPPO和QMIX,以及几种探索算法,如MAVEN和基于RND的探索。此外,还测试了几种采用类似元训练阶段的基线方法,包括未条件共享策略和目标条件策略。
2. 评估方法:评估主要关注探索策略在元测试阶段的表现,特别是它们在新采样任务中的探索效率。通过与基线方法的比较,展示了MESA在攀登游戏变体和高维领域任务中的优势。此外,还研究了这些探索策略在更具挑战性的测试任务分布中的泛化性能。
通过这些详尽的实验设计和评估,MESA证明了其在多智能体学习中应用元探索方法的有效性,尤其是在处理结构化探索任务和高维控制问题时的优势。
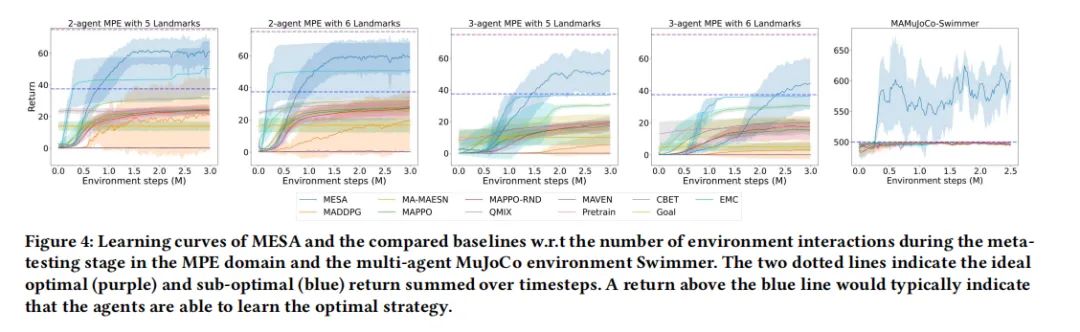

结果分析与讨论
1. MESA在Climb Game变体中的表现
MESA在Climb Game的变体中表现出色。在单步Climb Game中,MESA能够在一些更困难的任务中找到最优解,而其他基线方法则几乎在所有任务中停留在次优解。在多阶段Climb Game中,由于任务空间指数级增长,MESA的表现远超其他算法。通过已学习的探索策略,MESA能够迅速学习每个阶段的最优联合动作,避免陷入次优解。
2. MESA在多智能体MuJoCo环境中的应用
在多智能体MuJoCo环境中,MESA同样展现了优异的性能。特别是在2-agent Swimmer环境中,MESA通过学习的探索策略,频繁地达到目标角度,显著优于其他基线方法。这一环境极为复杂,因为智能体很可能收敛到次优的奖励,但MESA通过有效的探索策略,成功地学习到了最终策略,频繁地达到目标状态。
3. MESA的泛化能力评估
MESA在未见测试任务上的泛化能力表现突出。尤其是在任务分布更具挑战性的情况下,MESA展现了良好的零样本泛化能力。通过在简单任务上训练的探索策略,MESA能够在更难的测试任务上加速训练性能,连续达到高奖励区域,而标准的MADDPG算法则只能学习到次优平衡。

MESA方法的优势与局限
优势
- 结构化探索策略:MESA通过在训练阶段识别高奖励的状态-动作子空间,并训练一组探索策略来覆盖这一子空间,从而实现高效的结构化探索。
- 优异的泛化能力:MESA展现了在从简单任务到复杂任务的泛化能力,这得益于其能够利用训练任务中学到的结构化探索策略。
- 与现有算法的兼容性:MESA可以与任何离策略的多智能体强化学习算法结合使用,提高了其适用性。
局限
- 依赖于任务结构的显式识别:MESA的性能高度依赖于在训练阶段正确识别出高奖励的状态-动作子空间。如果这一子空间识别不准确,可能会影响探索策略的有效性。
- 计算资源需求:由于需要在多个任务上训练探索策略,MESA可能需要较多的计算资源,尤其是在任务空间较大时。
- 对高奖励状态的依赖:MESA的探索策略训练依赖于高奖励状态的采集,这在奖励稀疏的环境中可能是一个挑战。
总结与未来展望
在本文中,我们介绍了一种新的多智能体元探索方法MESA(Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action Space Structure),该方法通过利用状态-动作空间结构来提高多智能体学习的探索效率。MESA框架在元训练阶段通过一系列训练任务学习探索策略,并在元测试阶段利用这些策略帮助智能体在未见过的任务中进行学习。我们的实验结果显示,MESA在多种环境和任务中均优于现有的多智能体学习和探索算法,尤其是在需要协调探索的复杂环境中。
1. 主要贡献
MESA的主要贡献在于其能够有效地识别和利用训练任务中的高奖励状态-动作子空间,从而训练出一组多样化的探索策略。这些策略在元测试阶段被用来引导智能体探索新任务,显著提高了学习效率和策略性能。此外,MESA展示了良好的泛化能力,能够将在相对简单的任务中学到的探索策略成功应用于更复杂的测试任务,从而解决了多智能体系统中的探索难题。
2. 实验验证
通过在不同的游戏和控制任务中进行广泛的实验,包括Climb Game变体和多智能体MuJoCo环境,MESA不仅在学习效率上超过了其他基线方法,还在多阶段游戏和高维任务中表现出卓越的性能。这些结果验证了MESA探索策略的有效性和适应性。
3. 未来工作
尽管MESA已经取得了一定的成功,但仍有一些潜在的改进空间和未来的研究方向。例如,如何进一步优化探索策略的学习过程,减少所需的训练任务数量,以及如何更好地处理动态变化的环境和任务。此外,探索如何将MESA扩展到非合作或竞争性的多智能体环境中也是未来研究的一个重要方向。
总之,MESA为解决多智能体系统中的协同探索问题提供了一个有效的框架,并为未来在更广泛的应用领域中推广元探索策略奠定了基础。我们期待看到MESA在更多实际应用中的表现,并希望它能激发更多关于多智能体学习和探索的研究。
这篇关于超越传统AI 新型多智能体系统MESA,探索效率大幅提升的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






