本文主要是介绍每日AIGC最新进展(10):符号音乐生成SYMPLEX、新型图像编辑数据集ReasonPix2Pix、角色一致性插画生成、高级的风格个性化扩散模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Diffusion Models专栏文章汇总:入门与实战
SYMPLEX: Controllable Symbolic Music Generation using Simplex Diffusion with Vocabulary Priors
http://arxiv.org/abs/2405.12666v1

本文介绍了一种新的符号音乐生成方法,名为SYMPLEX,它基于单纯形扩散(Simplex Diffusion,SD)模型,通过操作概率分布而非信号空间来生成音乐。该方法利用词汇表先验(vocabulary priors)来控制音乐的生成过程,允许在不进行任务特定模型调整或应用外部控制的情况下,对时间和音高进行填充、选择乐器等。
SYMPLEX模型采用SSD-LM作为基础,SSD-LM是一种基于窗口的单纯形扩散模型,用于生成任意长度的自然语言序列。与SSD-LM处理序列不同,SYMPLEX操作的是一组包含9个属性的音符事件集合。模型通过训练神经网络从噪声概率中恢复数据样本,并在生成新样本时,从随机初始化的概率开始,逐步迭代细化。此外,通过将词汇表先验与当前概率相乘并重新归一化,可以在不依赖外部模型的情况下控制生成过程。
作者从MetaMIDI数据集中提取了4小节多乐器MIDI循环,并构建了一个包含约25万个循环的数据集。他们使用了一种无序集合表示法来表示MIDI循环,每个音符事件包含9个属性。实验中,SYMPLEX在多个任务上进行了演示,包括无条件生成、有条件生成以及多种编辑任务。作者还讨论了未来工作,包括如何避免根据不同生成场景调整参数设置,以简化工作流程。
ReasonPix2Pix: Instruction Reasoning Dataset for Advanced Image Editing
http://arxiv.org/abs/2405.11190v1

本文介绍了一个名为ReasonPix2Pix的新型图像编辑数据集,旨在提升生成模型在遵循人类指令进行图像编辑时的推理能力。现有的图像编辑模型通常只能理解明确具体的指令,但在处理隐含或定义不明确的指令时表现出推理能力的不足。为了解决这一问题,研究者们创建了ReasonPix2Pix,这是一个包含推理指令、更真实图像和输入与编辑图像之间更大变化的数据集。
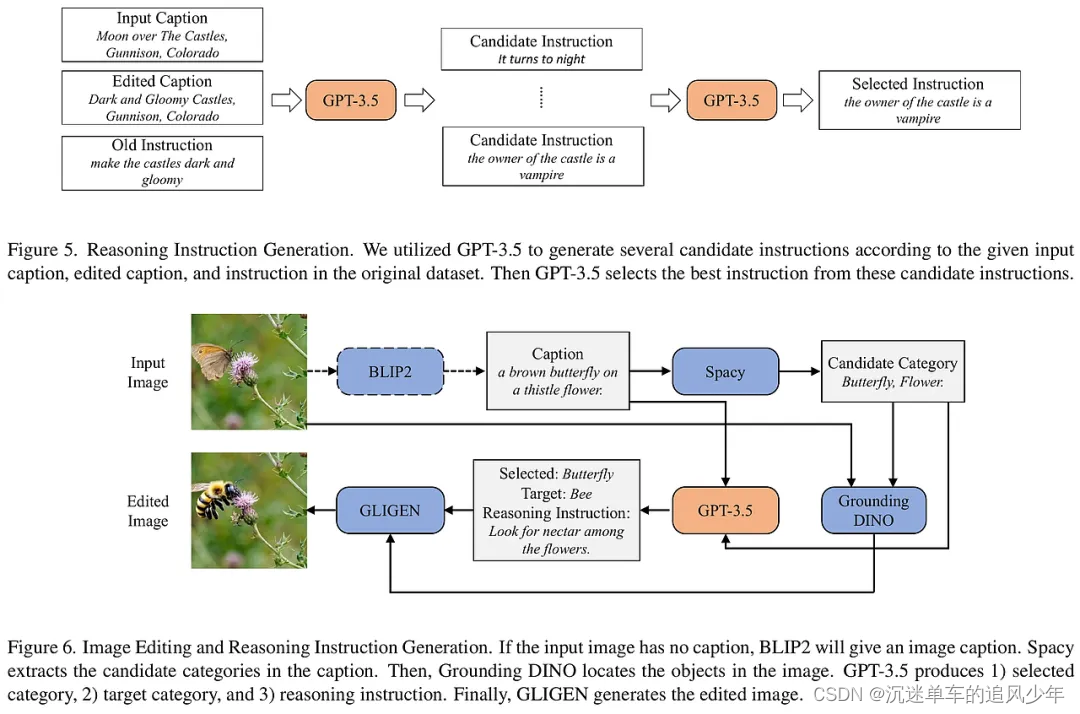
ReasonPix2Pix数据集通过三个部分来增强模型的推理能力:第一部分利用InstructPix2Pix数据集中的图像对,生成推理指令;第二部分和第三部分则通过生成新的编辑图像和指令来提升模型对现实图像的编辑能力。研究者们还结合了多模态大型语言模型(MLLM)和扩散模型来构建一个简单的框架,该框架能够理解指令的明确或隐含意图,并生成符合指令的输出图像。

在实验部分,研究者们使用了GPT-3.5-turbo生成数据集,并采用了Stable Diffusion v1.5和LLaVA-7Bv1.5进行微调。他们将图像大小调整为256×256,并在训练期间使用了基础学习率。通过定性和定量的实验结果,证明了ReasonPix2Pix在不需要推理和需要推理的指令编辑任务中均展现出优越的性能。用户研究也表明,当指令变得更加隐含时,ReasonPix2Pix与先前方法相比具有更大的优势。最后,研究者们讨论了数据集的局限性,并指出了数据集规模因API成本而受限,但提供了清晰的数据生成流程,以便研究人员可以扩展数据集规模。
Evolving Storytelling: Benchmarks and Methods for New Character Customization with Diffusion Models
http://arxiv.org/abs/2405.11852v1
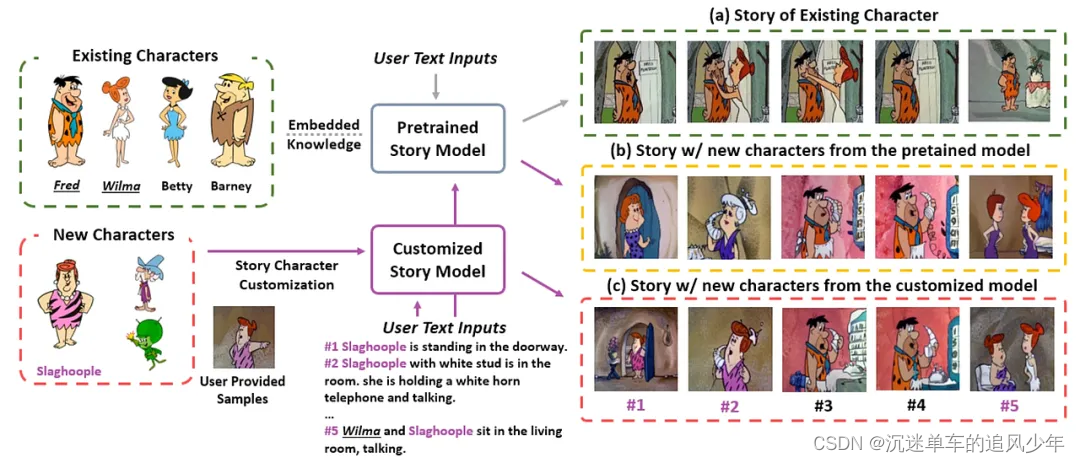
本文探讨了如何将新角色有效地融入现有叙事中,并保持角色一致性的问题,特别是在数据有限的情况下。作者指出,现有的故事可视化生成模型在整合新角色时存在两大限制:缺乏合适的基准测试和新旧角色区分的挑战。为了解决这些问题,作者提出了"NewEpisode"基准测试,包含经过改进的数据集,用于评估生成模型在仅使用单一示例故事生成新故事的能力。


作者引入了"EpicEvo"方法,这是一种定制的扩散模型,用于视觉故事生成。"EpicEvo"通过一个新颖的对抗性角色对齐模块,在扩散过程中逐步对齐生成图像与新角色的示例图像,同时应用知识蒸馏来防止忘记角色和背景细节。这种方法使得模型能够学习如何生成包含现有角色和/或新角色的故事,并且通过对抗性角色对齐模块鼓励模型独特地生成角色,并通过从预训练模型中提取知识来保持模型先验。
为了验证"EpicEvo"的有效性,作者在"NewEpisode"基准测试上进行了定量和定性的研究。实验结果表明,"EpicEvo"在基准测试上的定量表现超过了现有的基线,并且通过质量研究确认了其在扩散模型中定制视觉故事生成的优越性。总结来说,"EpicEvo"提供了一种有效的方法,仅使用一个示例故事就能融入新角色,为诸如连载卡通等应用开辟了新的可能性。
TriLoRA: Integrating SVD for Advanced Style Personalization in Text-to-Image Generation
http://arxiv.org/abs/2405.11236v1
本文提出了一种名为TriLoRA的新方法,旨在改进文本到图像生成模型的微调过程,以实现更高级的风格个性化。现有的深度学习模型,如Stable Diffusion,在视觉艺术创作中应用广泛,但面临过拟合、生成结果不稳定和难以精确捕捉创造者所需特征等挑战。TriLoRA通过将奇异值分解(SVD)整合到低秩适应(LoRA)参数更新策略中,有效降低了过拟合风险,增强了模型输出的稳定性,并更准确地捕捉到创造者所需的微妙特征调整。
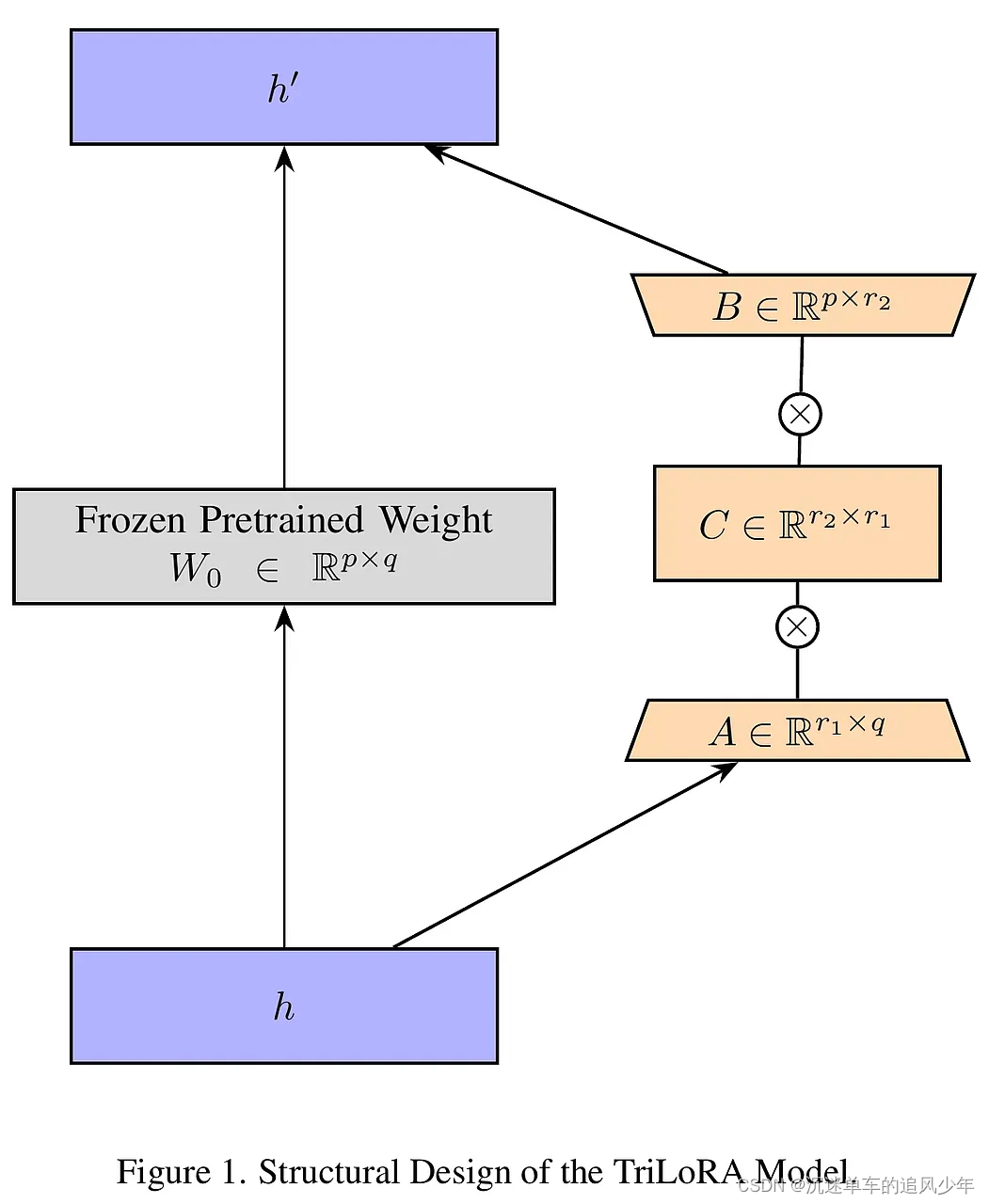
TriLoRA是在LoRA框架内引入SVD的概念,通过训练两个适配器:一个标准低秩适配器(LoRA)和一个更小的适配器,这两个适配器相对于原始预训练权重并行训练。该方法的创新之处在于使用紧凑奇异值分解(Compact SVD)来确定创造者关注的特定特征数量,从而提供更精确的选择空间。在TriLoRA框架中,通过将Compact SVD整合到LoRA中,优化了权重矩阵的更新,使得模型在保持较低参数数量的同时,提高了对新任务的适应性。

为了评估TriLoRA和LoRA在特定风格或主题中的适应性,作者构建了两个数据集:一个包含多种幻想生物的Pokemon数据集,另一个是专注于特定风格服装的GAC数据集。实验采用了标准化Fréchet Inception距离(Normalized FID)和CLIP分数作为主要的定量评估指标,并辅以用户研究以提供定性见解。实验结果表明,TriLoRA在多个数据集上的表现优于LoRA,具有更好的模型泛化能力和创造性表达,同时保持了效率和资源限制下的优异性能。用户研究结果也支持了TriLoRA在文本视觉一致性和视觉吸引力方面的优势。
这篇关于每日AIGC最新进展(10):符号音乐生成SYMPLEX、新型图像编辑数据集ReasonPix2Pix、角色一致性插画生成、高级的风格个性化扩散模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







