本文主要是介绍TransformerFAM:革新深度学习的新型注意力机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深度学习领域的一项突破性技术——Transformer架构,已经彻底改变了我们处理序列数据的方式。然而,Transformer在处理长序列数据时面临的二次复杂度问题,限制了其在某些应用场景下的潜力。针对这一挑战,研究者们提出了一种名为TransformerFAM(Feedback Attention Memory)的新型架构,旨在通过引入反馈循环,使网络能够关注自身的潜在表示,从而在Transformer中培养出工作记忆(working memory),使其能够处理无限长的序列。
TransformerFAM架构
TransformerFAM(Feedback Attention Memory)是一种创新的Transformer架构,它通过引入反馈机制来增强模型处理长序列的能力。
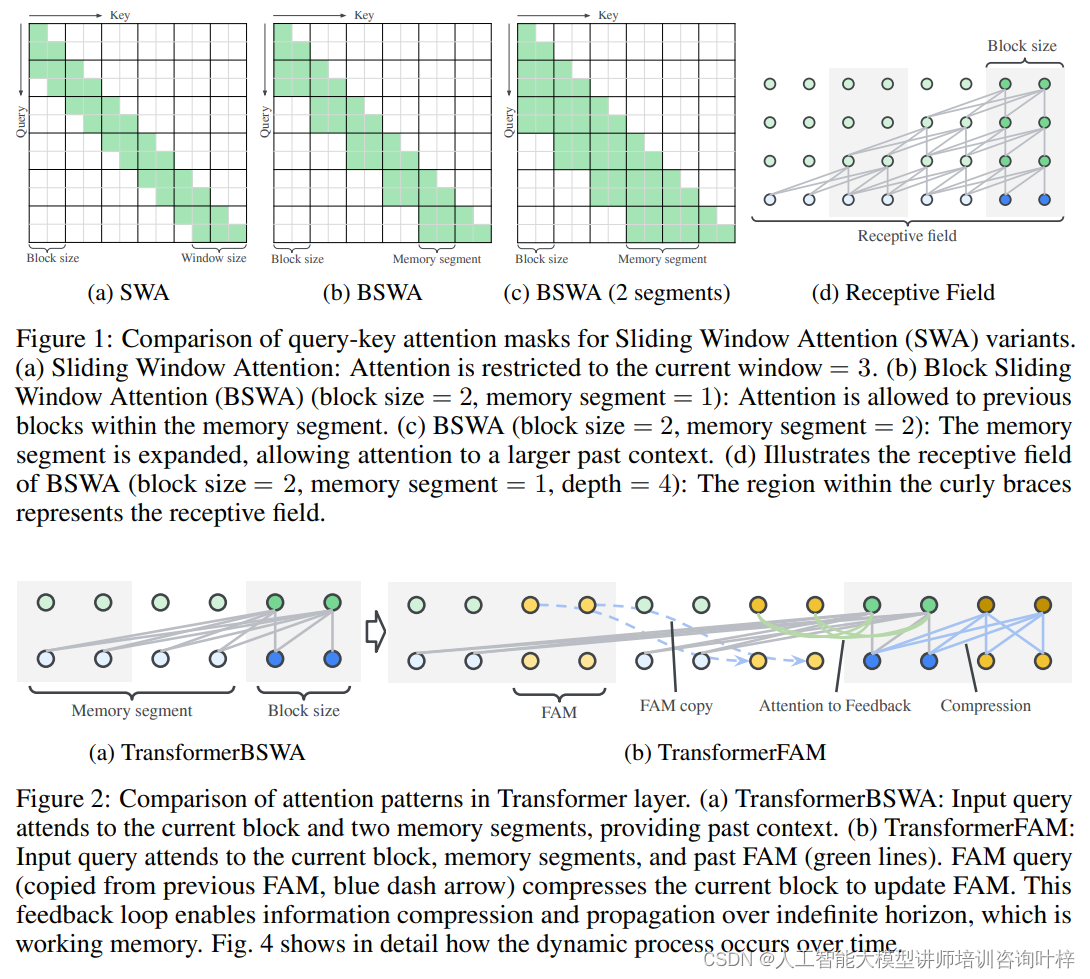
Figure 1: Sliding Window Attention (SWA) 变体的查询-键注意力掩码比较
-
(a) Sliding Window Attention (SWA): 这个图示展示了标准的滑动窗口注意力机制,其中注意力被限制在当前窗口内,窗口大小为3。这意味着每个token只关注它自身以及它左右两边的token。
-
(b) Block Sliding Window Attention (BSWA): 这里展示了BSWA的工作原理,其中块大小设置为2,记忆段设置为1。在这种设置下,注意力不仅可以关注当前块的token,还可以关注记忆段中的前一个块的token。
-
(c) BSWA (block size = 2, memory segment = 2): 这个图示进一步扩展了记忆段,使得注意力可以覆盖到更大的过去上下文。当记忆段扩展到2时,意味着当前块的token可以关注到更远的过去的两个块。
-
(d) Receptive Field of BSWA: 这个图示说明了BSWA的感知范围,即模型在处理信息时能够“看到”的上下文范围。图中的花括号区域代表了感知范围,展示了在给定的块大小和记忆段设置下,模型能够关注到的token范围。
Figure 2: Transformer层中的注意力模式比较
-
(a) TransformerBSWA: 这个图示展示了TransformerBSWA层中的注意力模式,输入查询(Q)关注当前块以及两个记忆段中的token,从而提供了过去的上下文信息。
-
(b) TransformerFAM: 在TransformerFAM中,输入查询不仅关注当前块和记忆段,还关注过去的FAM(反馈注意力记忆)。FAM查询是从上一个FAM复制过来的(以蓝色虚线箭头表示),它压缩当前块的信息以更新FAM。这个反馈循环使得信息可以在不确定的时间范围内进行压缩和传播,这就是工作记忆的体现。图4将更详细地展示这一动态过程是如何随时间发展的。
BSWA是TransformerFAM架构的核心,它是一种特别设计来处理长上下文输入的注意力机制。这种机制的关键在于它将输入序列分割成多个较小的块,然后对每个块分别应用滑动窗口注意力。这样做的好处是,模型可以在保持较高计算效率的同时,关注到更广泛的上下文信息。
Block Size的概念在这里起到了关键作用。它决定了每个块中应该包含多少个token,并且这个数量也作为滑动窗口移动的步长。通过合理设置Block Size,可以控制模型在处理序列时的粒度,使其既能捕捉到局部的依赖关系,又能在必要时通过滑动窗口覆盖更广的上下文。
与Block Size紧密相关的另一个概念是Memory Segment。Memory Segment的值决定了模型需要缓存多少过去的块。这个设置直接影响了模型回顾上下文信息的能力。简单来说,一个较大的Memory Segment值可以让模型记住更远的历史信息,但同时也会增加计算的负担。相反,较小的Memory Segment值可以减少计算量,但可能会限制模型的记忆力。
TransformerFAM的另一个关键创新——Feedback Attention Memory(FAM)。FAM是一种虚拟激活,它的设计目的是将上下文信息反馈到BSWA的每个块中。这种设计满足了几个关键要求:
首先是Integrated Attention,这意味着自注意力机制需要同时处理输入上下文和FAM。通过这种方式,模型在处理当前块时,不仅考虑了当前的信息,还考虑了之前处理过的信息,从而实现了对上下文的深入理解。
其次是Block-Wise Updates,这要求FAM在块与块之间转换时进行更新。这种更新机制确保了FAM能够随着模型处理新的数据块而不断演化,保持信息的新鲜度和相关性。
第三是Information Compression,FAM的更新应该基于先前的FAM来压缩当前块的信息。这种压缩机制是FAM能够有效存储和传递信息的关键,它允许模型在有限的资源下处理和存储更多的信息。
最后是Global Contextual Storage,FAM需要无限期地存储全面的上下文信息。这一点对于处理长序列尤为重要,因为它允许模型在处理序列的任何部分时,都能够访问到整个序列的上下文信息。
FAM通过将自己附加到块段,并将其纳入自注意力过程中,实现了上述要求。这样模型就能够在块之间动态地传播全局上下文信息,实现更加丰富的表示。这种动态的、全局的上下文信息传播,是TransformerFAM架构能够处理长序列的关键所在。通过这种方式,TransformerFAM不仅能够捕捉到局部的细节,还能够维护对整体上下文的深刻理解,这在处理复杂的语言任务时尤为重要。
TransformerFAM的工作流程描述了模型是如何通过一系列步骤来处理和记忆信息的:
初始化阶段: 在TransformerFAM开始工作之前,首先需要对FAM进行初始化。这是通过在模型的token嵌入查找阶段添加可学习的摘要嵌入来完成的。这些嵌入相当于是模型的"软提示",它们帮助模型在处理输入序列的最开始阶段就建立起对信息的初步理解和摘要。这个过程类似于我们在阅读一篇文章时,首先浏览一下文章的摘要或引言部分,以获得对文章内容的初步把握。
自注意力阶段: 一旦FAM初始化完成,模型就进入自注意力阶段。在这个阶段,当前处理块的输入查询不仅仅关注它自身的键值对,还会关注到之前块的FAM。这里的FAM起到了一个全局上下文信息的提供者的角色,它允许模型在处理当前块的同时,也能够考虑到之前处理过的信息。这种机制使得模型能够构建出一个比单纯BSWA更加丰富的信息表示。
FAM查询阶段: 接下来,FAM自身也会进行查询操作。FAM查询会同时关注当前块的信息和之前块的FAM键。这个过程可以看作是模型在对当前块进行压缩处理,它基于之前全局上下文的信息来决定哪些信息是重要的,哪些可以暂时忽略。这种压缩机制是TransformerFAM能够有效处理长序列的关键,因为它允许模型在有限的资源下存储和传递最重要的信息。
更新FAM阶段: 在FAM查询完成后,模型会更新FAM,以便将其递归地传递到下一个块。这个更新的FAM包含了当前块经过压缩的信息,以及之前块的全局上下文信息。这样,当模型处理下一个块时,它就能够利用这个更新的FAM来构建更加全面和深入的信息表示。
TransformerFAM的具体实现是通过一系列算法步骤来完成的。这些步骤详细描述了如何迭代地计算自注意力,并将这些计算结果串联起来形成对整个序列的理解。算法考虑了块索引、记忆段和FAM的更新,确保了模型在处理序列时能够考虑到所有相关的上下文信息。
这个算法的实现确保了TransformerFAM在处理长序列时的效率和有效性。通过这种方式,模型不仅能够处理当前的信息,还能够记住和利用之前的信息,从而实现对整个序列的深入理解和处理。这种能力对于处理复杂的语言任务,如长文本的阅读理解、摘要生成等,是非常关键的。

TransformerFAM在推理阶段展现出的计算复杂度是线性的,即O(L),这里的L代表处理的token长度。这种线性复杂度意味着,无论输入序列多长,所需的计算量都将以序列长度的线性速率增长,这与传统的Transformer模型相比是一个显著的改进,后者的计算复杂度是二次方的。TransformerFAM的内存复杂度保持为常数O(1),这表示无论处理多少token,所需的内存量都不会增加,这对于处理长序列数据尤为重要。
这种设计使得TransformerFAM能够在保持较低资源消耗的同时,无限期地维护过去信息,从而为处理无限长的输入序列提供了一个有效的解决方案。这对于需要处理大量数据的应用场景,如自然语言处理中的长文本分析,是一个巨大的优势。
TransformerFAM的一个显著优势是它不需要引入新的权重,可以无缝地重用现有的预训练Transformer模型的检查点。这种兼容性大大降低了模型部署和微调的复杂性。通过对TransformerFAM进行LoRA(Low-Rank Adaptation)微调,即使是在50k步的训练之后,也能显著提升不同规模的Flan-PaLM大型语言模型(LLMs)在长上下文任务上的性能。
与现有的Transformer模型相比,TransformerFAM通过模仿生物神经系统中的工作记忆机制,提供了一种全新的视角来处理长序列数据。这种机制不仅能够提高模型的记忆能力,还能够增强其在复杂任务中的推理和理解能力。
实验
实验开始于对TransformerFAM的训练阶段。研究者们采用了不同规模的Flan-PaLM大型语言模型(LLMs),包括1B、8B和24B参数的模型,以验证TransformerFAM在不同模型大小下的表现。这些模型在预训练阶段后,通过指令微调(instruction finetuning)进一步训练,以适应特定的任务。
在微调过程中,研究者们使用了Flan指令数据,这些数据包含了少量的指令和相应的输出,被打包成长度为8.5k tokens的序列。为了维持所有模型的 minibatch 大小为128,研究者们根据模型的大小分配了不同数量的TPUv5核心。
研究者们采用了LoRA(Low-Rank Adaptation)技术来微调TransformerFAM,这是一种高效的微调方法,它通过在原始模型的注意力和前馈网络层中引入低秩矩阵来调整模型参数,而不是训练所有的权重。这种方法有助于减少灾难性遗忘(catastrophic forgetting),即模型在新任务上训练时不会遗忘旧任务的知识。
实验中使用了多种长上下文任务来评估TransformerFAM的性能,包括NarrativeQA、ScrollsQasper、Scrolls-Quality、XLSum等。这些任务要求模型在回答问题之前必须理解长达数千到数百万的上下文信息,是测试模型长序列处理能力的理想选择。
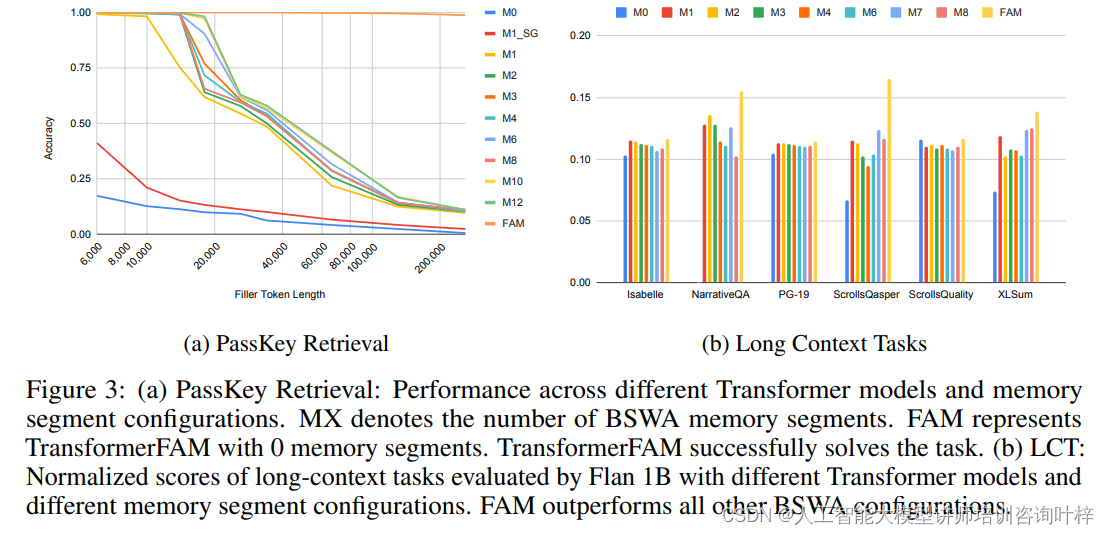
Figure 3 展示了TransformerFAM在两个不同任务上的性能表现:PassKey Retrieval任务和长上下文任务(Long Context Tasks, LCT)。这个图表位于论文的实验部分,具体来说是在介绍TransformerFAM在不同配置下的性能比较和效果评估的小节中。
(a) PassKey Retrieval 任务
这一部分的图表显示了不同Transformer模型和BSWA记忆段配置下的性能。这里,MX 表示BSWA中记忆段的数量,而FAM 表示TransformerFAM且没有使用记忆段(即0记忆段)。实验结果显示,TransformerFAM能够成功解决PassKey Retrieval任务,这表明即使在面对极长上下文的情况下,它也能够有效地检索和记忆重要的信息(如PassKey)。
(b) 长上下文任务 (LCT)
第二部分的图表展示了在Flan 1B模型上,不同Transformer模型和不同BSWA记忆段配置下,长上下文任务的标准化得分。这些任务要求模型处理和理解大量的上下文信息以回答问题或完成任务。结果显示,TransformerFAM在所有长上下文任务上的性能都超过了其他所有BSWA配置,这进一步证明了TransformerFAM在处理长序列数据时的有效性。
这些结果不仅证明了TransformerFAM架构设计的成功,也突显了其在实际应用中的潜力,尤其是在需要处理和记忆大量信息的任务中。通过这些实验,研究者们能够展示TransformerFAM如何通过其独特的反馈注意力机制来提高模型的性能。
实验结果显示,TransformerFAM在所有长上下文任务上均优于传统的Transformer模型。特别是在处理极长序列时,如PassKey Retrieval任务,TransformerFAM能够完美地解决问题,即使在面对超过260k个token的填充上下文时也表现出色。这证明了TransformerFAM在处理长序列数据时的有效性和优越性。
TransformerFAM的性能提升不仅体现在长上下文任务上,在GPT-3任务中也有小幅提升。这可能是因为TransformerFAM通过FAM有效地减少了输入激活中的冗余,优化了潜在空间的使用。
实验还评估了TransformerFAM在不同模型大小下的扩展性和泛化能力。结果表明,随着模型规模的增加,TransformerFAM的性能得到了提升,这表明自注意力机制能够在处理局部信息的同时,有效地将上下文信息传递给FAM。
尽管实验结果令人鼓舞,但研究者们也指出,TransformerFAM的性能提升还有待进一步提高。这表明在工作记忆机制的进一步开发和完善方面,仍有大量的工作要做。未来的研究可能会集中在如何更有效地压缩和传递信息,以及如何将工作记忆与长期记忆更好地结合起来。
TransformerFAM的提出,不仅是对Transformer架构的一次重要补充,更是深度学习领域在模拟人类工作记忆功能方面的一次重要尝试。随着这一技术的不断发展和完善,我们有理由相信,它将在教育、医疗、通信等多个领域发挥重要作用,为构建更加智能和个性化的AI助手提供强有力的支持。
论文链接:https://arxiv.org/abs/2404.09173
这篇关于TransformerFAM:革新深度学习的新型注意力机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




