斯坦福专题

斯坦福UE4 C++课学习补充25:寻路EQS
文章目录 一、创建EQS二、修改行为树三、查询上下文 一、创建EQS 场景查询系统EQS:可用于收集场景相关的数据。然后该系统可以使用生成器,通过各种用户定义的测试就这些数据提问,返回符合所提问题类型的最佳项目Item。 EQS的一些使用范例包括:找到最近的回复剂或弹药、判断出威胁最大的敌人,或者找到能看到玩家的视线 参考链接:https://dev.epicgames.c
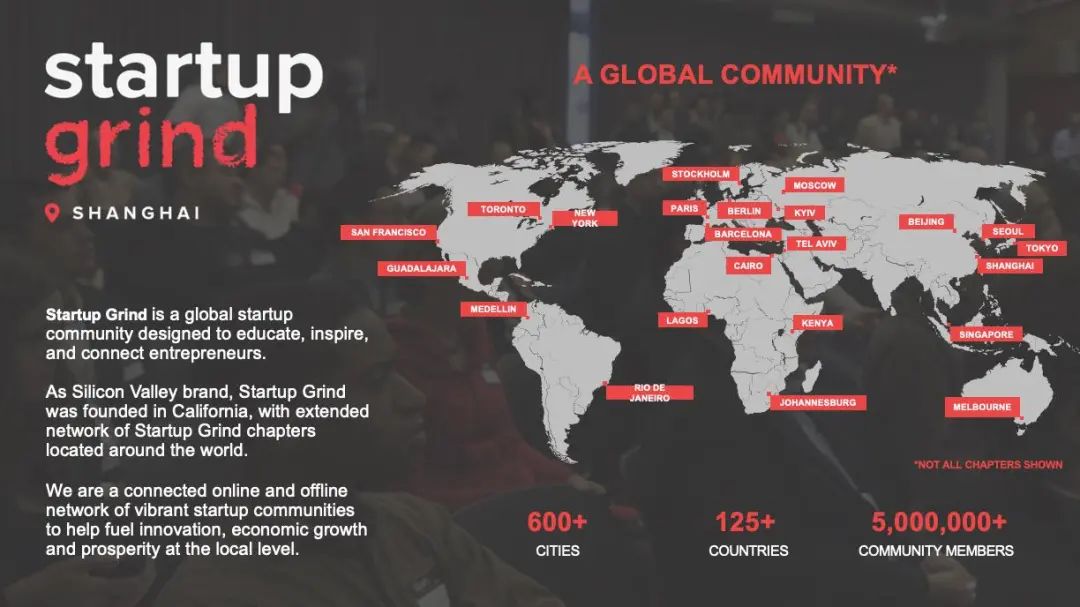
ARR 竟然超过 150 万美元!斯坦福都在使用的 AI 学术搜索引擎 Consensus获 USV 领投的 1100 万美元。
惊爆!就在当下,AI 学术搜索引擎 Consensus 传来令人震撼的消息,其已成功完成 1100 万美元融资。此轮 A 轮融资由 Union Square Ventures 领衔主导,其他参与的投资者有 Nat Friedman、Daniel Gross 以及 Draper Associates 等等。 Consensus 当下竟有着高达 40 万的月活跃用户,其中涵盖了学生、医生以及

【Linux详解】冯诺依曼架构 | 操作系统设计 | 斯坦福经典项目Pintos
目录 一. 冯诺依曼体系结构 (Von Neumann Architecture) 注意事项 存储器的意义:缓冲 数据流动示例 二. 操作系统 (Operating System) 操作系统的概念 操作系统的定位与目的 操作系统的管理 系统调用和库函数 操作系统的管理: sum 三. 系统调用实现示例:Pintos 项目 Step 1:进入 examples 目录 St

coursera-斯坦福-机器学习-吴恩达-第11周笔记-ORC系统
coursera-斯坦福-机器学习-吴恩达-第11周笔记-ORC系统 coursera-斯坦福-机器学习-吴恩达-第11周笔记-ORC系统 1图像ORC 1问题描述2 滑动窗sliding windows3获取大量的图片4分析 2复习 quiz 1图像ORC 1.1问题描述 在这一段介绍一种 机器学习的应用实例 照片OCR技术。 我想介绍这部分内容的原因 主要有以下三个

coursera-斯坦福-机器学习-吴恩达-第10周笔记-使用大数据训练
coursera-斯坦福-机器学习-吴恩达-第10周笔记-使用大数据训练 coursera-斯坦福-机器学习-吴恩达-第10周笔记-使用大数据训练 大数据下的梯度下降 1 大数据2 随机梯度下降3 mini-batch梯度下降4 随机梯度下降的收敛性 大数据的高级技巧 1在线学习2 mapreduce 3quiz 1 大数据下的梯度下降 在接下来的几个视频里 ,我们会讲大
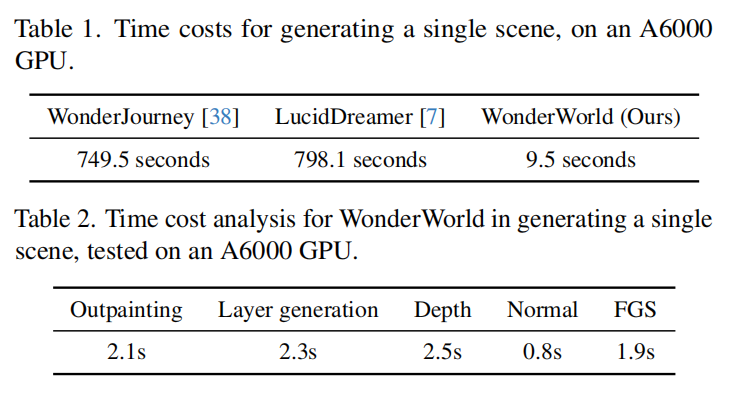
单图创造虚拟世界只需10秒!斯坦福MIT联合发布WonderWorld:高质量交互生成
文章链接:https://arxiv.org/pdf/2406.09394 项目地址: https://WonderWorld-2024.github.io/ 本文介绍了一种新颖的框架—— WonderWorld,它可以进行交互式三维场景外推,使用户能够基于单张输入图像和用户指定的文本探索和塑造虚拟环境。尽管现有方法在场景生成的视觉质量上有了显著改进,但这些方法通常是离线运行的,生成一个
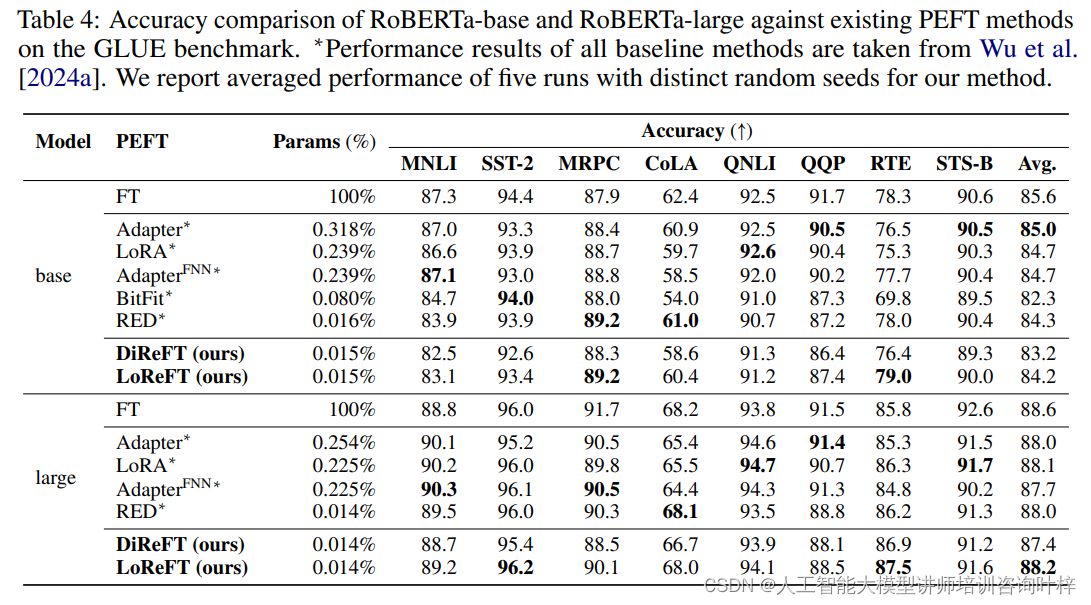
ReF:斯坦福提出的新型语言模型微调方法
随着预训练语言模型(LMs)在各种自然语言处理(NLP)任务中的广泛应用,模型微调成为了一个重要的研究方向。传统的全参数微调方法虽然有效,但计算成本高昂,尤其是在大型模型上。为了解决这一问题,来自斯坦福大学和 Pr(Ai)⊃2;R Group 的研究团队推出一种全新的微调方法——表征微调(ReFT)。ReFT方法的核心优势在于,它不直接对模型权重进行更新,而是通过学习对隐藏层表征的特定干预来适应下

斯坦福CS229机器学习中文速查笔记.pdf
斯坦福CS229是一门经典的机器学习课程,算是机器学习领域的明星课,相信不少人在B站上看过这门课的视频。 这门课主要介绍了机器学习和统计模式识别。内容包括:监督学习(生成/鉴别学习,参数/非参数学习,神经网络,支持向量机);无监督学习(聚类,降维,核方法);学习理论(偏见/方差权衡,VC理论);强化学习和自适应控制。还有对机器学习最新应用的讨论,例如机器人控制,数据挖掘,自主导航,生物信息学,
HumanPlus——斯坦福ALOHA团队开源的人形机器人:融合影子学习技术、RL、模仿学习
前言 今天只是一个平常的日子,不过看到了两篇文章 一篇是《半年冒出近百家新公司,「具身智能」也有春天》 我看完之后转发到朋友圈,并评论道:让机器人翻一万个后空翻,不如让机器人打好一个螺钉,毕竟在目前阶段 炫酷没有意义,所以我们近期全力为工厂去赋能,解决一个个工业场景 期待我司与更多工厂合作,从前期的验证、评估开始另外一篇文章便是之前斯坦福Moblie aloha团队竟然开源推出了他们的人形机器

斯坦福SR810和SR830 DSP锁定放大器
SR810 和 SR830 DSP 锁定放大器 SR810 锁定放大器和 SR830锁定放大器以合理的成本提供高性能。SR830 同时显示信号的幅度和相位,而 SR810 仅显示幅度。两种仪器都使用数字信号处理 (DSP) 来代替传统锁定中的解调器、输出滤波器和放大器。SR810 和 SR830 具有 1 mHz 至 102 kHz 的工作范围和 100 dB 的无漂移动态储备,提供无与伦比的性
![[文献解读]:斯坦福最新研究-HumanPlus:人形机器人跟踪和模仿人类](https://img-blog.csdnimg.cn/direct/093a22624d4f4a8696121cc793ed8987.jpeg#pic_center)
[文献解读]:斯坦福最新研究-HumanPlus:人形机器人跟踪和模仿人类
摘要 制造具有与人类相似外形的机器人的关键论点之一是,我们可以利用大量人类数据进行训练。然而,由于人形机器人感知和控制的复杂性、人形机器人与人类在形态和驱动方面仍然存在的物理差距,以及人形机器人缺乏从自我中心视觉学习自主技能的数据管道,因此在实践中这样做仍然具有挑战性。 在本文中,我们介绍了一个全栈系统,供人形机器人从人类数据中学习运动和自主技能。我们首先使用现有的40小时人体运动数据集通过
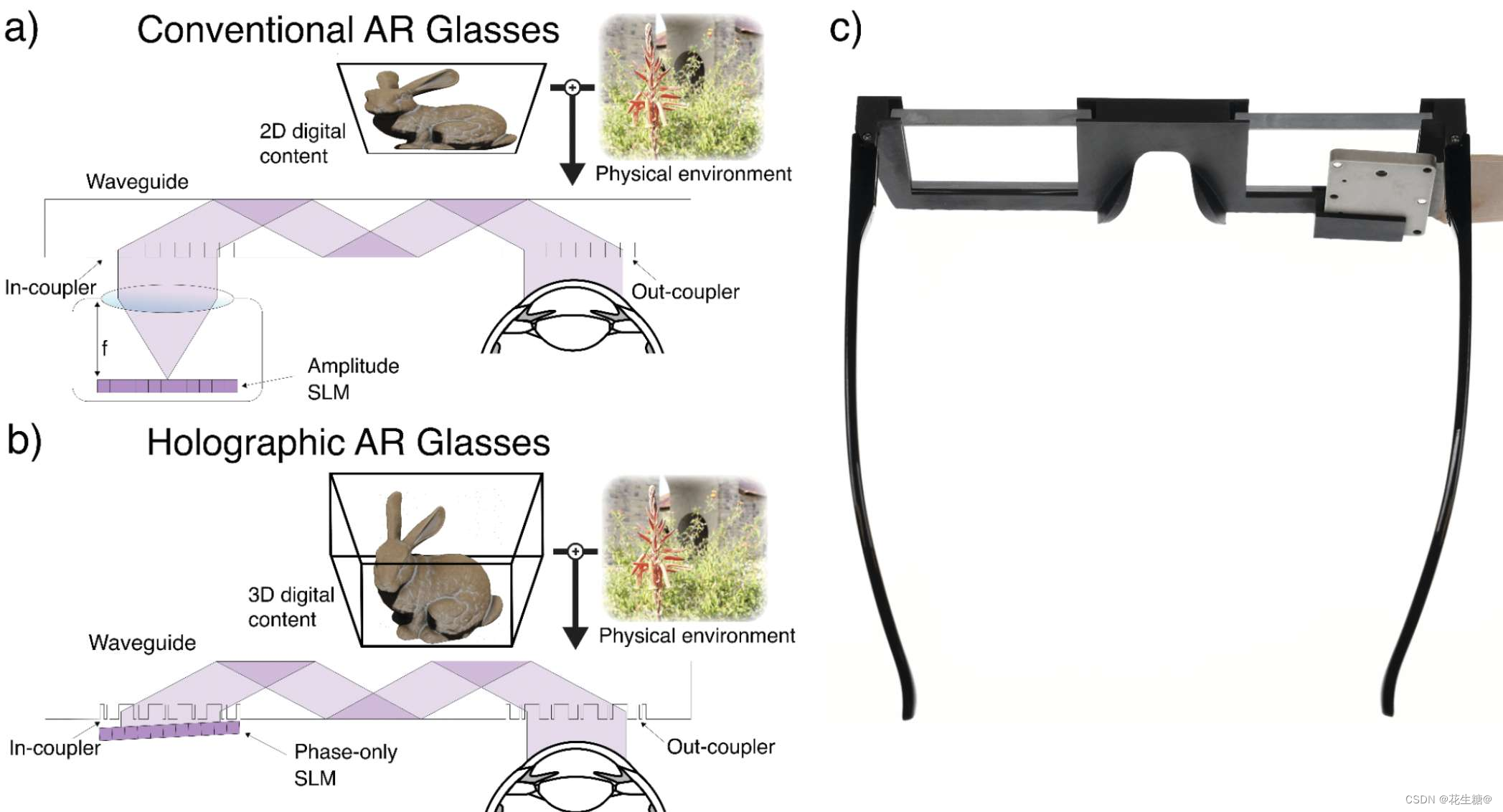
英伟达与斯坦福携手,打造未来全息XR眼镜:头带时代的终结
在XR(扩展现实)技术的演进过程中,一个显著的挑战在于如何平衡设备的便携性与视觉体验。传统的XR设备由于需要厚重的头带固定光学器件和显示器,不仅增加了体积,还为用户带来了社交上的不便。然而,随着英伟达与斯坦福大学戈登·韦茨斯坦教授领导的研究团队的合作,这一难题似乎找到了解决之道——全息XR眼镜的诞生预示着头带时代的终结。 全息XR眼镜的核心在于其独特的光学设计,它遵循一条重要规则:显示器应尽可能

斯坦福的新工具,生物计算,操作系统与AI融合之路
一支烟花官网: https://agifun.love 智源社区 斯坦福让“GPU高速运转”的新工具火了,比FlashAttention2更快 西风 发自 凹非寺量子位 | 公众号 QbitAIAI算力资源越发紧张的当下,斯坦福新研究将GPU运行效率再提升一波——内核只有100行代码,让H100比使用FlashAttention-2,性能还要提升30%。怎么做到的?研究人员从

斯坦福CS229(吴恩达授)学习笔记(5)
CS229-notes3 说明正文Problem Set #2: Kernels, SVMs, and Theory1. Kernel ridge regression2. ℓ 2 \ell _2 ℓ2 norm soft margin SVMs3. SVM with Gaussian kernel4. Naive Bayes and SVMs for Spam Classificati
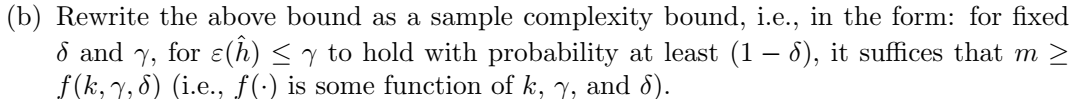
斯坦福CS229(吴恩达授)学习笔记(6)
CS229-notes4 说明正文Problem Set #2: Kernels, SVMs, and Theory5. Uniform convergence 说明 此笔记 是cs229-notes4讲义中的学习内容,与B站上的“09 经验风险最小化”视频对应,主要是该部分对应的习题解答。 课程相关视频、讲义等资料可参照《斯坦福CS229(吴恩达授)学习笔记(1)》 获取。

斯坦福CS229(吴恩达授)学习笔记(3)
CS229-notes1-part3 说明正文Problem Set #1: Supervised learning1. Newton's method for computing least squares5. Exponential family and the geometric distribution 说明 此笔记 是cs229-notes1讲义中的第二部分学习内容

斯坦福天才少女创5亿独角兽!Pika获8000万融资,金牌团队首曝光
斯坦福天才少女创立的公司Pika,继续书写传奇。 GPT-4o深夜发布!Plus免费可用!https://www.zhihu.com/pin/1773645611381747712 没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几分钟搞定:升级ChatGPT-4o Turbo步骤https://www.zhihu.com/pin/1768399982598909952

斯坦福 AI 团队被指抄袭清华大模型:细节揭秘
近日,斯坦福AI团队因发布的AI模型被指抄袭清华大学的研究成果而陷入争议。本文将详细探讨这一事件的背景、关键细节及其对开源社区的影响。 事件背景 斯坦福的AI团队发布了一个名为“LLaMA-3V”的模型,声称只花了500美元且只用了GPT-4的1%的体量便达到了同等的图片识别能力。然而,很快有消息指出,这个模型涉嫌抄袭清华大学的“Mini-CPM-LLaMA-3V2.5”模型。尽管斯坦福团队最

斯坦福AI团队抄袭事件,清华回应:也算国际认可
近日,斯坦福大学人工智能(AI)团队的一项备受瞩目的研究——Llama3-V大模型,陷入了抄袭风波。该团队原本以其创新的模型和低廉的训练成本为亮点,声称能够在低成本下训练出性能卓越的SOTA多模态大模型。然而,随着抄袭指控的浮出水面,这一切都显得那么苍白无力。 抄袭的对象不是别人,正是来自中国清华系的明星创业公司面壁智能所开发的MiniCPM-Llama3-V 2.5模型。有细心的网友发现,
DexCap——斯坦福李飞飞团队泡茶机器人:更好数据收集系统的原理解析、源码剖析
前言 2023年7月,我司组建大模型项目开发团队,从一开始的论文审稿,演变成目前的两大产品线 论文方面,除了论文审稿之外,目前正在逐一开发论文翻译、论文对话、论文idea提炼、论文修订/润色/语法纠错、论文检索机器人方面,我们1月份开始攻机器人、Q1组建队伍、5月份成功复现UMI和DexCap后,本月(即6月)总算要开始为工厂赋能了(目前已经谈好三个工厂的合作意向) 总之,经过过去近一年的努
【斯坦福因果推断课程全集】1_随机对照试验1
目录 The average treatment effect Difference-in-means estimation IID Sampling and Population Asymptotics Example: The linear model Regression adjustments with a linear model 随机对照试验(RCT)是统计因果推论

斯坦福报告解读3:图解有趣的评估基准(上)
《人工智能指数报告》由斯坦福大学、AI指数指导委员会及业内众多大佬Raymond Perrault、Erik Brynjolfsson 、James Manyika等人员和组织合著,旨在追踪、整理、提炼并可视化与人工智能(AI)相关各类数据,该报告已被大多数媒体及机构公认为最权威、最具信誉人工智能数据与洞察来源之一。 2024年版《人工智能指数报告》是迄今为止最为详尽的一份报告,包含了

斯坦福2024人工智能指数报告 1
《人工智能指数报告》由斯坦福大学、AI指数指导委员会及业内众多大佬Raymond Perrault、Erik Brynjolfsson 、James Manyika、Jack Clark等人员和组织合著,旨在追踪、整理、提炼并可视化与人工智能(AI)相关各类数据,该报告已被大多数媒体及机构公认为最权威、最具信誉的人工智能数据与洞察来源之一。 2024年版《人工智能指数报告》是迄今为止最为详尽

Stanford斯坦福 CS 224R: 深度强化学习 (3)
基于模型的强化学习 强化学习(RL)旨在让智能体通过与环境互动来学习最优策略,从而最大化累积奖励。传统的强化学习方法如Q-learning、策略梯度等,通过大量的试错来学习值函数或策略,样本效率较低。而基于模型的强化学习(MBRL)则利用对环境的预测模型来加速学习过程,大大提高了样本利用率。本章我们将系统地介绍MBRL的基本原理、核心算法、实现技巧以及代表性应用。 1. 采样优化入门 在探讨
Stanford斯坦福 CS 224R: 深度强化学习 (5)
离线强化学习:第一部分 强化学习(RL)旨在让智能体通过与环境交互来学习最优策略,从而最大化累积奖励。传统的RL训练都是在线(online)进行的,即智能体在训练过程中不断与环境交互,实时生成新的状态-动作数据,并基于新数据来更新策略。这种在线学习虽然简单直观,但也存在一些局限性: 在线交互的样本效率较低,许多采集到的数据未被充分利用对于一些高风险场景(如自动驾驶),在线探索可能会带来安全隐患

智能体之斯坦福AI小镇(Generative Agents: Interactive Simulacra of Human Behavior)
相关代码地址见文末 论文地址:Generative Agents: Interactive Simulacra of Human Behavior | Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology 1.概述 论文提出了一种多个智能体进行协同,进而模拟