本文主要是介绍单图创造虚拟世界只需10秒!斯坦福MIT联合发布WonderWorld:高质量交互生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章链接:https://arxiv.org/pdf/2406.09394
项目地址: https://WonderWorld-2024.github.io/

本文介绍了一种新颖的框架—— WonderWorld,它可以进行交互式三维场景外推,使用户能够基于单张输入图像和用户指定的文本探索和塑造虚拟环境。尽管现有方法在场景生成的视觉质量上有了显著改进,但这些方法通常是离线运行的,生成一个场景需要几十分钟到几个小时。通过利用快速高斯曲面(Fast Gaussian Surfels)和基于引导扩散的深度估计方法,WonderWorld 在显著减少计算时间的同时,生成了几何一致的外推场景。本文的框架在单个 A6000 GPU 上生成连接且多样的三维场景用时不到10秒,实现了实时用户交互和探索。展示了 WonderWorld 在虚拟现实、游戏和创意设计中的潜力,用户可以从单张图像快速生成和导航身临其境的、可能无限的虚拟世界。本文的方法代表了交互式三维场景生成的重大进展,为用户驱动的内容创建和虚拟环境中的探索开辟了新的可能性。
介绍
在过去的一年中,3D场景生成变得非常热门,许多研究成功地探索了强大的生成图像先验和单目深度估计的改进。这些工作大大提高了生成场景的视觉质量、可能的视角和多样性。然而,所有这些工作都是离线完成的,用户提供单个起始图像或文本提示后,系统在几十分钟到几小时后返回一个固定的3D场景或特定摄像路径的视频。虽然离线生成可能适用于小型、离散的场景或视频,但这种设置对于许多场景生成的使用场景来说是有问题的。例如,在游戏开发中,世界设计师希望逐步构建3D世界,能够控制生成过程,并能够低延迟地查看中间步骤。在虚拟现实和视频游戏中,用户期望可扩展、多样化的内容,这些内容比当前生成的场景更大、更丰富。在未来,用户可能会希望更多:一个系统允许他们自由探索和塑造动态演变的、无限的虚拟世界。所有这些都促使了交互式3D场景生成的问题,在这种情况下,用户可以低延迟地控制场景外推的内容(例如,通过文本提示),并且可以控制场景外推的位置(例如,通过相机控制)。
为了理解阻碍交互性的技术问题,本文检查了几种最先进的3D场景生成方法,并确定了两个主要限制。首先,场景生成速度太慢,无法实现交互性。每个生成的场景需要几十分钟进行多次生成图像修补和深度估计。其次,生成的场景在场景边界处存在强烈的几何失真,阻碍了从生成场景进行外推。
本文提出了一个名为WonderWorld的框架,用于交互式场景生成。输入是一张单一的图像,输出是一组相互连接但多样化的3D场景。为了解决速度问题,本文的核心技术涉及快速高斯表面(Fast Gaussian Surfels),其优化由于采用了原理性、基于几何的初始化而需要不到1秒的时间,以及分层场景生成,其中每个场景都解析可能发生遮挡的区域,然后预先生成内容以填充这些特殊区域。为了解决几何失真问题,本文引入了一种引导扩散的深度估计方法,确保外推场景和现有场景之间的几何对齐。
使用本文的框架,外推或生成一个场景在单个A6000 GPU上花费不到10秒的时间。这一突破解锁了交互式场景生成的潜力,使用户能够将单一图像外推成一个广阔而身临其境的虚拟世界。本文的方法为虚拟现实、游戏和创意设计中的应用开启了新的可能性,用户可以快速生成和探索多样化的3D场景。
实现
本文的目标是生成一组多样但连贯连接的3D场景,形成一个潜在的无限虚拟世界。为此提出了WonderWorld,这是一个允许快速场景外推和实时渲染的框架,并提供了交互式视觉体验。
概览
下图2展示了本文的WonderWorld框架的示意图。其主要思想是从输入图像生成3D场景,并通过外推现有场景逐步扩展。用户可以提供文本来指定要生成的场景内容,也可以将其留给大型语言模型(LLM)处理。
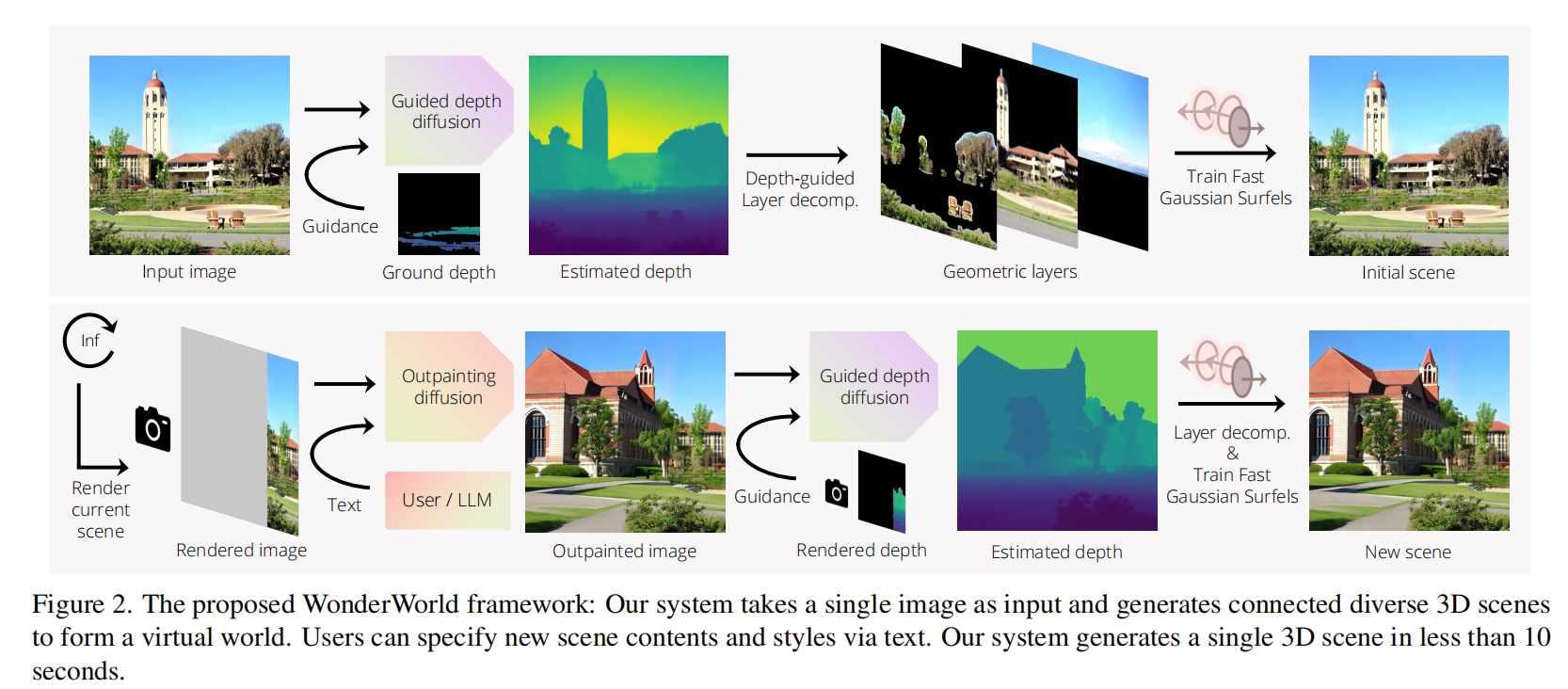
主要的技术挑战包括场景生成速度和外推场景中的几何失真问题。为了加快场景生成速度,本文采用了传统的surfels思想,将其扩展为3DGS,并展示这种扩展允许基于几何的原则初始化,显著降低了优化时间至小于1秒。针对生成场景中的透视洞(disocclusion holes),本文引入了逐层场景生成策略,不再依赖多视角图像生成。因此,WonderWorld能够在单个GPU上实现快速场景生成(不超过10秒)和实时渲染。为了解决几何失真问题,本文提出利用引导式深度扩散来生成新场景的几何形状。引导式深度扩散具有鲁棒性和灵活性,可以指定各种几何约束。
快速高斯面
本文引入快速高斯面(Fast Gaussian Surfels,FGS)来表示生成的3D场景。FGS可以看作是3D高斯面(3D Gaussian Surfels,3DGS其中每个)的轻量化版本,高斯核的z轴被缩减为零。具体来说,FGS由一组高斯面元组成,每个高斯面元由一组参数 { p , q , s , o , c } \{p, q, s, o, c\} {p,q,s,o,c} 表示,其中 p p p 表示高斯核的3D空间位置, q q q 表示方向四元数, s = [ s x , s y ] s = [s_x, s_y] s=[sx,sy] 表示 x 轴和 y 轴的比例尺, o o o 表示不透明度, c c c 表示RGB颜色。我们假设生成的场景中存在兰伯特表面,因此三维颜色 c c c 是视角无关的。
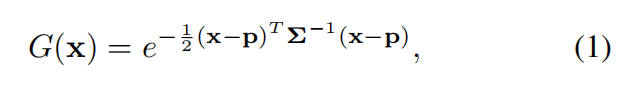
其中协方差矩阵 Σ \Sigma Σ 是由比例尺和可以从四元数 q q q 获得的旋转矩阵 Q Q Q 构建的。协方差矩阵如下:
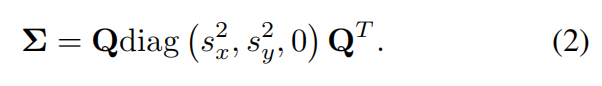
渲染化和阿尔法混合渲染过程与 3D 高斯分割(3DGS) 相同。
基于几何的初始化 本文的快速优化核心思想是,因为从单视图图像生成快速高斯表面,因此可以假设图像中的每个像素揭示了底层 3D 场景中的一个表面。因此,可以利用对应像素的信息来直接求解或近似表面的参数,而不是随机初始化和优化。这样,优化过程得以简化、加速并适当正则化。
具体来说,给定一个 H × W H × W H×W 像素的输入图像 I I I,目标是生成 H × W H × W H×W 个表面来表示底层 3D 场景。表面的颜色 c c c 初始化为像素的 RGB 值。表面的位置 p p p 可以通过反投影估计:
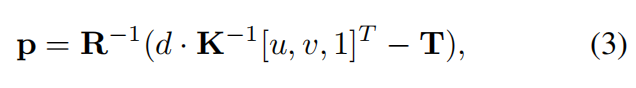
其中, u u u 和 v v v 表示像素坐标, K K K、 R R R 和 T T T 分别表示当前相机的内参矩阵、旋转矩阵和平移向量。 d d d 表示该像素的估计深度。本文将在后面章节中详细讨论深度估计。
为了初始化 surfel 的方向,注意到旋转矩阵 Q = [ Q x , Q y , Q z ] \mathbf{Q} = [Q_x, Q_y, Q_z] Q=[Qx,Qy,Qz] 的第三列 Q z Q_z Qz 是 surfel 的法线方向。因此,可以构建旋转矩阵 Q:
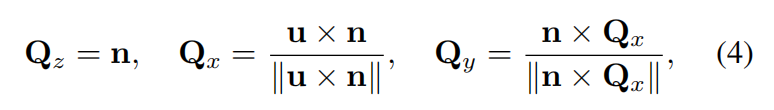
其中, u = [ 0 , 1 , 0 ] T \mathbf{u} = [0, 1, 0]^T u=[0,1,0]T 表示一个单位上向量, n = R − 1 n c n = R^{-1}n_c n=R−1nc 表示在世界坐标系中估计的像素法线,而 n c n_c nc 表示从图像 I I I 中估计得相机坐标系法线。
当涉及到比例 s s s 时,需要找到一个合适的初始化方式,以防止混叠。例如,它不应该在移动到场景更近处时导致孔洞。为了实现这一点,本文考虑一个面的奈奎斯特间隔。设图像的采样间隔(即像素大小)为 1。对于距离为 d d d 的面,其奈奎斯特间隔 T N T_N TN 为 T N = 2 d f T_N = \frac{2d}{f} TN=f2d,其中 f f f 表示焦距。我们希望将面的比例设置为与 T N T_N TN成比例,以便大约覆盖间隔 T N T_N TN来最小化混叠。直观上,这意味着面能够无缝覆盖可见表面而没有显著的重叠。本文在图 3(a) 中展示了表面平行于图像平面的情况。如下图 3(b) 所示,如果表面不平行于图像平面,需要在比例中添加一个余弦项。因此,初始化比例为:
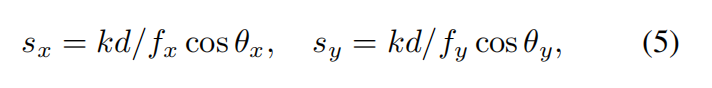
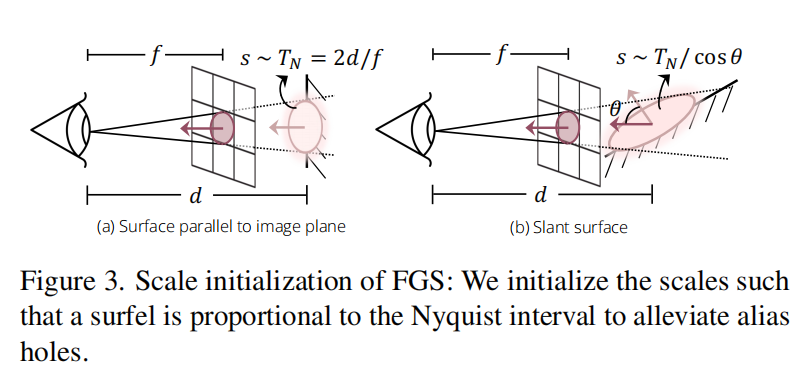
其中, k = 1 2 k = \frac{1}{\sqrt{2}} k=21 表示一个超参数, cos θ x \cos \theta_x cosθx 表示图像平面法线和投影到 XoZ 平面的面法线之间的余弦值。在优化后,本文在下图 4 中展示了使用本文的 FGS 比例初始化与 Mip-Splatting 抗混叠 3D 高斯初始化的对比。可以观察到,本文的比例初始化在进入生成场景时缓解了混叠孔洞的问题。

优化
本文使用与3DGS相同的光度损失函数: L = 0.8 L 1 + 0.2 L D − S S I M L = 0.8L_1 + 0.2L_{D-SSIM} L=0.8L1+0.2LD−SSIM。优化不透明度、方向和比例,但不优化颜色和空间位置。本文的优化包括100次迭代,并且没有密集化过程。在实践中,本文在z轴上添加一个小数值,而不是零,以允许更高的表示能力,同时利用本文的原则性初始化。
分层场景生成
为了填补生成场景中的遮挡空洞,本文引入了一种分层场景生成策略。其主要思想是解析场景的几何层结构,发现可能出现显著遮挡的区域,通过去除遮挡内容来显露这些区域,并生成内容以填补这些区域。本文称这一过程为深度引导的层分解。上图2顶部展示了一个示例。
特别地,本文将图像从前到后分解为三层:前景层 F F F、背景层 B B B 和天空层 Y Y Y。由于遮挡发生在深度边缘,本文通过找到深度边缘来分离这些层。并通过对估计深度图的空间梯度幅值进行阈值处理,计算显著深度边缘图。前景层 F F F 通过找到包含显著深度边缘的语义片段形成。本文略微扩展这些片段以确保它们确实与深度边缘相交。图5展示了一个示例。对于天空层,由于天空深度估计对深度估计器来说非常具有挑战性,本文直接使用语义分割。

给定层分割后,本文首先通过扩散模型对天空层进行修复,并使用修复后的天空图像来训练相应的FGS。然后,对背景层进行修复,并在固定的天空FGS之上训练背景FGS。最后,本文在固定的背景FGS和天空FGS之上训练前景FGS。
引导深度扩散
为了生成一个无限的世界,本文需要将现有的场景推广到未探索的空间。一个基本的挑战是在推广过程中的几何扭曲,即新生成的场景内容可能与现有场景内容存在显著的几何差距,因此在从除了外部观点以外的视角看时会显得不连贯。这是由于估计的深度与现有几何之间的不一致造成的。
特别地,设 D v D_v Dv 是从外部观点渲染的现有内容的深度图,大小为 H × W H \times W H×W,使用二进制mask M v ∈ { 0 , 1 } H × W M_v \in \{0, 1\}^{H \times W} Mv∈{0,1}H×W 表示可见区域; D e D_e De 是外推新图像 I e I_e Ie 的估计深度。本文观察到 D v ⊙ M v D_v \odot M_v Dv⊙Mv 和 D e ⊙ M v D_e \odot M_v De⊙Mv 之间存在明显的差异,其中 ⊙ \odot ⊙ 表示逐元素乘积。本文在下图6中展示了一个例子来说明这个问题。

简单的后处理启发式方法,例如通过计算全局平移和缩放来对齐,或者微调深度估计器以匹配估计的深度与现有几何体,都不足以解决问题,因为它们无法减少在估计新场景深度时存在的固有歧义。
为了应对这一挑战,本文采用了深度扩散网络的引导技术。主要思想是将推断场景的深度估计问题形式化为条件深度生成问题,即从深度分布 p ( D e ∣ I e , D v , M v ) p(D_e \mid I_e, D_v, M_v) p(De∣Ie,Dv,Mv) 中采样,其中显式地利用观察到的深度 D v ⊙ M v D_v \odot M_v Dv⊙Mv 作为条件引导信号。本文选择使用扩散模型,因为与前向传播网络不同,它们提供了从深度后验中采样的自然方法。本文的引导深度扩散基于潜变深度扩散模型。简而言之,潜变深度扩散模型通过逐步去噪一个随机初始化的潜变深度图 d T d_T dT,利用学习的去噪器 UNet ϵ θ ( d t , I , t ) \text{UNet}\epsilon_\theta(d_t, I, t) UNetϵθ(dt,I,t),从深度分布 p ( D ∣ I ) p(D \mid I) p(D∣I) 中采样生成深度图,这里的 t 表示时间步长。生成的深度由解码器 D = D e c o d e r ( d ) D = Decoder(d) D=Decoder(d) 给出。在下图7 (a) 中展示了一个示例。
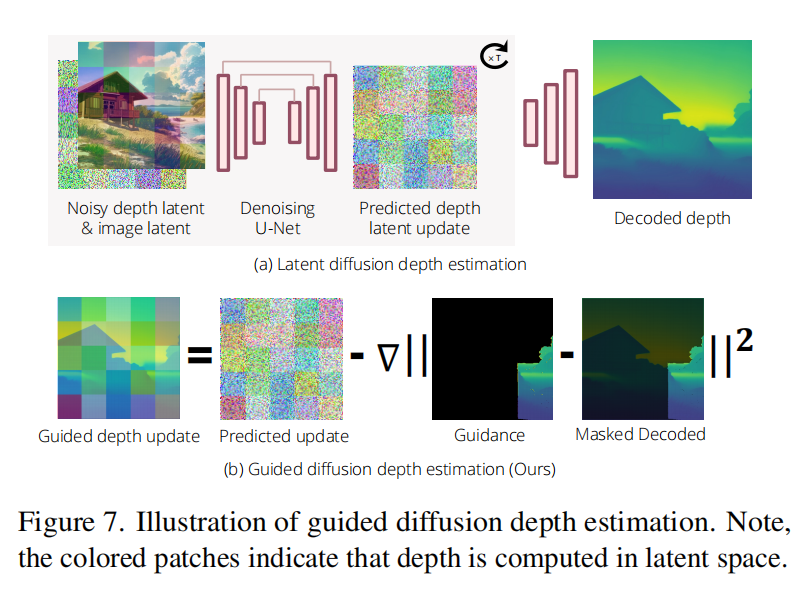
从评分(score-based)的角度来看,去噪器 ϵ θ ( d t , I , t ) \epsilon_\theta(d_t, I, t) ϵθ(dt,I,t) 预测一个更新方向,潜变深度生成过程通过递归地应用这些更新来完成:
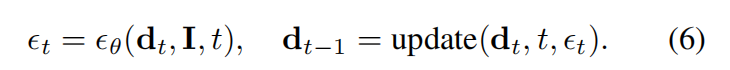
本文通过修改去噪器来注入可见深度作为引导信息,具体做法是
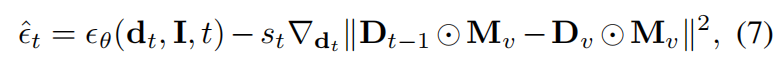
其中, ϵ ^ t \hat{\epsilon}_t ϵ^t 表示引导去噪器, D t − 1 = Decoder ( d t − 1 ) D_{t-1} = \text{Decoder}(d_{t-1}) Dt−1=Decoder(dt−1) 表示预解码的深度图, s t s_t st表示引导权重。
我们的修改可以看作是组合两个评分函数,以从条件分布 p ( D e ∣ I e , D v , M v ) p(D_e \mid I_e, D_v, M_v) p(De∣Ie,Dv,Mv)中进行采样。这个条件分布同时考虑了可见的现有深度 D v D_v Dv 和新场景几何结构 I e I_e Ie,从而实现了更加平滑的几何外推。
解决地面平面失真问题 本文注意到引入的导向深度扩散公式非常灵活,可以允许指定不同的深度约束。例如,另一个重要的几何失真是地面平面通常是弯曲的。因此,对于所有生成的场景,本文通过以下方式添加地面平面的深度指导:在公式中,将mask M v M_v Mv 替换为从语义分割中获得的地面mask M g M_g Mg,并用从分析计算出的平坦地面深度 D g D_g Dg 替换可见内容的深度 D v D_v Dv。
结果
在本节中,本文展示了WonderWorld的结果。由于不知道任何允许交互式场景生成的基准方法,因此本文专注于展示生成大规模3D场景的质量。为此,本文考虑了开源基准方法,并使用它们的官方代码。本文展示了交互式场景生成的示例视频,并强烈建议读者先观看视频。
本文的基准方法包括WonderJourney,这是一种最新的永久视角生成方法,以及LucidDreamer,一种最近的3D场景生成方法。WonderJourney接受单张图像作为输入,并通过绘制图像和反投影像素来生成一系列点云。LucidDreamer接受单张图像作为输入,并从中合成多视角图像来训练3DGS。本文在示例中使用了公开可用的真实和合成图像。
实现细节
在本文的实现中,使用了稳定扩散修复模型作为本文的出画模型。并且还将它用于修复背景和天空层。本文使用 OneFormer 对天空、地面和前景对象进行分割。在初始场景中,本文使用 SyncDiffusion 离线生成整个天空。本文使用 Marigold 法作为深度扩散模型,并估计法线使用 Marigold 法。在本文的引导深度扩散中,设置了引导权重 s t s_t st,使得引导信号的范数与预测更新的范数成比例。本文使用 Euler 调度器进行深度扩散,共进行 30 步,其中在最后 8 步应用本文的引导。本文使用高效的 SAM 对估计的深度进行后处理,类似于 WonderJourney 。本文还遵循 WonderJourney 的做法,当用户未提供文本时,使用 GPT-4 生成提示,并根据场景名称添加可能的对象和背景文本来丰富提示。本文将发布完整的代码和软件以便复现实验。
定性结果
本文在下图10中使用相同的输入图像展示了WonderWorld和基线方法的定性比较结果。请注意,本文的WonderWorld结果包括9个场景,而LucidDreamer方法的结果只有一个场景。WonderJourney方法仅支持在两个连续场景之间提取3D点;本文在此扩展了代码,以支持生成多达4个场景的点。

从上图10中可以看到,像LucidDreamer 这样的单一3D场景生成方法不会超出预定义的场景范围,并且在生成场景边界处存在严重的几何失真。虽然WonderJourney 允许生成多个场景,在特定视角下这些场景看起来是连贯的,但在不同的摄像机角度渲染时,几何失真问题显著。与基线方法相比,本文的WonderWorld显著减轻了几何失真问题,生成了连贯的大规模3D场景。本文在下图8、下图12和下图13中展示了更多示例。



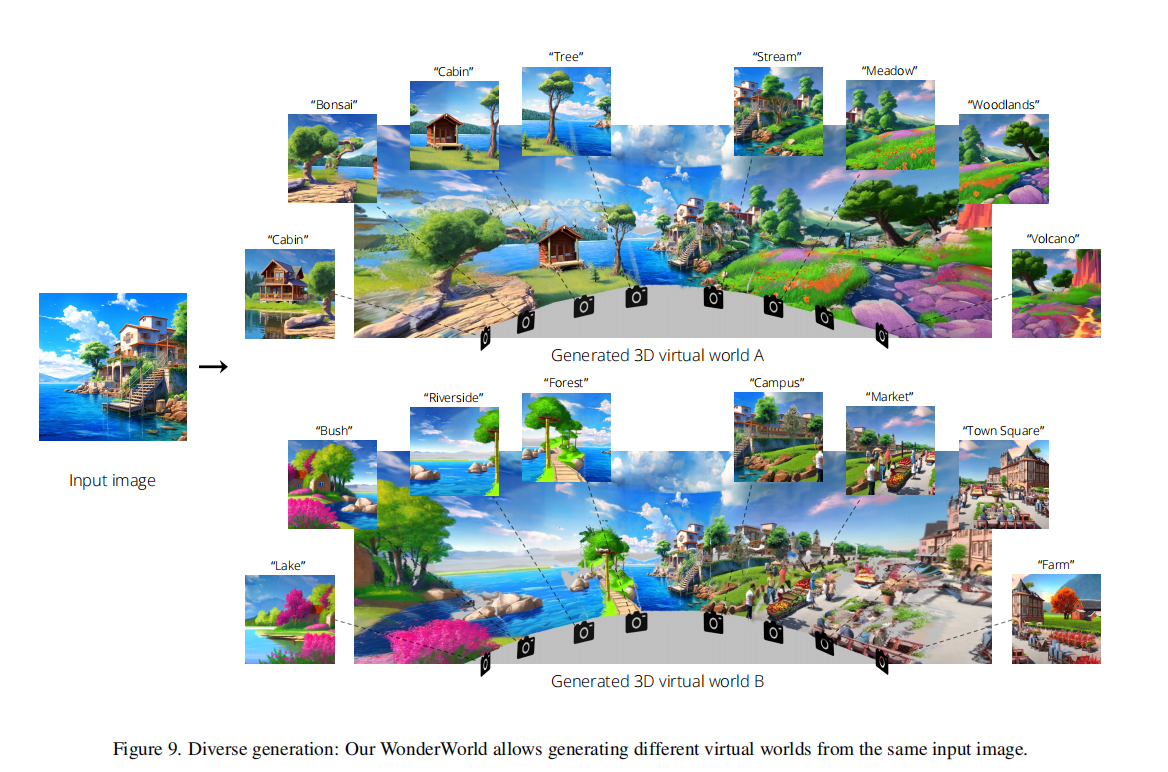
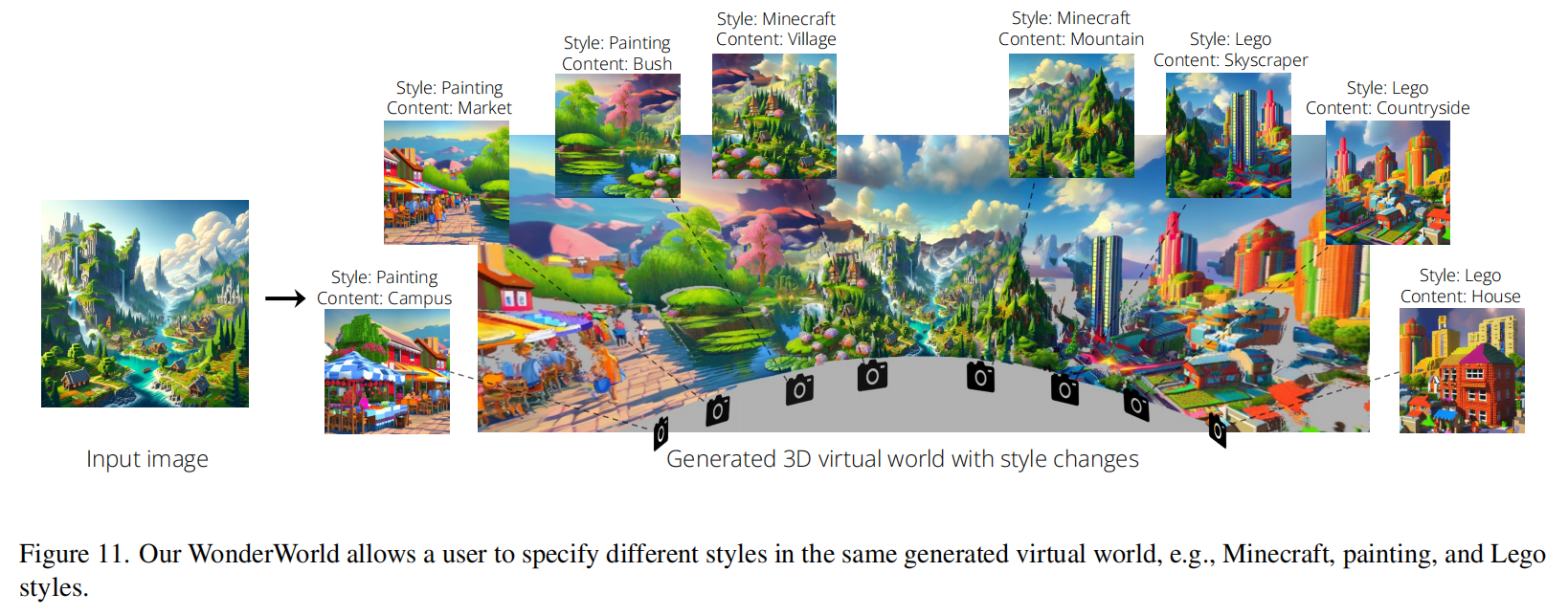
由于WonderWorld允许选择不同的文本提示来改变内容,生成的场景在每次运行时可以是多样化和不同的。本文在下图9中展示了从同一输入图像生成的多样化结果的示例。WonderWorld还允许用户在同一生成的虚拟世界中指定不同的风格,例如Minecraft、绘画和乐高风格,如下图11所示。
生成速度
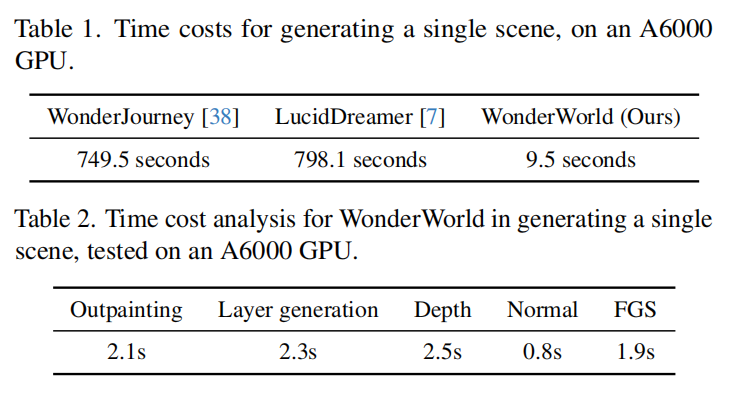
由于本文的重点是使3D场景生成具有互动性,本文报告了从开始生成到可以看到结果的场景生成时间成本。在下表1中显示了单个场景的生成时间。从下表1可以看出,即使是现有最快的方法WonderJourney,生成单个场景也需要超过700秒,大部分时间花在生成多个视图以填补现有场景和新生成场景之间的空隙上。LucidDreamer从输入图像生成稍微扩展的场景,并花费大部分时间生成多个视图,调整这些视图的深度,并训练一个3DGS以适应这些视图。总的来说,以往的方法需要生成或提取多个视图,并花费大量时间优化其3D场景表示。本文通过使用基于几何的初始化原则的FGS加速了表示优化,并通过分层场景生成策略减少了所需的图像数量。共同提升快速场景生成的能力。本文在下表2中展示了时间成本的分析。由于扩散模型推断(外绘、层内绘、深度和法线估计)花费了最多时间,本文的方法将受益于未来在加速扩散推断方面的进展。
结论
本文介绍了WonderWorld,一个用于互动3D场景生成的系统,具有显著加快生成时间和提升大规模多样场景性能的技术改进。WonderWorld允许用户以互动方式生成和探索他们想要的场景部分,并按其需求生成内容。
限制
WonderWorld的一个局限性是场景密度较低,因为每个场景最多只有 H × W H × W H×W 个高斯表面。另一个局限性是处理细节对象(如树木)的困难,这可能导致深度估计不准确,从而在视点改变时出现“空洞”或“浮动物”。本文在视频中展示了一个失败案例。因此,一个令人兴奋的未来方向是利用WonderWorld互动地原型化一个粗略的世界结构,然后通过较慢的单场景多视图扩散模型进行细化,以提高场景密度、填补空洞和去除浮动物。
参考文献
[1] WonderWorld: Interactive 3D Scene Generation from a Single Image
这篇关于单图创造虚拟世界只需10秒!斯坦福MIT联合发布WonderWorld:高质量交互生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







