本文主要是介绍优于InstantID!中山大学提出ConsistentID:可以仅使用单个图像根据文本提示生成不同的个性化ID图像,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
给定一些输入ID的图像,ConsistentID可以仅使用单个图像根据文本提示生成不同的个性化ID图像。效果看起来也是非常不错。


相关链接
Code:https://github.com/JackAILab/ConsistentID
Paper:https://ssugarwh.github.io/consistentid.github.io/arXiv.pdf
Demo:https://huggingface.co/spaces/JackAILab/ConsistentID/
论文阅读

ConsistentID:具有多模式细粒度身份保护的肖像生成
摘要
基于扩散的技术已经取得了重大进展,特别是在个性化和定制的设施生成方面。然而,现有方法在实现高保真和详细身份(ID)一致性方面面临挑战,这主要是由于对面部区域的细粒度控制不足,以及缺乏通过充分考虑错综复杂的面部细节和整体面部来保存ID的全面策略。
为了解决这些限制,我们引入了ConsistentID,这是一种创新的方法,专门用于在细粒度多模式面部提示下生成不同身份的人像,仅使用单个参考图像。ConsistentID由两个关键组件组成:一个多模式面部提示生成器,它将面部特征、相应的面部描述和整体面部上下文结合起来,以提高面部细节的准确性;一个通过面部注意力定位策略优化的ID保留网络,旨在保留面部区域的ID一致性。这些组件通过引入面部区域的细粒度多模态ID信息,显著提高了ID保存的准确性。
为了促进ConsistentID的训练,我们提供了一个细粒度的人像数据集FGID,其中包含超过500,000张面部图像,提供了比现有公共面部数据集更大的多样性和全面性。%如里昂脸、CelebA、FFHQ和SFHQ。实验结果证实,我们的ConsistentID在个性化面部生成方面实现了卓越的精度和多样性,超过了MyStyle数据集上的现有方法。此外,虽然ConsistentID引入了更多的多模态ID信息,但它在生成过程中保持了较快的推理速度。
方法
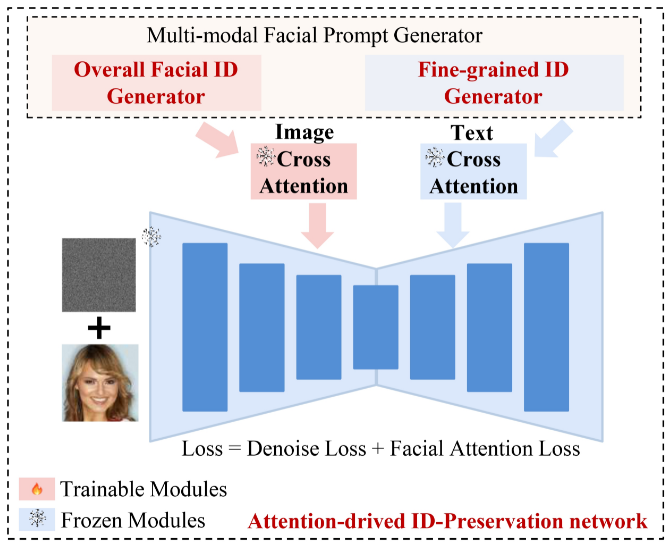
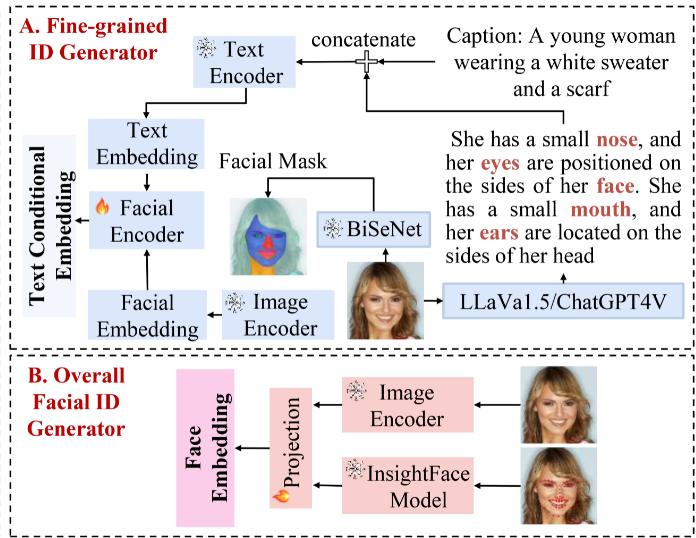
该框架包括两个关键模块:多模式面部身份生成器和有目的地制作的身份保留网络。
-
多模态面部提示生成器由两个基本组件组成:一个细粒度的多模态特征提取器,专注于捕获详细的面部信息;一个面部ID特征提取器,专门用于学习面部ID特征。
-
另一方面,身份保留网络利用面部文本和视觉提示,通过面部注意力定位策略防止来自不同面部区域的身份信息混合。这种方法确保了面部区域中ID一致性的保持。
实验
ConsistentID改变角色年龄属性的应用案例。


我们的模型与其他模型在两个特殊任务上的定性比较:风格化和动作指导。

与更多基于微调的模型的比较。

重新语境化环境中的可视化。这些例子展示了ConsistentID的高身份保真度和文本编辑能力。

消融实验
不同合并步骤下的可视化结果。合并步骤指示何时开始向文本提示添加面部图像特征。

结论
在这项工作中,我们介绍了ConsistentID,这是一种创新的方法,旨在保持身份一致性并捕捉不同的面部细节。我们已经开发两个新颖的模块:多模式面部提示生成器和身份保存网络。前者致力于通过在面部区域级别结合视觉和文本描述来生成多模式面部提醒。后者旨在通过面部注意力定位策略确保每个面部区域的ID一致性,防止ID信息混合不同的面部区域。
通过利用多模式细粒度提示,我们的方法仅使用单个面部图像就实现了显著的身份一致性和面部真实感。此外,我们还介绍了FGID数据集,这是一个全面的数据集,包含细粒度的身份信息和详细的面部描述,对训练ConsistentID模型至关重要。实验结果在个性化面部生成方面表现出卓越的准确性和多样性,超过了MyStyle数据集上的现有方法。
限制
在我们的方法中使用MLLM可能会引入一些限制,这些限制可能会影响模型性能的特定方面。约束条件有限的姿势和表情可能会限制我们方法的多样性, 影响其处理面部变化的能力。这些限制强调深入讨论和探索的必要性,特别是在解决与GPT-4V的姿态、表达和整合相关的挑战。
这篇关于优于InstantID!中山大学提出ConsistentID:可以仅使用单个图像根据文本提示生成不同的个性化ID图像的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




