清华专题

SparseDrive - 清华地平线开源的e2e的框架
清华地平线合作开发的e2e的框架 SparseDrive资源 论文 https://arxiv.org/pdf/2405.19620 git https://github.com/swc-17/SparseDrive 个人觉得该文章厉害的地方 纯sparse mapping, 3d detection方案, 用的检测头sparse4D V3 sparsev1v2v3基本一致,map也是稀疏检

从清华网站下载Android代码
wget -c https://mirrors.tuna.tsinghua.edu.cn/aosp-monthly/aosp-latest.tar # 下载初始化包tar xvf aosp-latest.tarcd AOSPrepo sync -j4. build/envsetup.shlunch #选择一个编译目标#这里输入19make -j8
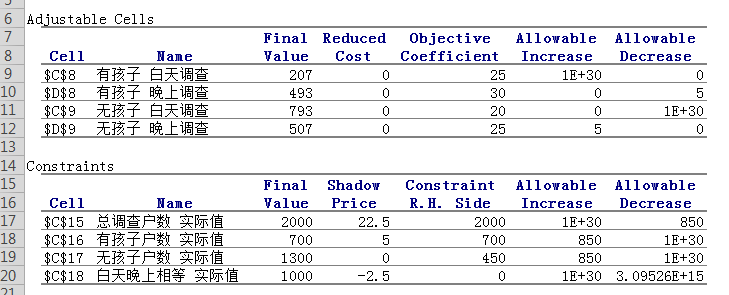
清华MEM作业-利用管理运筹学的分析工具slover求解最优解的实现 及 通过使用文件或者套节字来识别进程的fuser命令
一、清华MEM作业-利用管理运筹学的分析工具slover求解最优解的实现 最近又接触了一些线性求解的问题,以前主要都是在高中数学里接触到,都是使用笔算,最后通过一些函数式得出最小或者最大值,最近的研究生学业上接触到了一个Excel solver分析工具,对这种线性求最优解的问题感觉使用起来真是得心应手。在使用这个工具前,EXCEL里需要先装上solver工具,装起来很也简单,网上

anaconda(conda)清华源下载大文件包经常断
·今天新电脑,装了个anaconda, 因为GPU也是新装的,驱动自带的cuda版本 conda的源改成清华源之后,发现很不稳定,而且碰到超过100M的包,就基本崩溃了,又慢,还经常超时,我估计是用的人实在太多了,我下一个cudatoolkit,半天下不下来。 最简单的办法就是改源,我是直接改源了,本地创建太麻烦,而且还需要特殊方式。 看下图, 换成中科大的:(ps: 上交大的也可以,但是上

清华计算几何-线段求交与BO算法
单轴线段求交 给定单边轴下, N定线段,检查出相交的线段. 解法一: 暴力求解 遍历所有线段对,进行相交判断, 算法复杂度为O(n2) 解法二: LR扫描 把每条线段的头尾认定为L和R。对所有点进行排序,如果每两个点满足LL或者RR,则对应的线段相交。如果为LR,则对应的线段无相交,算法复杂度为O(nlog(n)) 多轴线段求交 - BO算法(line sweep) 上
pip安装第三方库使用清华镜像
pip安装python第三方库时,下载很慢,等待时间较长,最终可能下载失败。 推荐使用清华镜像:https://pypi.tuna.tsinghua.edu.cn/simple 通常,pip安装方法:pip install lxml 使用清华镜像的下载:pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple 快速下载,安装。
清华学者:知识图谱永远不会繁荣的五个原因
作者董胜王博士和朱宏寅博士详细分析了知识图谱(Knowledge Graph, KG)技术所面临的挑战,探讨了该技术在未来二十年内可能难以取得突破的原因。 实体难以泛化:实体的粒度和歧义问题是知识图谱的主要挑战之一。实体的定义往往缺乏明确的边界,且同一个实体可能在不同的场景中具有不同的含义。此外,知识图谱中使用的嵌入模型虽然在某些任务中表现出色,但并未解决实体泛化和歧义的问题,这导致了这些模型

超高清图像生成新SOTA!清华唐杰教授团队提出Inf-DiT:生成4096图像比UNet节省5倍内存。
清华大学唐杰教授团队最近在生成超高清图像方面的新工作:Inf-DiT,通过提出一种单向块注意力机制,能够在推理过程中自适应调整内存开销并处理全局依赖关系。基于此模块,该模型采用了 DiT 结构进行上采样,并开发了一种能够上采样各种形状和分辨率的无限超分辨率模型。与常用的 UNet 结构相比,Inf-DiT 在生成 4096×4096 图像时可以节省超过 5 倍的内存。该模型在机器和人类评估中均实现
清华TUNA镜像源下载Android源码的方法
本文在写作时是测试成功的,建议参考以下网页 Google教程: https://source.android.com/source/downloading.html TUNA的AOSP使用帮助: https://mirrors.tuna.tsinghua.edu.cn/help/AOSP/ 安装GIT(Ubuntu) sudo apt-get install git

PYTHON设置默认清华源
首先打开windows的运行窗口输入 %appdata% ,或者打开目“C:\Users\Administrator\AppData\Roaming” 在新弹出的窗口新建一个pip的文件夹,进入文件夹后,创建一个pip.ini的文件,在文件中写入如下内容: [global]timeout = 6000index-url = https://pypi.tuna.tsinghua.edu.cn

conda安装pytorch使用清华源
原命令,例: # CUDA 11.3conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch 使用清华源,例: # CUDA 11.3conda install pytorch==1.11.0 torchvision==0.12.0 torchaudi

用清华源安装docker-ce引擎
由于某些原因,用官方方式安装docker-ce可能会失败,这里提供一种替代方法,用清华源安装,并以Ubuntu系统为例。 1、删除安装过的docker: for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do apt-get remove $pkg; done 2、安装依赖: apt
清华源停止Anaconda镜像
文章目录 关于停止Anaconda镜像服务的通知也就是重2019-5-22用conda 清华源不能工作时发现的。 唉,现在只能用官方源了换回anaconda官方源官方地址 关于停止Anaconda镜像服务的通知 2019-04-16 TUNA Staff 根据 Anaconda 软件源上的说明,Anaconda 和 Miniconda 是 Anaconda, Inc. 的商标,任
Ubuntu 22.04,把软件更新源更改为阿里或者清华镜像
通常这应该是装上系统后做的第一件事,阿里/清华二选一,本人亲测,可以成功 可以通过修改系统的/etc/apt/sources.list文件来完成。以下是详细步骤: 修改/etc/apt/sources.list 打开终端。 备份当前的/etc/apt/sources.list文件: sudo cp /etc/apt/sources.list /etc/apt/sources.list.b
2024全国高考作文题解读(清华智普3Pro版本)
新课标I卷 阅读下面的材料,根据要求写作。(60分) 随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少? 以上材料引发了你怎样的联想和思考?请写一篇文章。 要求:选准角度,确定立意,明确文体,自拟标题;不要套作,不得抄袭;不得泄露个人信息;不少于800字。 互联网与人工智能时代的知识探索与问题解决 随着互联网的普及和人工智能的应用,
在内网中反向代理清华镜像
在内网环境中,服务器经常需要访问外部资源,如开源软件的镜像站。然而,直接访问可能受限于多种因素,如网络策略或地理位置。此时,设置一个反向代理服务器可以极大地方便内网中的服务器访问和更新软件包。本文将介绍如何使用 Nginx 在内网中反向代理清华大学的开源镜像站,并确保通过 HTTPS 安全访问。 域名与 SSL 证书 在配置反向代理时,使用域名 mirror.abc.com 代替直接使用 IP

斯坦福 AI 团队被指抄袭清华大模型:细节揭秘
近日,斯坦福AI团队因发布的AI模型被指抄袭清华大学的研究成果而陷入争议。本文将详细探讨这一事件的背景、关键细节及其对开源社区的影响。 事件背景 斯坦福的AI团队发布了一个名为“LLaMA-3V”的模型,声称只花了500美元且只用了GPT-4的1%的体量便达到了同等的图片识别能力。然而,很快有消息指出,这个模型涉嫌抄袭清华大学的“Mini-CPM-LLaMA-3V2.5”模型。尽管斯坦福团队最

斯坦福AI团队抄袭事件,清华回应:也算国际认可
近日,斯坦福大学人工智能(AI)团队的一项备受瞩目的研究——Llama3-V大模型,陷入了抄袭风波。该团队原本以其创新的模型和低廉的训练成本为亮点,声称能够在低成本下训练出性能卓越的SOTA多模态大模型。然而,随着抄袭指控的浮出水面,这一切都显得那么苍白无力。 抄袭的对象不是别人,正是来自中国清华系的明星创业公司面壁智能所开发的MiniCPM-Llama3-V 2.5模型。有细心的网友发现,

CentOS7配置国内清华源并安装docker-ce以及配置docker加速
说明 由于国内访问国外的网站包括docker网站,由于种种的原因经常打不开,或无法访问,所以替换成国内的软件源和国内镜像就是非常必要的了,这里整理了我安装配置的基本的步骤。 国内的软件源有很多,这里选择清华源作为国内源。 1、配置CentOS 软件国内源仓库 主要是替换http://mirror.centos.org为https://mirrors.tuna.tsinghua.edu.cn

【清华集训2017模拟】Create
Description Input Output Sample Input 5 5 5 1 5 4 1 1 2 5 3 4 5 2 3 5 3 1 2 3 3 5 2 7 1 6 13 12 13 12 14 15 13 13 13 11 12 12 Sample Output 5 9 13 9 9 13 Solution 由于开学军训,

机器之心 | 清华接手,YOLOv10问世:性能大幅提升,登上GitHub热榜
本文来源公众号“机器之心”,仅用于学术分享,侵权删,干货满满。 原文链接:清华接手,YOLOv10问世:性能大幅提升,登上GitHub热榜 相同性能情况下,延迟减少 46%,参数减少 25%。 目标检测系统的标杆 YOLO 系列,再次获得了重磅升级。 自今年 2 月 YOLOv9 发布之后, YOLO(You Only Look Once)系列的接力棒传到了清华大学研究人员的手上

清华新突破||新研究揭示多智能体协作的秘密武器
获取本文论文原文PDF,请在公众号【AI论文解读】留言:论文解读点击订阅:人工智能论文解读合集 引言:多智能体协作中的挑战与机遇 在多智能体系统中,智能体需要通过协作来完成复杂的任务,这种协作涉及到通信、协调和决策制定等多个方面。尽管多智能体系统的研究已经取得了一定的进展,但在实际应用中,如何有效地实现智能体之间的协作仍然是一个重大挑战。 一方面,多智能体协作提供了处理复杂问题
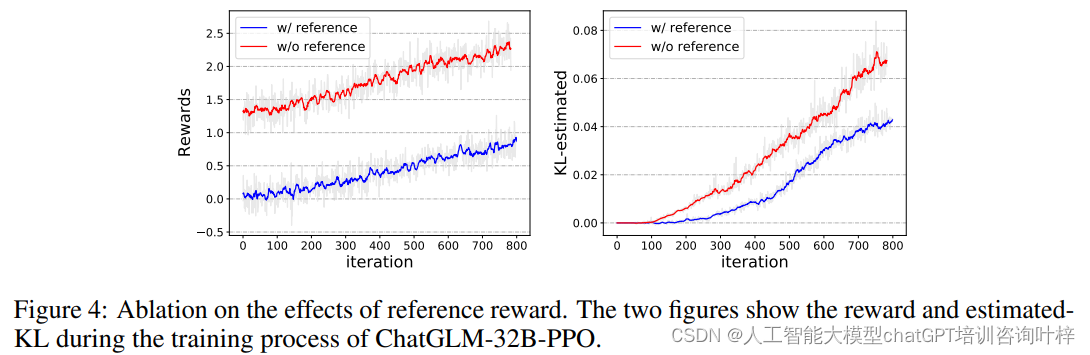
清华团队推出免费AI服务:与人类偏好对齐的大型语言模型
在人工智能领域,大型语言模型(LLMs)的迅猛发展极大地推动了机器在语言理解和生成方面的能力。然而,如何让这些模型更好地与人类偏好和价值观对齐,成为了一个重要而紧迫的课题。为此清华团队推出一项免费服务ChatGLM-RLHF,一个基于人类反馈的强化学习系统,旨在解决大型语言模型(LLMs)与人类偏好对齐的问题。该系统通过收集人类对模型生成文本的偏好反馈,训练一个奖励模型来评估响应质量,并以此指导策

清华博士导师整理:Tensorflow 和 Pytorch 的笔记(包含经典项目实战)
作为一名 AI 工程师,掌握一门深度学习框架是必备的生存技能之一。 自 TensorFlow 从 Google 中脱颖而出以来,它在研究和商业领域成为最受欢迎的开源深度学习框架,紧接着 从 Facebook 诞生的 PyTorch 由于社区推动的易用性改进和越来越广泛的用例部署,而迅速赶上TensorFlow。 两个框架在当年一度备受争议,TensorFlow 和 PyTorch 谁更好? 从去
centos7切换yum为清华阿里云
yum -y update 升级所有包,改变软件设置和系统设置,系统版本内核都升级 yum -y upgrade升级所有包,不改袭变软件设置和系统设置,系统版本升级,内核不改变 所以不要随便使用 update 清华大学镜像仓库:https://mirrors.cnnic.cn/ mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d
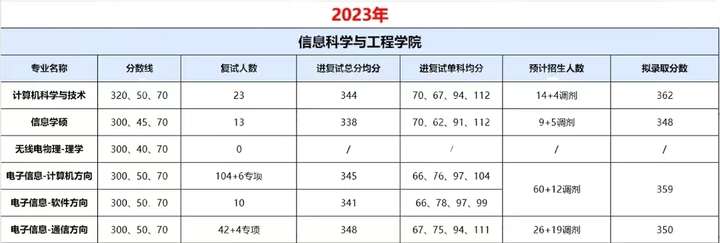
调剂”小清华“、不保护一志愿?——兰州大学25计算机考研考情分析
兰州大学(Lanzhou University),简称“兰大”,是中华人民共和国教育部直属 全国重点大学,中央直管副部级建制,位列国家首批“双一流(A 类)”、“211 工 程”、“985 工程”大学行列,入选国家“珠峰计划”、“2011 计划”、“111 计划”、 “卓越法律人才教育培养计划”、“卓越农林人才教育培养计划”、“国家大学生创 新性实验计划”、“海外高层次人才引进计划”,全国首批具有