本文主要是介绍清华新突破||新研究揭示多智能体协作的秘密武器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
获取本文论文原文PDF,请在公众号【AI论文解读】留言:论文解读
点击订阅:人工智能论文解读合集

引言:多智能体协作中的挑战与机遇
在多智能体系统中,智能体需要通过协作来完成复杂的任务,这种协作涉及到通信、协调和决策制定等多个方面。尽管多智能体系统的研究已经取得了一定的进展,但在实际应用中,如何有效地实现智能体之间的协作仍然是一个重大挑战。
一方面,多智能体协作提供了处理复杂问题的新机遇。例如,在灾难响应、自动驾驶、智能制造等领域,多智能体协作能够有效地分配和优化资源,提高系统的整体效率和响应速度。此外,通过集体智慧,多智能体系统能够完成单个智能体难以独立完成的任务,如复杂的搜索和救援任务。
另一方面,多智能体协作也面临着众多挑战。首先,智能体之间的通信可能受到限制,如信号干扰、传输延迟等问题,这些因素都可能影响协作的效率和效果。其次,如何设计有效的协作策略以适应动态变化的环境和任务需求,是另一个需要解决的问题。此外,智能体的自主性和个体差异也可能导致协作中出现冲突和协调困难。
为了克服这些挑战,研究人员提出了多种方法和技术。例如,通过增强智能体的学习和适应能力,使其能够在没有中央控制的情况下自我组织和协调;利用机器学习和优化算法来设计高效的协作策略;以及开发新的通信协议和算法来改善智能体之间的信息交换。
总之,多智能体协作是一个充满挑战和机遇的研究领域。通过不断的技术创新和方法改进,有望在未来实现更加智能和高效的多智能体协作系统,为解决复杂的实际问题提供强有力的支持。
论文标题: Towards Efficient LLM Grounding for Embodied Multi-Agent Collaboration
机构: Tsinghua University, Northwestern Polytechnical University, Shanghai AI Laboratory, Zhejiang University, Institute of Artificial Intelligence (TeleAI), China Telecom
论文链接:https://arxiv.org/pdf/2405.14314.pdf
项目地址:https://read-llm.github.io/
理论基础:多智能体系统中的优势函数学习
1. 联合优势函数的定义与估计
在多智能体系统中,联合优势函数是基于联合价值函数和状态价值函数的差异来定义的。具体来说,如果我们考虑一个状态 ( s ) 和一个联合动作 ( a ),联合优势函数 ( A^\pi(s, a) ) 可以表示为 ( Q^\pi(s, a) - V^\pi(s) )。这里,( Q^\pi(s, a) ) 是在给定状态和联合动作下的期望回报,而 ( V^\pi(s) ) 是在给定状态下的期望回报。通过这种方式,优势函数能够衡量采取特定联合动作相对于平均情况的额外价值。
2. 局部优势函数与优势分解
局部优势函数考虑的是在多智能体环境中,单个智能体或一组智能体的动作对整体性能的贡献。通过优势分解,我们可以将联合优势函数分解为各个智能体的局部优势函数之和。这种分解有助于在复杂的多智能体环境中,明确每个智能体动作的独立贡献,从而优化整体策略。局部优势函数的估计通常依赖于蒙特卡洛方法,通过对局部价值函数的采样和回归分析来实现。
Reinforced Advantage (ReAd) 框架介绍
1. ReAd-S 与 ReAd-J 的策略细节
ReAd框架提供了两种策略:ReAd-S和ReAd-J。ReAd-S针对每个智能体单独优化其动作,通过评估每个智能体动作的局部优势函数来进行。而ReAd-J则是在所有智能体之间进行联合计划,优化整体的联合动作,通过评估联合优势函数来实现。这两种策略都利用了一个批评网络来回归估计从大规模语言模型(LLM)计划的数据中学到的优势函数,并将LLM规划器作为优化器,通过提示生成最大化优势值的动作。
2. 理论动机与约束策略搜索问题
ReAd框架的理论基础是在多智能体设置中扩展了加权优势回归。通过这种方法,我们可以将LLM作为基本策略,并搜索比它更强的策略。具体来说,我们的目标是找到一个策略 (\pi),它在期望改进 (\eta(\pi) = J(\pi) - J(\mu)) 方面最大化超过基本策略 (\mu)。通过引入一个替代目标 (\hat{\eta}(\pi)) 来近似 (\eta(\pi)),并形成一个约束策略搜索问题,其中约束确保新策略接近基本策略,从而使得 (\hat{\eta}(\pi)) 成为 (\eta(\pi)) 的一个精确近似。这种方法允许系统在保持策略改进的同时,减少与环境的交互,提高了多智能体协作任务中的效率和效果。

实验设置与环境介绍
1. DV-RoCoBench 和 Overcooked-AI 环境
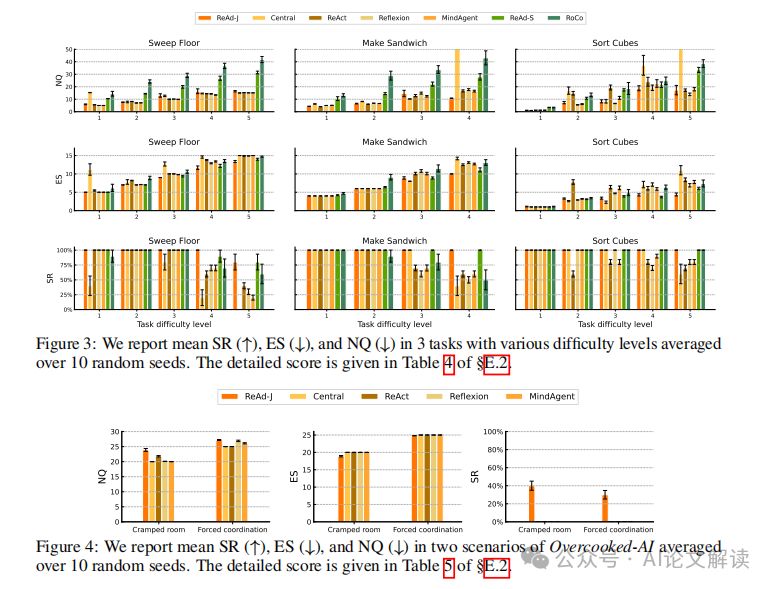
DV-RoCoBench 是从 RoCoBench 演变而来的一个更具挑战性的多机器人协作环境。它包括三个任务:扫地、制作三明治和分类立方体,每个任务都有不同的难度级别。例如,在扫地任务中,机器人需要协作将指定颜色的立方体扫入垃圾桶。任务的难度通过增加立方体的数量和目标颜色的立方体数量来逐级增加。
Overcooked-AI 是一个基于流行视频游戏 Overcooked 的全合作多代理基准环境。在这个环境中,代理需要尽快交付汤。每份汤需要放置多达三种成分在锅中,等待一定的时间让汤煮熟,然后由一个代理取出汤并交付。我们选择了两个代表性场景:狭窄的房间和强制协调,这些场景从低级的运动协调挑战到高级的策略协调挑战不等。
2. 实验设计与基线方法
在 DV-RoCoBench 和 Overcooked-AI 的实验中,我们使用 GPT-4-Turbo 作为所有实验的基础 LLM 策略。我们将 ReAd-J 与三个强大的闭环基线方法进行比较:ReAct、Reflexion 和 MindAgent,这些方法都是并行生成代理计划的。在 DV-RoCoBench 中,我们还添加了一个名为 RoCo 的基线,该基线在原始 RoCoBench 中表现出色,用于与 ReAd-S 进行比较。这些方法的输出都是以并行方式生成的。
实验结果与分析
1. 在 DV-RoCoBench 的表现
ReAd-S 和 ReAd-J 在所有指标上均优于对应的强基线,并实现了更有效的 LLM 接地。随着 DV-RoCoBench 中任务难度级别的提高,我们的方法在成功率 (SR) 上的表现逐渐显著优于基线方法。在更难的设置中(例如任务的第4或第5级别),我们的方法获得了更高的成功率,而基线方法未能取得进展。此外,ReAd-S 和 ReAd-J 在 DV-RoCoBench 的大多数任务中展示了较低的环境交互步数 (ES) 和可比或更低的查询次数 (NQ)。
2. 在 Overcooked-AI 的表现
由于 Overcooked-AI 内在的重协调挑战,除非 LLM 规划器生成高度协作的计划,否则基于 LLM 的代理无法推进任务完成。通过用优势函数替换物理验证反馈,我们的方法在 Overcooked-AI 的表现显著优于依赖物理验证反馈的方法。在多代理协作的更具挑战性的场景中,我们的方法展示了卓越的规划能力和更好的 LLM 接地结果。

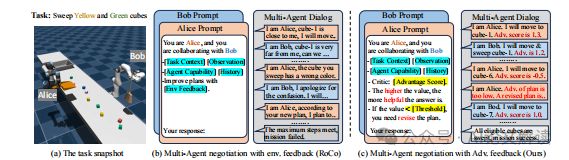
策略改进与反馈机制
1. 优势反馈的作用与实现
在多智能体合作任务中,优势反馈(ReAd)通过评估行动的优势函数来优化计划,从而提高了计划的有效性和效率。ReAd方法包括两种方案:ReAd-S和ReAd-J。ReAd-S针对每个智能体的单独行动进行优化,而ReAd-J则对所有智能体的联合行动进行评估。这种反馈机制通过预训练的批评网络来估计生成行动的优势分数,并在分数低于阈值时提示智能体重新计划,从而确保所采取的行动能有效推进任务目标。
2. 策略细化与单步与多步版本的比较
策略细化是ReAd方法中的一个关键环节,它通过多轮优化来提高行动的优势分数,从而提升整体策略的效果。在实验中,对比单步版本(无细化)和多步版本(有细化),多步版本在复杂任务中表现出更高的成功率和效率。单步版本虽然在某些情况下能够达到相对较高的成功率,但通常需要更多的环境交互和查询,而多步版本通过在执行前优化行动计划,显著减少了这些需求。
讨论与未来工作方向
1. ReAd 方法的优势与局限
ReAd方法通过优势反馈机制有效地提升了智能体的计划质量和执行效率,尤其是在多智能体协作任务中。然而,ReAd的实现依赖于准确的优势函数估计,这可能受到数据质量和分布的限制。此外,ReAd在处理突发环境变化时表现出了优越的适应性,但其在更广泛的任务类型和更复杂的环境中的表现仍需进一步验证。
2. 多目标与安全规划的应用展望
未来的工作可以探索将ReAd方法扩展到多目标和安全关键的规划任务中。在多目标规划中,优势反馈可以帮助智能体在满足多种目标的同时优化其行动策略。在安全规划中,通过引入安全约束到优势函数中,ReAd可以在确保任务执行的安全性的同时,提高任务的成功率。此外,结合最新的强化学习理论和技术,如安全强化学习,可能会进一步提升ReAd方法在复杂环境中的应用效果和鲁棒性。
总结:ReAd 在多智能体协作中的应用与影响
Reinforced Advantage (ReAd) 是一种新颖的反馈机制,专为多智能体协作任务中的大型语言模型(LLM)设计。通过在多智能体系统中引入优势函数,ReAd 改进了传统的物理验证反馈方法,提高了任务规划的效率和成功率。
1. ReAd 的工作原理
ReAd 通过两种方案进行计划的优化和细化:顺序个体计划优化(ReAd-S)和联合计划优化(ReAd-J)。ReAd-S 针对每个智能体的动作单独评估优势,而 ReAd-J 则评估所有智能体的联合动作的优势。这些优势函数通过批评网络回归LLM规划的数据来估算。利用这些优势函数,LLM规划器被用作优化器,通过提示生成最大化优势值的动作。
2. ReAd 的理论基础
ReAd 的理论基础扩展了单智能体强化学习中的优势加权回归到多智能体设置。通过优势分解,可以将联合优势函数分解为每个智能体的局部优势,从而在保持策略改进的同时简化了优化过程。
3. ReAd 的实验验证
在 DV-RoCoBench 和 Overcooked-AI 环境中的实验表明,ReAd 在成功率、智能体交互步数和LLM查询轮数方面均优于基线方法。特别是在多智能体协作的复杂场景中,ReAd 通过优势函数反馈,有效地指导了LLM生成更合理的协作计划。
4. ReAd 的优势
与传统的物理验证反馈相比,ReAd 减少了智能体与环境的交互次数,降低了计算成本,并提高了响应速度。此外,ReAd 通过优势反馈机制,能够在遇到突发干扰时迅速调整计划,显示出更强的鲁棒性。
5. ReAd 的未来应用
ReAd 的成功应用展示了其在多智能体协作任务中的潜力,未来可以扩展到多目标和安全规划场景,进一步提高智能体系统的智能化和自动化水平。
这篇关于清华新突破||新研究揭示多智能体协作的秘密武器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!