本文主要是介绍机器之心 | 清华接手,YOLOv10问世:性能大幅提升,登上GitHub热榜,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文来源公众号“机器之心”,仅用于学术分享,侵权删,干货满满。
原文链接:清华接手,YOLOv10问世:性能大幅提升,登上GitHub热榜
相同性能情况下,延迟减少 46%,参数减少 25%。
目标检测系统的标杆 YOLO 系列,再次获得了重磅升级。

自今年 2 月 YOLOv9 发布之后, YOLO(You Only Look Once)系列的接力棒传到了清华大学研究人员的手上。
上周末,YOLOv10 推出的消息引发了 AI 界的关注。它被认为是计算机视觉领域的突破性框架,以实时的端到端目标检测能力而闻名,通过提供结合效率和准确性的强大解决方案,延续了 YOLO 系列的传统。

论文地址:https://arxiv.org/pdf/2405.14458
项目地址:https://github.com/THU-MIG/yolov10
新版本发布之后,很多人已经进行了部署测试,效果不错。
视频1:

视频二:
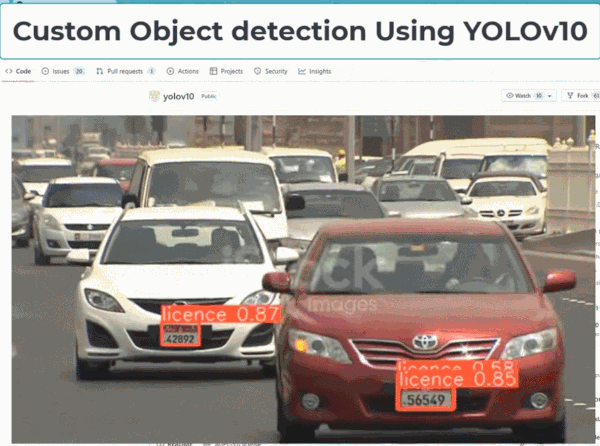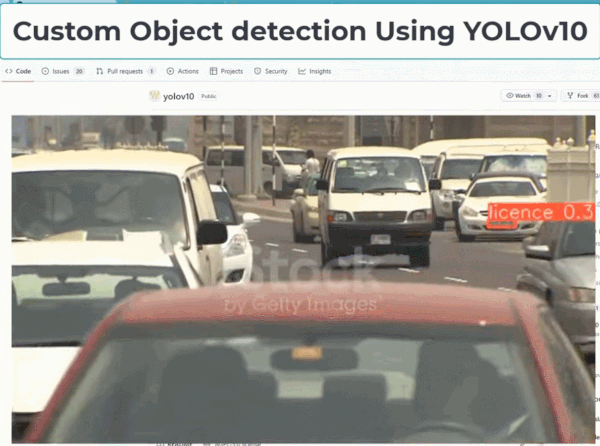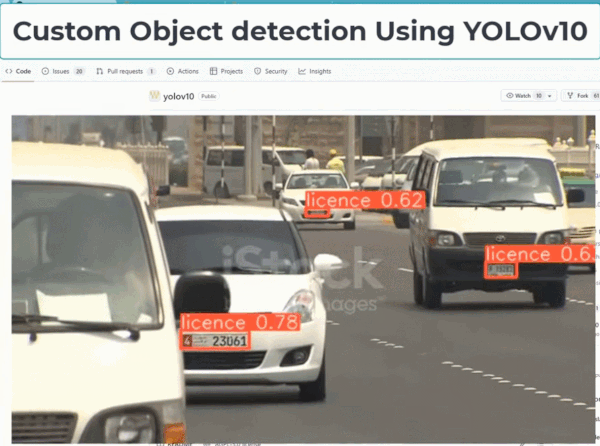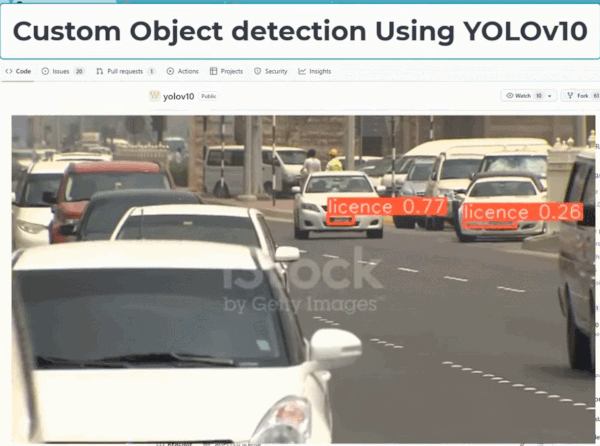
YOLO 因为性能强大、消耗算力较少,一直以来都是实时目标检测领域的主要范式。该框架被广泛用于各种实际应用,包括自动驾驶、监控和物流。其高效、准确的物体检测能力使其成为实时识别行人和车辆等任务的理想选择;在物流方面,它有助于库存管理和包裹跟踪,通过 AI 能力帮助人们在很多工作上提高了效率。
几年来,研究人员对 YOLO 的架构设计、优化目标、数据增强策略等进行了探索,取得了显著进展。然而,后处理对非极大值抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生不利影响。此外,YOLO 中各个组件的设计缺乏全面彻底的检查,导致明显的计算冗余并限制了模型的能力。
YOLOv10 的突破就在于从后处理和模型架构方面进一步提升了 YOLO 的性能 - 效率边界。
为此,研究团队首次提出了 YOLO 无 NMS 训练的一致双重分配(consistent dual assignment),这使得 YOLO 在性能和推理延迟方面有所改进。
研究团队为 YOLO 提出了整体效率 - 准确率驱动的模型设计策略,从效率和准确率两个角度全面优化 YOLO 的各个组件,大大降低了计算开销并增强了模型能力。
大量实验表明,YOLOv10 在各种模型规模上都实现了 SOTA 性能和效率。例如,YOLOv10-S 在 COCO 上的类似 AP 下比 RT-DETR-R18 快 1.8 倍,同时参数数量和 FLOP 大幅减少。与 YOLOv9-C 相比,在性能相同的情况下,YOLOv10-B 的延迟减少了 46%,参数减少了 25%。

方法介绍
为了实现整体效率 - 准确率驱动的模型设计,研究团队从效率、准确率两方面分别提出改进方法。
为了提高效率,该研究提出了轻量级分类 head、空间通道(spatial-channel)解耦下采样和排序指导的块设计,以减少明显的计算冗余并实现更高效的架构。
为了提高准确率,研究团队探索了大核卷积并提出了有效的部分自注意力(partial self-attention,PSA)模块来增强模型能力,在低成本下挖掘性能改进的潜力。基于这些方法,该团队成功实现了一系列不同规模的实时端到端检测器,即 YOLOv10-N / S / M / B / L / X。
用于无 NMS 训练的一致双重分配
在训练期间,YOLO 通常利用 TAL 为每个实例分配多个正样本。一对多的分配方式产生了丰富的监督信号,促进了优化并使模型实现了卓越的性能。
然而,这需要 YOLO 依赖于 NMS 后处理,这导致了部署时次优的推理效率。虽然之前的研究工作探索了一对一匹配来抑制冗余预测,但它们通常引入了额外的推理开销。
与一对多分配不同,一对一匹配对每个 ground truth 仅分配一个预测,避免 NMS 后处理。然而,这会导致弱监督,以至于准确率和收敛速度不理想。幸运的是,这种缺陷可以通过一对多分配来弥补。
该研究提出的「双标签分配」结合了上述两种策略的优点。如下图所示,该研究为 YOLO 引入了另一个一对一 head。它保留了与原始一对多分支相同的结构并采用相同的优化目标,但利用一对一匹配来获取标签分配。在训练过程中,两个 head 联合优化,以提供丰富的监督;在推理过程中,YOLOv10 会丢弃一对多 head 并利用一对一 head 做出预测。这使得 YOLO 能够进行端到端部署,而不会产生任何额外的推理成本。

整体效率 - 准确率驱动的模型设计
除了后处理之外,YOLO 的模型架构也对效率 - 准确率权衡提出了巨大挑战。尽管之前的研究工作探索了各种设计策略,但仍然缺乏对 YOLO 中各种组件的全面检查。因此,模型架构表现出不可忽视的计算冗余和能力受限。
YOLO 中的组件包括 stem、下采样层、带有基本构建块的阶段和 head。作者主要对以下三个部分执行效率驱动的模型设计。
-
轻量级分类 head
-
空间通道解耦下采样
-
排序指导的模块设计
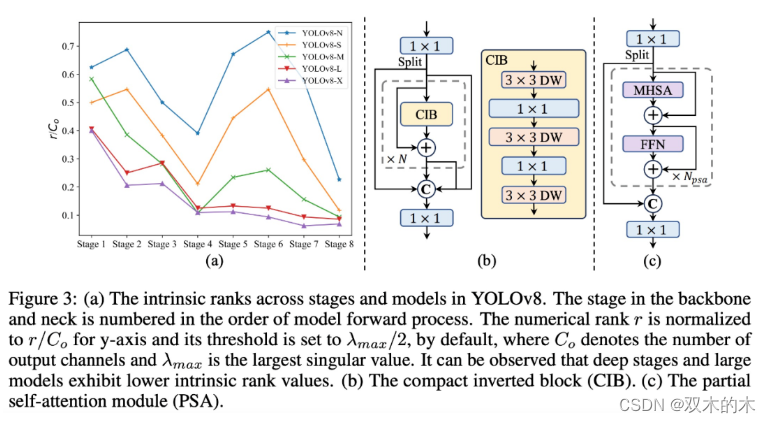
为了实现准确率驱动的模型设计,研究团队进一步探索了大核卷积和自注意力机制,旨在以最小的成本提升模型性能。
实验
如表 1 所示,清华团队所开发的的 YOLOv10 在各种模型规模上实现了 SOTA 的性能和端到端延迟。

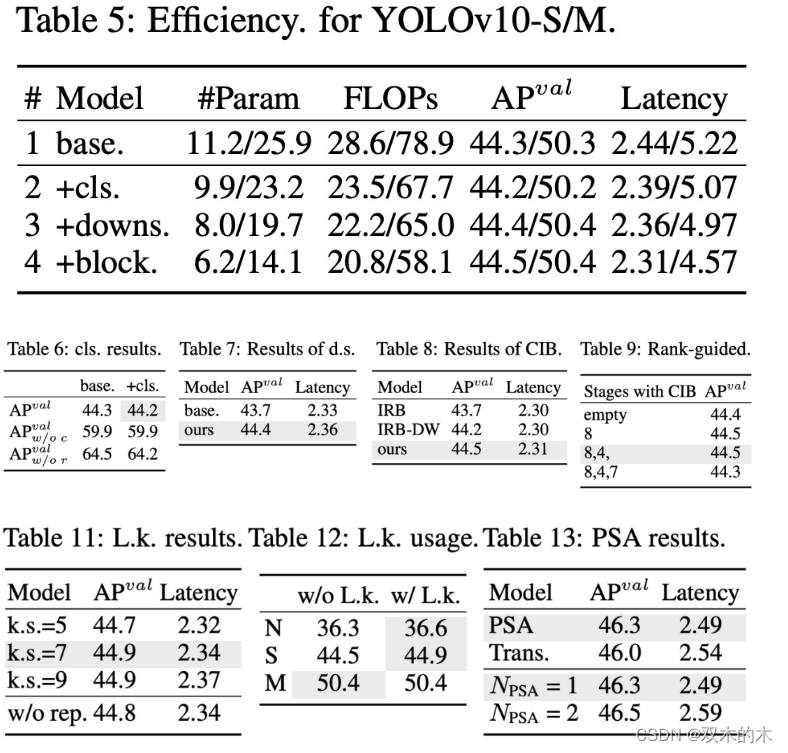
该研究还针对 YOLOv10-S 和 YOLOv10-M 进行了消融实验,实验结果如下表所示:

如下表所示,双标签分配实现了最佳的 AP - 延迟权衡,采用一致匹配度量可以达到最优性能。

如下表所示,每个设计组件,包括轻量级分类 head、空间通道解耦下采样和排序指导的模块设计,都有助于减少参数数量、FLOPs 和延迟。重要的是,这些改进是在保持卓越性能的同时所实现的。
针对准确性驱动的模型设计的分析。研究人员展示了基于 YOLOv10-S/M 逐步集成准确性驱动设计元素的结果。
如表 10 所示,采用大核卷积和 PSA 模块分别在延迟最小增加 0.03ms 和 0.15ms 的情况下,使 YOLOv10-S 的性能有了 0.4% AP 和 1.4% AP 的显著提升。

参考内容:
https://visionplatform.ai/yolov10-object-detection/
https://www.youtube.com/watch?v=29tnSxhB3CY
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。
这篇关于机器之心 | 清华接手,YOLOv10问世:性能大幅提升,登上GitHub热榜的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






