本文主要是介绍Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

标题:用GPT-4增强CLIP:利用视觉描述作为提示
源文链接:Maniparambil_Enhancing_CLIP_with_GPT-4_Harnessing_Visual_Descriptions_as_Prompts_ICCVW_2023_paper.pdf (thecvf.com)![]() https://openaccess.thecvf.com/content/ICCV2023W/MMFM/papers/Maniparambil_Enhancing_CLIP_with_GPT-4_Harnessing_Visual_Descriptions_as_Prompts_ICCVW_2023_paper.pdf
https://openaccess.thecvf.com/content/ICCV2023W/MMFM/papers/Maniparambil_Enhancing_CLIP_with_GPT-4_Harnessing_Visual_Descriptions_as_Prompts_ICCVW_2023_paper.pdf
源码链接: mayug/VDT-Adapter: This repository contains the code and datasets for our ICCV-W paper 'Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts' (github.com)![]() https://github.com/mayug/VDT-Adapter
https://github.com/mayug/VDT-Adapter
发表:ICCV-2023
目录
摘要
1. 简介
2. 相关工作
3. 方法
3.1. 回顾CLIP和CLIP- adapter
3.2. 语言模型提示设计
3.2.1视觉描述性句子
3.2.2提示llm提供视觉描述性信息
3.3. 用于视觉句子的简单的少样本适配器
4. 实验
5. 结论
读后总结
摘要
对比预训练的视觉-语言模型(VLMs)如CLIP,通过在下游数据集上提供出色的性能,已经彻底改变了视觉表征学习。VLMs可以通过设计与数据集相关的提示(prompts)来零样本学习(0-shot)适应下游数据集。这种提示工程利用了领域专业知识和验证数据集。与此同时,生成式预训练模型如GPT-4的最新发展意味着它们可以作为先进的互联网搜索工具使用。它们还可以被操纵以提供任何结构的视觉信息。在这项工作中,我们展示了GPT-4可以用来生成具有视觉描述性的文本,并展示了如何利用这种文本来适应CLIP以完成下游任务。与CLIP的默认提示相比,我们在专门的细粒度数据集如EuroSAT(约7%)、DTD(约7%)、SUN397(约4.6%)和CUB(约3.3%)上展示了显著的零样本学习迁移准确率提升。我们还设计了一个简单的少样本学习适配器(few-shot adapter),它学习选择最佳句子来构建可泛化的分类器,这些分类器在平均性能上比最近提出的CoCoOP高出约2%,在四个专门的细粒度数据集上高出4%以上。代码、提示和辅助文本数据集已公开在github.com/mayug/VDT-Adapter。
1. 简介
视觉描述性文本visually descriptive textual (VDT)
我们将VDT定义为描述所考虑的类的视觉特征的一组句子,包括形状、大小、颜色、环境、图案、组成等。虽然大多数人可以通过它们的名字识别许多不同的常见鸟类,但他们需要获得鸟类描述的鸟类分类学来识别更多的稀有鸟类。同样,我们认为CLIP的0shot精度可以通过将VDT信息合并到提示符中来提高。如图1所示,在文本编码器的嵌入空间中,加入黑冠、黑尾等VDT信息使绿苍鹭的分类原型从绿啄木鸟的分类原型向黑鹭鸟的分类原型移动。
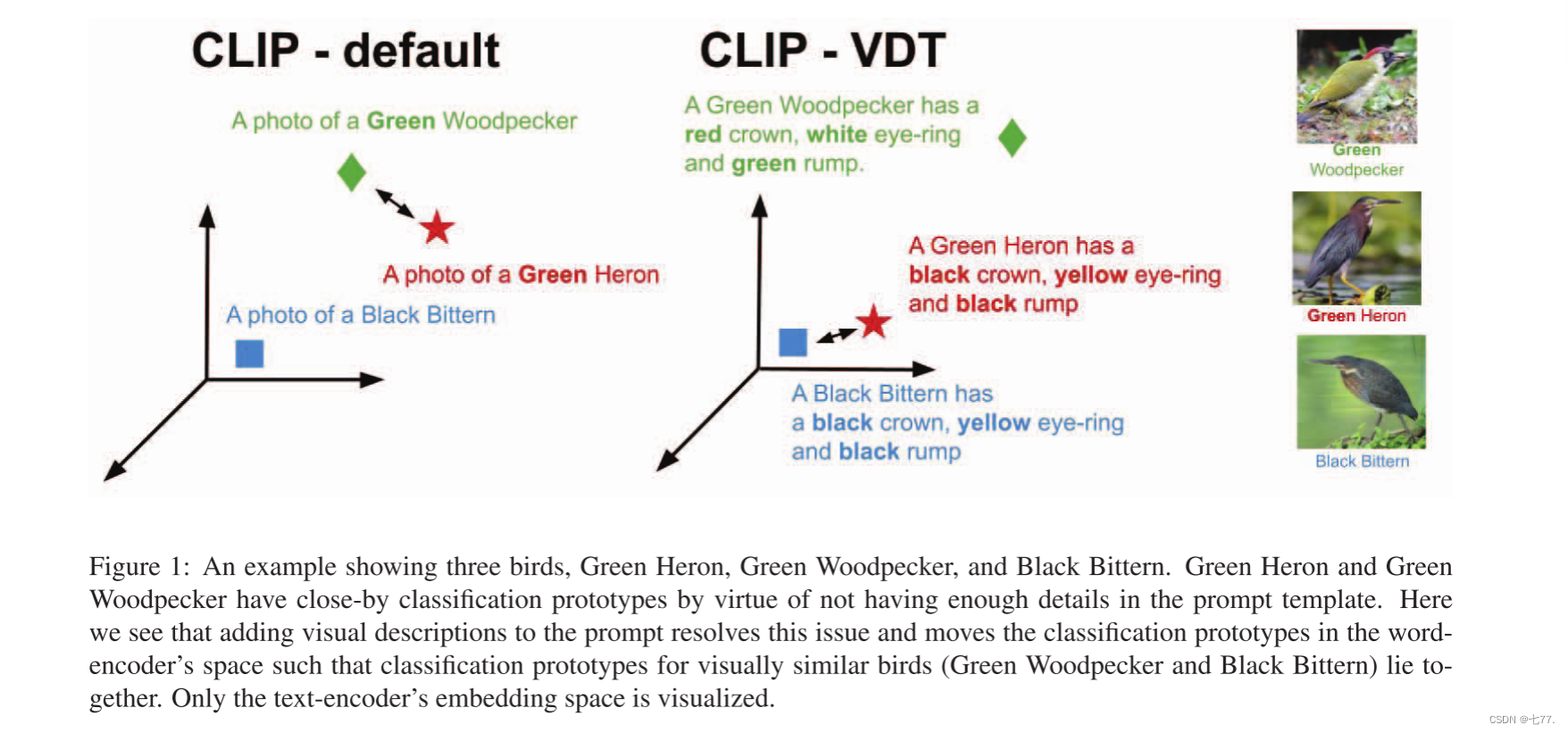
图1:以绿鹭、绿啄木鸟和黑卤鸟为例。绿苍鹭和绿啄木鸟由于提示模板中没有足够的细节而有相近的分类原型。在这里,我们看到在提示符中添加视觉描述解决了这个问题,并将分类原型移动到wordencoder的空间中,这样视觉上相似的鸟类(绿啄木鸟和黑卤鸟)的分类原型就放在一起了。只有文本编码器的嵌入空间是可视化的。
在这项工作中,我们首先展示了我们可以使用目标域中每个类的VDT信息来构造类条件提示,从而实现比CLIP默认提示的性能改进。
我们关注生成式预训练大型语言模型(llm)的最新进展,如GPT-4,以一种易于扩展到其他数据集的方式构建这些类条件提示。这些模型非常适合构建复杂提示的任务,因为:1)它们是人类知识的浓缩形式(在网络规模的文本数据上训练)[33];2)它们可以被操纵以产生任何形式或结构的信息,这使得与CLIP的提示风格的兼容性相对简单。因此,我们使用GPT-4来构建关于类的视觉描述性文本信息,并在GPT-4提示中特别强调关于形状、颜色、结构和组合性等视觉线索。我们使用生成的VDT信息来构建提示集合,这些集合通过CLIP的文本编码器并聚合以生成分类器,然后用于0-shot分类。使用GPT-4可以避免对领域知识的需要,并方便地提供类条件提示。提示集成VDT句子降低了CLIP对提示中微小变化的性能敏感性。
最后,我们设计了一个简单的适配器,它可以学习自适应地选择和聚合任何给定数据集的最佳句子,并表明利用这些额外的VDT信息也可以提高CLIP的少镜头域传输性能。我们在12个数据集的基准上证明了最近提出的Base-to-New设置的少拍自适应性能,并且优于最近的方法,如CoOp[36]和CoOp[35],尽管模型参数更少,训练时间更短,模型架构更简单。
简而言之,我们的贡献如下:
1.我们发现在提示符中加入视觉描述性文本(VDT)信息可以提高CLIP的零样本域传输性能。
2. 我们使用GPT-4以可扩展的方式生成VDT句子,并在零样本域传输中显示出比CLIP一致的性能改进。
3. 我们设计了一个简单的适配器网络,以利用这些额外的信息进行几次传输,并在Base-to-New设置中显示比CLIPAdapter和coop[35]等方法进行几次域传输的性能改进。
4. 我们发布了所有12个数据集的所有VDT信息,以促进大型VLMs低样本域转移的多模态提示和适配器设计的进一步研究。
2. 相关工作
并行工作[16]利用GPT-3通过在CLIP的嵌入空间中匹配gpt生成的候选文本来生成特定于图像的细粒度文本,并使用它们来改进下游分类。
我们使用GPT-4进行辅助数据收集,在字编码器空间中进行集成,并引入了一个多样本适配器,以便在多样本推理中进行最佳的VDT选择。[27]在扩散模型中使用GPT-3进行快速构建,生成支持集的图像,而我们的工作仅使用GPT4获取辅助文本数据。据我们所知,我们是第一个提示GPT-4视觉描述性句子,以提高CLIP的零样本和少样本的推理。
3. 方法
3.1. 回顾CLIP和CLIP- adapter
通过在大规模图文数据集上进行对比性预训练,CLIP能够对各种概念进行分类,将相关的图像和文本在共享的嵌入空间中进行对齐,同时将不相似的进行分离。在预训练之后,CLIP直接在目标数据集上进行图像分类,而无需任何微调。首先,我们回顾CLIP模型如何在开放集上进行零样本学习(0-shot)分类。
CLIP模型包括一个视觉模型和一个语言模型,它分别将图像及其对应的描述编码为视觉嵌入和文本嵌入。在推理过程中,这些嵌入通过余弦相似度进行比较。给定一个图像I ∈ RH×W×C,其中H、W、C分别表示图像的高度、宽度和通道数,视觉编码器将图像转换为联合嵌入空间以获取图像特征f ∈ RD,其中D表示特征的维度。
在推理过程中,使用诸如“A photo of {classname}”这样的提示模板来为K个不同的类别生成句子,并将这些句子通过文本编码器以产生分类器权重矩阵W ∈ RD×K。然后,通过将图像特征f与W相乘并应用softmax函数来计算预测概率:
在CLIP [25]中,零样本学习(0-shot)领域迁移利用了提示模板中的特定领域信息,例如对于鸟类图像,可以使用“A photo of a {class-name}, a type of bird”这样的模板。[25]报告称,精心设计的提示和提示集成对于提高零样本学习分类的准确率很重要。提示集成是通过为每个类别构建多个提示,然后平均这些分类向量来实现的。在我们的工作中,我们展示了VDT(视觉描述模板)的提示集成可以改善CLIP的零样本学习领域迁移。
CLIP-A [9] 是一个可学习的多层感知机(MLP)适配器,应用于图像和/或单词编码器的特征,以实现向目标数据集的少样本学习迁移。在少样本学习迁移过程中,给定每类N个带有标签的图像,记作(xi,k,yi,k)i=1,j=1...N,k=1...K,通过使用提示模板H和文本编码器g来构建K个分类器权重,即W = g(H(classname ({yi,k})))。图像特征f和文本特征W通过可学习的适配器Av、At进行适配,以得到适配后的特征,如下所示:
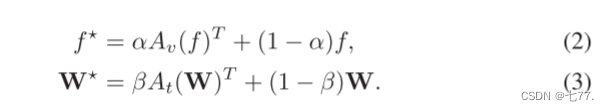
其中,α和β是超参数,用于控制原始特征和适配后特征之间的权重。T表示转置操作。
超参数α和β将CLIP的知识与微调后的知识相结合,以避免CLIP-Adapter过拟合。根据公式1计算logits,并使用整个训练集(xi,k,yi,k)i=1,j=K i=1,k=1上的交叉熵损失来优化Av和At。
在“All”设置中,少样本学习迁移是在一个保留的测试数据集上进行测试的,该测试集包含用于训练的K个类别的图像。而在[35]提出的“Base-to-New”设置中,评估是在U个非重叠的类别上进行的。我们的模型在更实用的“Base-to-New”设置下进行评估。
3.2. 语言模型提示设计
在本节中,我们将演示VDT如何增强CLIP的0-shot迁移功能,并概述使用LLM生成特定于类的提示符的方法。
3.2.1视觉描述性句子
[25]表明,精心设计的提示和提示集成可以提高CLIP的零样本学习分类性能。在这里,我们提出一个问题:可以在提示模板中添加什么类型的信息来改进零样本学习领域迁移的性能?我们展示了在提示模板中添加视觉描述性信息并进行集成,可以比默认提示和包含非视觉信息的提示更好地改善零样本学习性能。
使用带有专家标注的CUB数据集,我们对比了视觉和非视觉提示集成在零次学习中的性能。对于视觉提示,我们采用了描述颜色、图案、形状等属性的类属性向量,这些属性涵盖了28个鸟类身体部位,每只鸟对应312个得分。我们使用最显著的属性-值对来形成28个视觉提示(表示为Visual-GT),例如“一张绿鹭的照片。绿鹭有一个绿黑色的头冠。”相反,对于非视觉提示(表示为NonVisual-GT),我们收集了关于鸟类叫声、迁徙、行为和栖息地等信息,为每个类别生成了12个不同的提示,如“一张绿鹭的照片。绿鹭的叫声是一种响亮刺耳的‘skeow’声。”
我们通过在CLIP的联合嵌入空间内平均类级别的句子嵌入来推导Visual-GT和NonVisual-GT的分类向量,同时考虑到其77个标记的限制。表1显示,使用NonVisual-GT提示并没有比默认提示有所改善,但使用Visual-GT提示则有4%的性能提升。

3.2.2提示llm提供视觉描述性信息
在上一节中,我们强调了使用专家VDT(视觉描述文本)信息来创建特定类别的提示,以增强CLIP的零次学习性能。然而,获取专家标注既昂贵又耗时。为了克服这一难题,我们利用了以大规模知识和灵活性著称的GPT语言模型[33]。我们的方法涉及使用GPT-4为任何给定数据集生成视觉描述,从而帮助以可扩展的方式为CLIP构建提示集成。
我们的提示策略受到了链式思考提示[30]的启发,具体步骤如下:首先,我们请GPT-4列出可能需要用于区分K个类图像的所有属性。然后,我们请GPT-4以句子的形式为所有K个类提供这些属性的值。CUB数据集的一个例子如图1左侧所示。
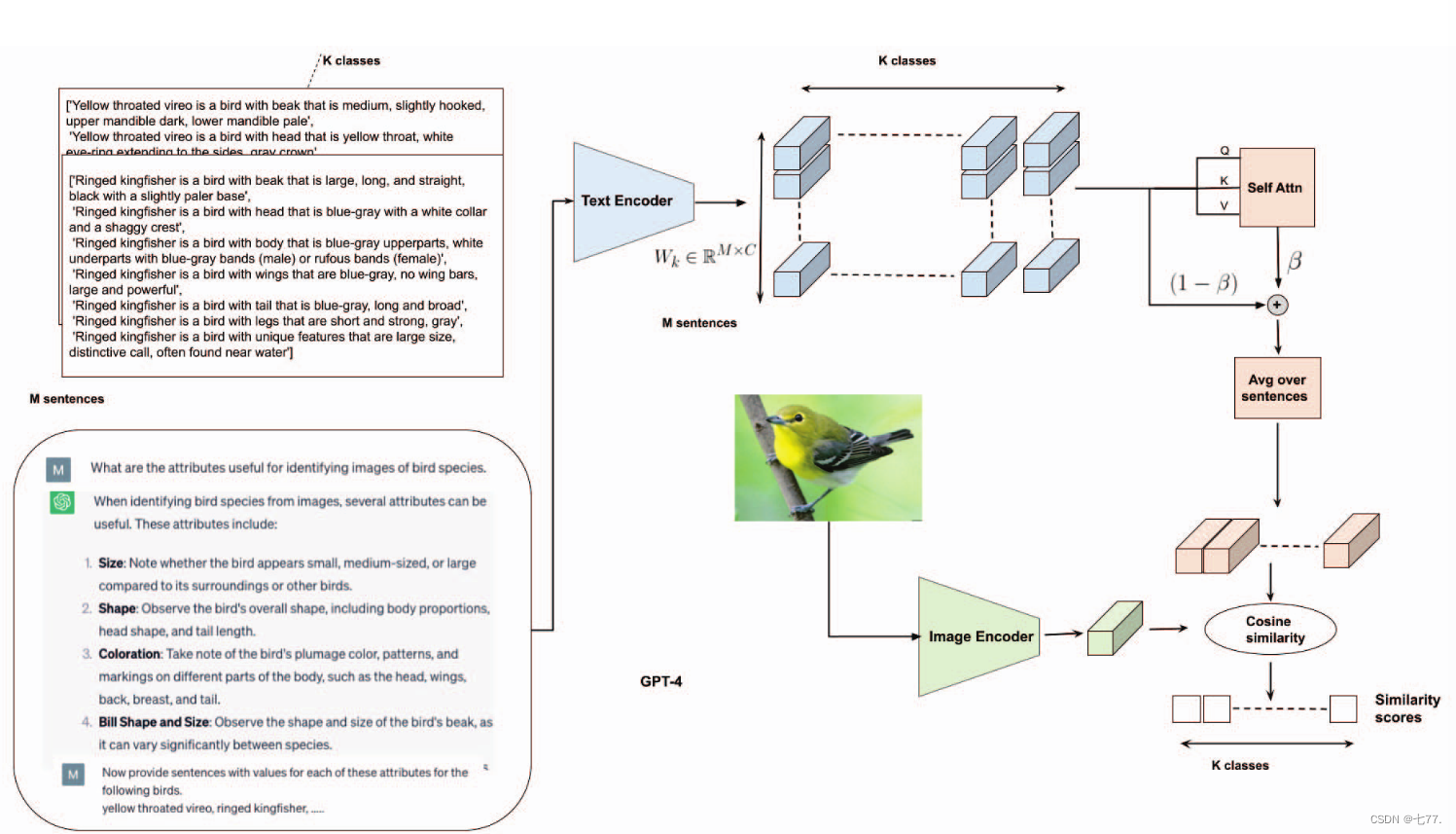
K 类鸟类
[黄喉莺是一种中等大小的鸟,喙略呈钩状,上颚深色而下颚浅色。黄喉莺的头部特征是黄色喉咙,白色,眼环延伸至两侧至头顶。]
[环颈翠鸟是一种大型、长腿、直颈的鸟,喙大、长且直,黑色,基部稍浅。环颈翠鸟的头部特征是蓝灰色,带有白色领圈和蓬松的冠羽。环颈翠鸟的身体特征是蓝灰色的上半部分,白色的下半部分带有蓝灰色条纹(雄性)或红褐色条纹(雌性)。环颈翠鸟的翅膀是蓝灰色,没有翅带,大而有力。环颈翠鸟的尾巴是蓝灰色,长而宽。环颈翠鸟的腿是短而强壮的灰色。环颈翠鸟的独特特征是体型大,叫声独特,常在水边被发现。]
M句(M sentences)
哪些属性对于识别鸟类物种的图像是有用的?
在通过图像识别鸟类物种时,有几个属性可能是有用的。这些属性包括:
- 大小:注意鸟类相对于其周围环境或其他鸟类的大小,是看起来小、中等大小还是大。
- 形状:观察鸟类的整体形状,包括身体比例、头部形状和尾巴长度。
- 颜色:注意鸟类羽毛的颜色、图案和身体不同部位的标记,如头部、翅膀、背部、胸部和尾巴。
- 喙的形状和大小:观察鸟类喙的形状和大小,因为不同物种之间的喙可以有很大的差异。
现在,为以下鸟类提供具有这些属性值的句子:黄喉莺、环颈翠鸟……


表1的最后一行显示,GPT-4生成的视觉描述句子的性能与由领域专家标注的类属性向量生成的句子性能相似。我们对基准套件中的所有数据集都采用了相同的简单策略,以可扩展和灵活的方式生成视觉描述性句子,并使用这些句子来构建提示集成。
3.3. 用于视觉句子的简单的少样本适配器
我们设计了一个简单的适配器,该适配器可以利用视觉描述文本(VDT)信息来改善CLIP模型在目标数据集上的少样本迁移能力。类似于CLIP-A文本适配器,我们在词编码器的输出后附加了一组可学习的参数,并使用交叉熵损失来训练这个适配器。我们的CLIPA-self使用了一个自注意力层,该层对每个类别的不同句子嵌入进行注意力处理,并对输出进行平均,以得到最终的分类向量。
给定我们为K个类中的每个类别都生成了M个由GPT生成的句子,我们通过将每个句子附加到提示模板中(如
)来构造M个提示,并将它们通过CLIP的词编码器进行传递,以得到Wsent ∈ RD×M×K。这里,Wsent 是一个三维张量,其中D是词嵌入的维度,M是每个类别中句子的数量,K是类别的总数。
对于自注意力适配器,我们在所有视觉描述性句子上应用标准的自注意力机制[28],以便在训练过程中学习选择和聚合与识别每个类别最相关的视觉句子。与之前一样,我们首先获得所有句子的分类向量Ws∈RK×M×D,并将它们作为键、查询和值传递给自注意力模块Bself,然后对输出标记进行平均以得到最终的分类向量W。在这里,注意力是应用于M个不同的视觉描述性句子上的。
(4) 平均每个类别的所有视觉描述性句子的原始分类向量Ws:
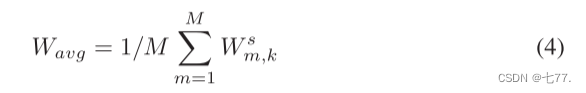
(5) 应用自注意力模块Bself到每个类别的所有视觉描述性句子的分类向量上,并输出新的加权向量
这里假设对M个视觉描述性句子进行自注意力计算,每个句子都有一个对应的分类向量Wsm,k。
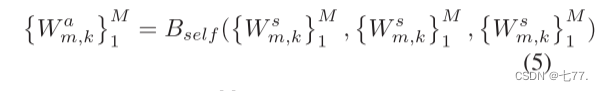
(6) 对每个类别的加权向量进行平均,得到平均后的向量Wa−mean: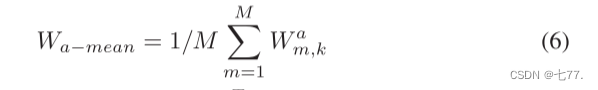
(7) 最终的分类向量W是平均后的向量Wa−mean和原始平均向量Wavg的加权和,其中β是一个超参数:
注意:这里Wa−meanT表示对Wa−mean进行转置,因为可能需要将维度与Wavg对齐,以便能够相加。
我们最终得到了新的适配器分类器权重W∈RD×K,这些权重已经过调整,以关注任何给定数据集中M个视觉描述性句子中最具视觉区分性的信息。我们利用这些权重来计算概率,并通过选择概率最高的类别来预测图像的类别。
在少样本训练中,仅使用交叉熵损失来训练适配器网络Bself的权重。
4. 实验
在少量的训练中,自注意机制学会了从视觉描述性文本集中选择最相关的视觉句子,并帮助产生可泛化的分类器。
对于斯坦福汽车和FGVC来说,有趣的是,配色方案是最少使用的属性之一,因为很难从颜色或涂装中识别汽车或飞机。对于UCF-101来说,涉及的力等信息或动作的速度和运动范围等时间信息不太可能被编码到图像中,因此不被注意机制选择。关于动作的主体和客体的信息,如人的姿势,对客体的描述,以及客体之间的互动,在图像中是可见的,因此受到注意机制的高度重视。
5. 结论
在这项工作中,我们展示了使用视觉描述性文本(VDT)信息可以提高CLIP在0样本学习域迁移任务上的性能,相较于非视觉信息和默认提示。我们通过在12个基准数据集上改进0样本学习域迁移性能,证明了GPT-4是VDT信息的准确且灵活的来源。我们的少样本适配器CLIP-A-self学会了从GPT生成的集合中选择最佳的VDT信息,并在Base-to-New设置中提高了少样本域迁移性能,即使生成的文本质量下降也是如此。我们发布了所有12个数据集的提示和VDT信息,以促进在利用大型语言模型(LLMs)学习多模态适配器以用于基础模型这一富有成果的研究方向上的进一步研究。
读后总结
出发点:精心设计的提示和提示集成对于提高零样本学习分类的准确率很重要。
创新点1:通过GPT-4列出k个类别图像的所有属性,再让GPT-4以句子的形式为k个类别的所有属性生成句子,作为clip的文本编码器的输入。
创新点2:提出一种简单的少样本适配器,其中,通过对k个类别的所有句子进行自注意力机制计算(自注意力机制可以从视觉描述性文本集中选择最相关的视觉句子),然后将自注意力得到的向量和原始向量相加后进行平均计算得到文本向量。
这篇关于Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









