本文主要是介绍EVA-CLIP:在规模上改进CLIP的训练技术,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
对比性语言-图像预训练,简称CLIP,因其在各种场景中的潜力而备受关注。在本文中,我们提出了EVA-CLIP,一系列模型,这些模型显著提高了CLIP训练的效率和有效性。我们的方法结合了新的表示学习、优化和增强技术,使得EVA-CLIP在参数数量相同的情况下,与之前的CLIP模型相比,取得了更优的性能,但训练成本却显著降低。值得注意的是,我们最大的50亿参数的EVA-02-CLIP-E/14+模型,仅通过90亿个样本的训练,就在ImageNet-1K验证集上实现了**82.0%的零次学习(zero-shot)top1的准确率。一个参数更小的EVA-02CLIP-L/14+模型,仅包含4.3亿参数和60亿个样本,也在ImageNet-1K验证集上达到了80.4%**的零次学习top1的准确率。为了促进开放访问和开放研究,我们将完整的EVA-CLIP套件发布给社区。
1. 引言
CLIP(对比性语言-图像预训练)是一种强大的视觉-语言基础模型,它利用大规模数据集通过对比性图像-文本预训练来连接视觉和语言,从而学习丰富的视觉表示。CLIP模型表现出强大的零次学习迁移能力[39],并且有可能增强多模态和单模态视觉任务,如AI生成内容应用[41, 20, 32, 45]。尽管CLIP模型具有重要意义,但由于其高昂的计算成本和在扩大规模时出现的训练不稳定问题,训练CLIP模型仍然是一个不可避免的挑战。

在本文中,我们提出了EVA-CLIP,一系列模型,为训练CLIP模型提供了一个可行、高效且有效的解决方案。我们的方法采用了几种技术,这些技术可以显著减少训练成本,稳定训练过程并提高零次学习性能,包括使用预训练的EVA[20,19]表示来初始化CLIP,使用LAMB[52]优化器,随机丢弃输入标记[33],以及一个名为flash attention的加速技巧[15]。通过这些技术,我们能够在降低计算成本的同时,在大规模上极大地稳定CLIP模型的训练,并在广泛的零次学习基准测试中,以比从头开始训练的对等模型更少的样本量取得更好的性能。我们最大的50亿参数的EVA02-CLIP-E/14+模型,仅通过90亿个样本的训练,就在ImageNet-1K验证集上实现了 82.0 % 82.0\% 82.0%的零次学习顶一准确率。一个参数更小的EVA-02-CLIP-L/14+模型,仅包含4.3亿参数和60亿个样本,也在ImageNet-1K验证集上达到了 80.4 % 80.4\% 80.4%的零次学习顶一准确率。
2. 方法
训练CLIP[39]模型非常困难且成本高昂。由于需要较大的批次大小以及扩大CLIP模型规模,这可能导致显著的计算资源需求,甚至训练不稳定的问题。幸运的是,EVA-CLIP提供了一个高效且有效的解决方案,它在显著降低计算成本的同时,在广泛的基准测试中实现了卓越的零次学习性能。
更好的初始化。为了改进特征表示并加快CLIP模型的收敛速度,我们采用了预训练的EVA[20,19]模型,该模型结合了图像-文本对比学习的高级语义与掩码图像建模中的几何和结构捕获。我们使用预训练的EVA权重来初始化EVA-CLIP的图像编码器。我们的实证研究表明,预训练的EVA模型不仅帮助EVA-CLIP在各种零次学习基准测试中取得了优越的性能,还加快了训练过程并使其更加稳定。
优化器。我们使用LAMB[52]优化器来训练我们的EVA-CLIP模型。LAMB优化器是专门为大规模批次训练设计的,其自适应元素更新和分层学习率提高了训练效率并加速了收敛速度。鉴于训练CLIP模型所使用的异常大的批次大小(原始CLIP模型使用批次大小为32,768,而一些开源的CLIP模型甚至使用超过100k的极大批次大小),EVA-CLIP表明LAMB优化器是训练大规模CLIP模型的首选优化器。
FLIP[33]在大规模设置中展示了有前景的结果。在这项工作中,我们利用FLIP来提高训练CLIP模型的时间效率。具体地说,我们在训练过程中随机屏蔽50%的图像标记,这将时间复杂度显著降低了一半。这种方法还允许在不增加任何内存成本的情况下,将批次大小增加两倍。
3. 实验
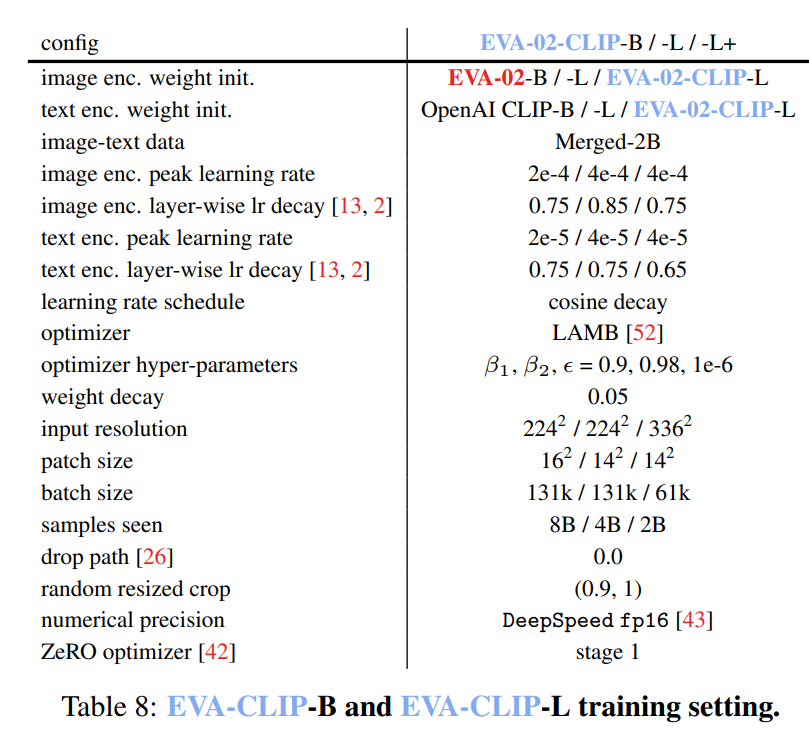
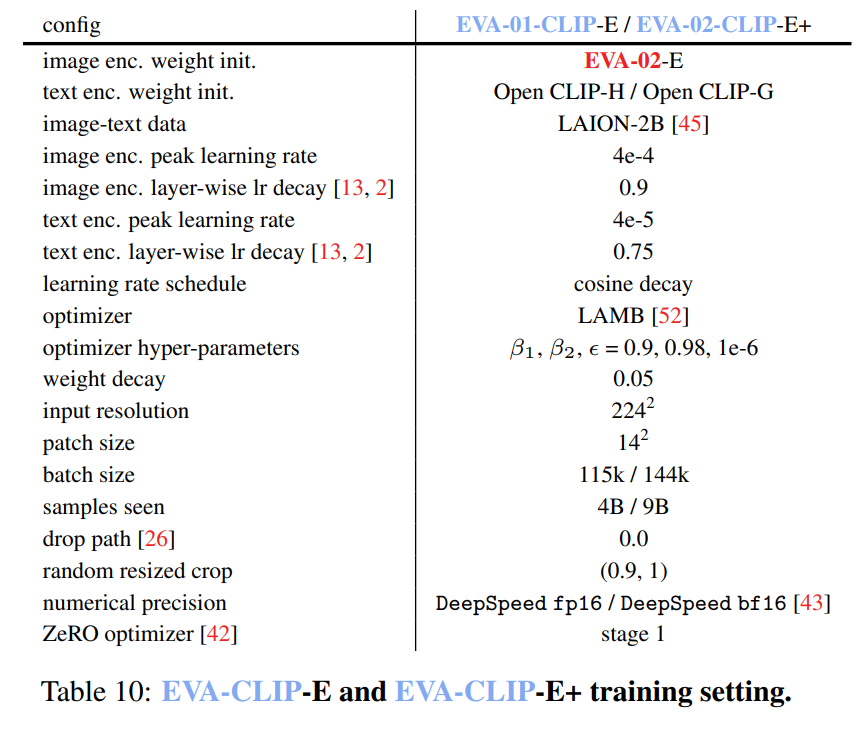
设置。在我们的实验中,我们使用EVA[20,19]的预训练权重来初始化视觉编码器,并使用OpenAI CLIP[39]或OpenCLIP[27]的预训练权重来初始化文本编码器。具体来说,EVA-01-CLIP的视觉编码器使用EVA-01[20]的预训练权重进行初始化,而EVA-02-CLIP的视觉编码器则使用EVA-02[19]的预训练权重进行初始化。我们采用LAMB优化器,其中 β 1 = 0.9 \beta_{1}=0.9 β1=0.9, β 2 = 0.98 \beta_{2}=0.98 β2=0.98,权重衰减为0.05。我们对视觉编码器和文本编码器应用了不同的学习率和层衰减率,以确保最佳训练效果。例如,在EVA-01-CLIP-g的前2000个预热步骤中,我们将视觉编码器的学习率设置为 2 e − 4 2 \mathrm{e}-4 2e−4,文本编码器的学习率设置为 2 e − 5 2 \mathrm{e}-5 2e−5。之后,我们在剩余的训练步骤中将学习率线性衰减至0。为了进一步改进训练过程,我们使用了DeepSpeed优化库[43],配合ZeRO一阶优化器[40]、梯度检查点[10]和Flash Attention[15]来节省内存并加速训练过程。我们发现,在EVA-01-CLIP-g的训练过程中,使用 f p 16 \mathrm{fp}16 fp16精度和动态损失缩放足够稳定,而为了稳定EVA-02-CLIP-E+的训练过程,则必须使用bfloat16格式。
为了构建我们的训练数据集Merged-2B,我们将LAION-2B[45]数据集中的16亿个样本与COYO-700M[6]数据集中的4亿个样本合并。


系统级比较。我们在表1中展示了CLIP模型配置以及ImageNet变体和ObjectNet上的零次学习准确率。EVA-02-CLIP-E/14+在所有6个基准测试中平均达到了最高的零次学习top-1准确率 80.9 % 80.9\% 80.9%,并且性能下降最小(top-1准确率差距为 1.1 % 1.1\% 1.1%)。值得注意的是,这一结果在ImageNet上比之前的最大且最好的开源模型OpenCLIP-G/14[1]高出了 1.9 % 1.9\% 1.9%,并且在6个基准测试的平均准确率上高出了 4.7 % 4.7\% 4.7%。令人瞩目的是,通过这些强大的技术,大型EVA-02-CLIP-L模型在ImageNet上的零次学习top-1准确率甚至可以达到 80.4 % 80.4\% 80.4%,仅使用大约 ∼ 1 / 6 \sim 1/6 ∼1/6的参数和 ∼ 1 / 6 \sim 1/6 ∼1/6的图像-文本训练样本就超过了OpenCLIP G/14。

在表2中,我们进一步展示了我们的方法在所有27个零次学习图像分类基准测试上的有效性和鲁棒性。我们最大的EVA-02-CLIP-E/14+模型在所有27个基准测试上平均达到了 77.5 % 77.5\% 77.5%的准确率。值得注意的是,我们的EVA02-CLIP-L/14+模型,其模型大小仅为大约一半,图像-文本对数量也仅为大约五分之一,但在平均准确率上比OpenCLIP-H/14提高了1.2个百分点。

对于视频分类,我们仅从每个视频中采样一个中心帧,将其转化为图像分类任务。按照常规设置,我们报告了UCF-101[47]的top-1准确率,以及Kinetics-400[9]、Kinetics-600[7]和Kinetics-700[8]的top-1和top-5准确率的平均值。在表3中,我们展示了EVA-CLIP在零次学习视频识别基准测试中也非常有效。

表4报告了在Flickr30K[53]和COCO[34]上的零次学习图像和文本检索结果。EVA-CLIP在基础模型和大模型尺寸上都优于所有竞争对手。虽然EVA02-CLIP-E/14的零次学习检索性能略低于OpenCLIP-G/14,但结果仍然具有竞争力。我们推测主要原因是检索任务更多地依赖于文本编码器的容量和训练样本的数量,相比之下,EVA-02CLIP-E/14的文本编码器容量较小,训练样本数量也少于OpenCLIP-G/14。为此,我们使用具有更大容量文本编码器和更多训练样本的EVA-02-CLIP-E/14+进行了训练。结果表明,这个改进后的模型可以显著提高检索性能,并在零次学习文本检索任务上超越OpenCLIP-G/14。
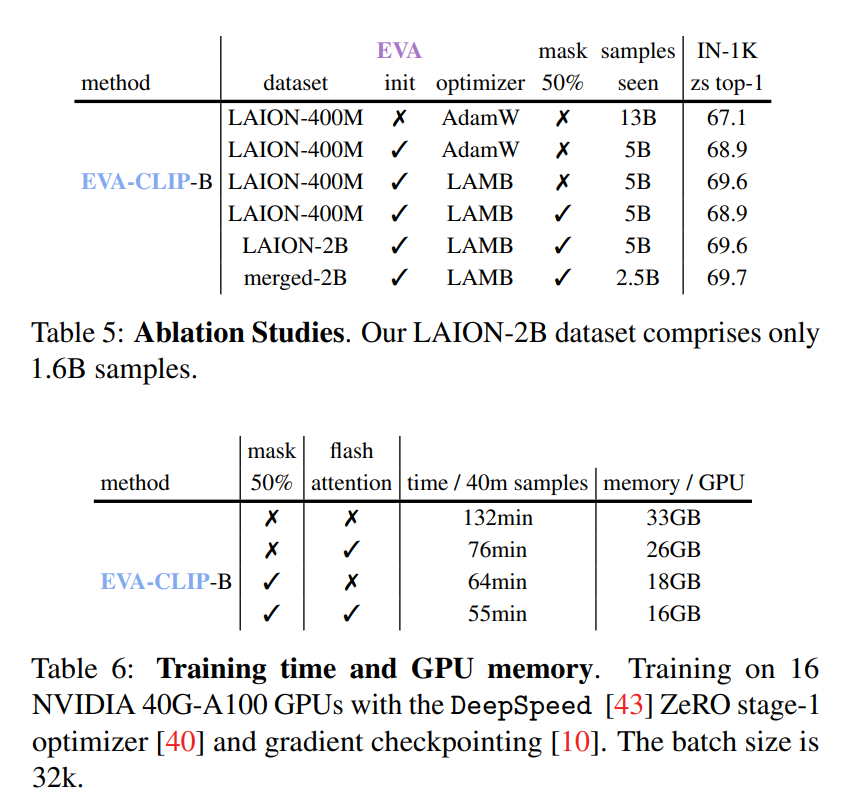
消融研究。我们首先在表5中对EVA-CLIP的设计进行了消融实验。图像编码器是ViT-B/16[17]模型,文本编码器是CLIP-B-16。我们使用32k的批大小进行了实验,并在ImageNet-1K验证集上评估了零次学习准确率。值得注意的是,我们使用的训练计划比最终模型更短。
我们在LAION-400M[46]数据集上使用AdamW[35]优化器训练了我们的模型。与从头开始训练相比,使用EVA初始化在ImageNet上的零次学习top-1准确率提高了 1.8 % 1.8\% 1.8%,而仅使用了大约一半的可见样本。
此外,我们在LAION-400M数据集上使用LAMB优化器代替AdamW与EVA初始化进行了实验。这导致在ImageNet上的零次学习top-1准确率提高了 0.7 % 0.7\% 0.7%,而使用了相同的可见样本。当应用 50 % 50\% 50%的掩码时,准确率下降了 0.7 % 0.7\% 0.7%,但训练速度提高了 2 × 2\times 2×。这些结果突出了LAMB优化器在训练高性能模型中的重要性,以及在不显著降低准确率的情况下通过掩码图像标记来加快训练速度的策略。
我们还使用LAION-2B数据集进行了实验,结合了EVA初始化、LAMB优化器和 50 % 50\% 50%的掩码,这相对于LAION-400M数据集提高了 0.7 % 0.7\% 0.7%的准确率。当使用合并后的2B数据集时,仅需要一半的样本就能达到相同的top-1准确率。这证明了数据集大小的重要性以及通过合并两个数据集实现的显著收敛速度。
计算成本。在表6中,我们展示了我们的实现所需的内存和时间成本。如表所示,掩码 50 % 50\% 50%的图像标记可以加速训练时间达 2 × 2\times 2×,而使用Flash Attention可以进一步减少额外的 15 % 15\% 15%训练时间。
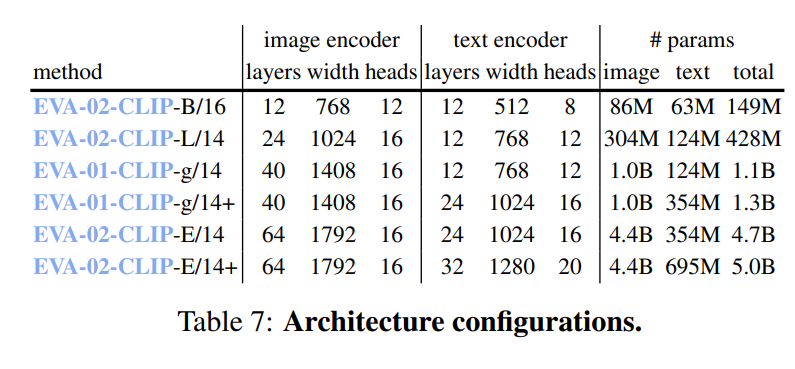
使用所有这些技术,我们可以在比其他CLIP模型更低的预算下训练EVA-CLIP。例如,EVA-CLIP-B/16可以在批大小为 32 k 32\mathrm{k} 32k的情况下进行训练,并使用16个NVIDIA 40GB-A100 GPU在300小时内收敛。类似地,十亿规模的EVA CLIP g / 14 \mathrm{g} / 14 g/14可以在批大小为 65 k 65\mathrm{k} 65k的情况下进行训练,并使用64个NVIDIA 40G-A100 GPU在不到25天的时间内训练12B样本。这些结果展示了我们的方法在保持训练时间和GPU内存利用率之间最优平衡的同时,实现最先进结果的可扩展性和有效性。

这篇关于EVA-CLIP:在规模上改进CLIP的训练技术的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






