本文主要是介绍Leveraging Knowledge Bases in LSTMs for Improving Machine Reading,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《Leveraging Knowledge Bases in LSTMs for Improving Machine Reading》
这篇文章是发表在2017年ACL上的,主要是聚焦于外部知识改善LSTM,运用在实体抽取和事件抽取任务。在ACE2005的数据集上得到了SOTA效果。
首先介绍这篇文章的两个知识库,一个是WordNet一个是NELL。
- Word net是人工创造的一个词典,里面含有大量的同义词,以及他们之间的概念关系(上位词hypernym,part_of关系)。
比如(location, hypernym of, city),(door, has part, lock)
头实体和尾实体都是Wordnet中的同义词
- NELL,是自动构建的,基于网页的知识库,存储了实体之间的关系。
比如(New York, located in, United States) , (New York, is a, city)
头实体和尾实体都是一个真实世界的名词短语实体,尾实体也可以是一个概念分类。
接下来分以下四部分介绍:
- Motivation
- Model
- Experiment
- Discussion
1、Motivation
- 传统的方法将知识表示成离散的特征,这些特征的泛化性能很差,而且为了获得好的效果还需要特定任务的特征工程。
- 在不同的文本之间,知识的使用也是不同的,比如说一词多义, Clinton,既可以表示一个人,也可以表示一个城镇。如果加入无关上下文的知识,可能会误导模型。
针对这两个问题,该篇论文提出kblstm,首先利用这个连续的知识的表示去加强循环神经网络的学习能力。
而且为了去有效的整合背景知识和当前文本,还提出了使用一种带有sentinel(哨兵)的attention机制,可以动态的决定是否要引入背景知识并且哪一条背景知识是有效的
2、Model
2.1 overview
模型这一部分主要是把外部知识引入到双向循环神经网络当中(2.2)。主要是在隐藏状态,加入外部信息。外部信息是通过连续编码,使用konwledge embedding的方法(2.3)

2.2 Knowledge-aware Bidirectional LSTMs
首先学习到知识库里面的concepts的向量。然后去检索当前词的相关候选concepts V ( x t ) V(x_t) V(xt),并且把它们整合到状态向量,得到 m t m_t mt ,去做预测。
核心是Knowledge model,对每一个候选去计算一个双线性,反应了concept 和当前隐状态的关系。
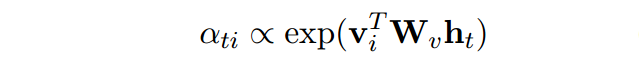
有时候一些kb可能会误导模型,为了解决这个问题,引入一个知识哨兵。两个作用:
- records the information of the current context
- use a mixture model to allow for better tradeoff between the impact of background knowledge and information from the context.
St计算方式如下:
首先,用前一时刻的状态和当前输入,过一个门函数,可以把这个门看成输出门,决定我要输出多少的信息,然后和状态向量进行计算。
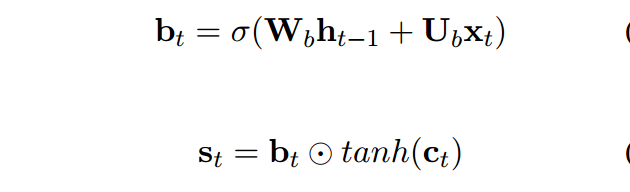
接着和神经网络当中的状态进行双向性计算得到打分belta。
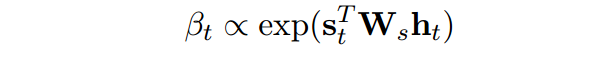
最后使用混合模型得到表示:
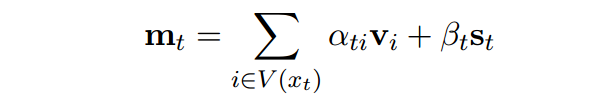
注意这个限制条件:
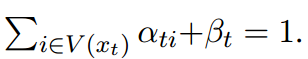
之前这个地方其实不是很理解。文章说的是为了权衡背景知识和来自于上下文的信息。但是最后输出的时候,只是做了一个简单的向量加和。而且st和前一部分的vt是两部分独立的。St并没有对前面的这些知识起到一个过滤或者说是什么的作用。所以前面的motivation说,st这个哨兵向量是为了决定是否要引入外部知识。就很迷。
解答:就是为了权衡背景知识和来自于上下文的信息。mt的来源有两部分,一部分是融入了背景知识的隐向量,一部分是只有当前信息的哨兵向量。
st这个哨兵向量是为了决定是否要引入外部知识,因为有限制条件,加和为1。所以当belta很大的时候,也就是我更加关注于上下文信息,忽略掉知识信息,那么可以用来解答motivation。zhi’q
2.3 Embedding Knowledge Base Concepts
对于wordnet,把当前词的同义词作为候选concept。
对于Nell,我们搜索当前词的实体和相关的概念分类(concept categories)作为候选concept。
使用知识图谱embedding方法去学习候选的表示。我们把一个concept定义成一个三元组,用一个打分函数去衡量三元组的相关性。打分函数主要是使用双线性函数。头实体和尾实体表示他们的向量。Mr是一个关系确定的embedding矩阵。
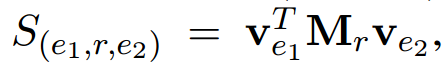
using the max-margin ranking objective:
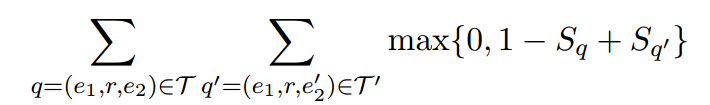
对于word net我们使用预处理的数据[1]去训练。包括15万的三元组,4万的同义词和18个关系。对于NELL,使用其子集去进行训练,过滤掉了一些置信度少于0.9的名词短语。最终有18万的名词短语和258个概念分类。
3、Experiment
做了两个实验,第1个实验是实体抽取。第2个实验是事件抽取。
3.1 实体抽取
1、实体抽取结果

BiLSTM-Fea:a BiLSTM network that combines its hidden state vector with discrete KB features
2、我们设置了不同的KB,去验证外部数据的有效性。

3.1 事件抽取
1、实验结果

The first block in Table 5 shows the results of the feature-based linear models;
The second block shows the previously reported results for the neural models;
The third block shows the results of our models
4、Discussion
文章提出了两点,第1点是在循环神经网络当中融入了外部知识表示,第2点是引入了一个哨兵向量,能够去决定是否需要使用外部知识,而且也能够在用外部知识和用上下信息做权衡。
[1]Antoine Bordes, Nicolas Usunier, Alberto GarciaDuran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multirelational data. In Advances in Neural Information Processing Systems (NIPS)
这篇关于Leveraging Knowledge Bases in LSTMs for Improving Machine Reading的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!