knowledge专题

知识图谱(knowledge graph)——概述
知识图谱总结 概念技术链概括通用知识图谱和垂直领域知识图谱国内外开放知识图谱 技术链详解知识获取知识融合知识表示知识推理知识存储 知识图谱构建流程其他挑战跨语言知识抽取跨语言知识链接 思考参考 概念 知识图谱(Knowledge Graph)以结构化的形式描述客观世界中概念、实体及其关系。是融合了认知计算、知识表示与推理、信息检索与抽取、自然语言处理、Web技术、机器学习与大数据

知识图谱(knowledge graph)——RDF(Resource Description Framework)
RDF的基本单元是三元组(triple) 每个三元组是(主语 谓语 宾语) 这样的元组tuple。主谓宾的取值称为"资源"(Resource, 也就是RDF里的R) 资源可以是一个网址(URI),一个字符串或数 字(严格来讲都是带类型的字符串,称为 literal),或者一个“空节点”(blank node)。 有两种特殊类型的资源。rdfs:Class代表类。 rdf:Property代
知识图谱 Knowledge Graph
笔记链接: 【有道云笔记】Knowledge Graphhttps://note.youdao.com/s/KzaCxBPs无须登录即可直接查看,用于个人学习。 参考知乎用户@非洲的兔子

优化数据以提升大模型RAG性能思路:Meta Knowledge for RAG的一个实现思路
传统的RAG系统通过检索然后阅读框架来增强LLMs,但存在一些挑战,如知识库文档的噪声、缺乏人工标注信息、长文档的编码问题以及用户查询的模糊性。 因此可以采用数据为中心的增强方法,我们可以看看最近的一个工作。 一、Meta Knowledge for RAG 最近的工作,《Meta Knowledge for Retrieval Augmented Large Language Models

little knowledge及errno的一些错误定义
select()机制中提供一fd_set的数据结构,实际上是一long类型的数组,每一个数组元素都能与一打开的文件句柄(不管是socket句柄,还是其他文件或命名管道或设备句柄)建立联系,建立联系的工作由程序员完成,当调用select()时,由内核根据IO状态修改fd_set的内容,由此来通知执行了select()的进程哪一socket或文件发生了可读或可写事件。 LINUX 下宏定义

【888题竞赛篇】第六题,2023ICPC济南-来自知识的礼物(Gifts from Knowledge)
这里写自定义目录标题 更多精彩内容256题算法特训课,帮你斩获大厂60W年薪offer 原题2023ICPC济南真题来自知识的礼物B站动画详解 问题分析思路分析算法实现代码详解标准代码程序C++代码Java代码Python代码Javascript代码 复杂度分析时间复杂度空间复杂度 总结 更多精彩内容 这里是带你游历编程世界的Dashcoding编程社,我是Dash/北航硕士/

VCTP(Visual Chain-of-Thought Prompting for Knowledge-Based Visual Reasoning)论文
目录 摘要介绍相关工作方法总体模型细节 实验 摘要 知识型视觉推理仍然是一个艰巨的任务,因为它不仅要求机器从视觉场景中解释概念和关系,而且还需要将它们与外部世界知识联系起来,对开放世界问题进行推理链。然而,以前的工作将视觉感知和基于语言的推理视为两个独立的模块,在推理的所有阶段都没有同时关注这两个模块。为此,我们提出了一种知识型推理的视觉思维链提示(VCTP),它涉及视觉内容与自

Similarity-Preserving Knowledge Distillation
Motivation 下图可以发现,语义相似的输入会产生相似的激活。这个非常好理解,这个C维的特征向量可以代表该输入的信息 因此本文根据该观察提出了一个新的蒸馏loss,即一对输入送到teacher中产生的特征向量很相似,那么送到student中产生的特征向量也应该很相似,反义不相似的话同样在student也应该不相似。 该loss被称为Similarity-preserving,这样stu

Revisit Knowledge Distillation: a Teacher-free Framework
Observations 通过几组实验观察到 反转Knowledge Distillation(KD)即利用student来guide teacher的话,teacher的性能依然可以得到提升用一个比student还差的teacher来guide student的话,student的性能依然可以得到提升 因此作者得到以下观点 KD只是一种可学习的label smoothing regula

Large-Scale Relation Learning for Question Answering over Knowledge Bases with Pre-trained Langu论文笔记
文章目录 一. 简介1.知识库问答(KBQA)介绍2.知识库问答(KBQA)的主要挑战3.以往方案4.本文方法 二. 方法问题定义:BERT for KBQA关系学习(Relation Learning)的辅助任务 三. 实验1. 数据集2. Baselines3. Metrics4.Main Results 一. 简介 1.知识库问答(KBQA)介绍 知识库问答(KBQA
knowLedge-无关系组件间方法的调用(创建新的 Vue 实例来作为事件总线(Event Bus)方法实现)
1.前言 在vue中两个组件无关系(非父子,兄弟即非直接关系),要实现一个组件对另一个组件方法调用以及数据通信。vue本身没有直接提供非关系组件间通信的内置机制 。 使用全局事件总线可以用于不同组件间监听与触发事件。注意事件监听器的清理避免内存泄露。 2.实践 2.1创建event-bus.js 首先,创建一个单独的 Vue 实例文件(比如 even

加密学中的零知识证明(Zero-Knowledge Proof, ZKP)到底是什么?
加密学中的零知识证明(Zero-Knowledge Proof, ZKP)到底是什么? 引言 在加密学的应用中,零知识证明(Zero-Knowledge Proof, ZKP)无疑是一颗璀璨的明星。它不仅挑战了我们对信息验证的传统认知,更在保护隐私的同时确保了数据的真实性,为数字货币、身份验证、安全通信等多个领域带来了革命性的变革。本文将深入探讨零知识证明的原理、关键技术、应用场景以及未来
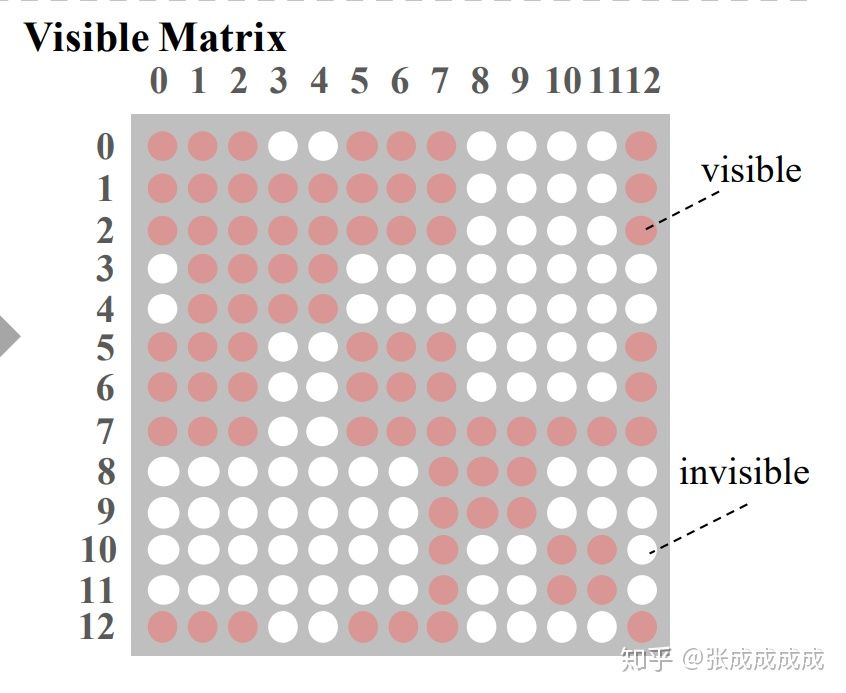
浅谈 Knowledge-Injected BERTs
1. 序 在当下的 NLP 领域,BERT是一个绕不过的话题。 自从2018年底横空出世以来,它以势不可挡的态势横扫了整个GLUE榜单,将基准推进到80%的水平线,在SQuAD1.1中全部指标超越人类水平。在使用其预训练的参数后,几乎所有的下游任务都获得了相当的增益(当然,大量参数随之带来的也有运算效率的下降),自此开创了大语料无监督任务的预训练模型时代,自成一个山门,史称Bertology。

【Car Guide.2】Basic Knowledge
文章目录 【History】【投诉榜】【油 VS 电】【三元锂 vs 磷酸铁锂】【本田、丰田、大众】飞度 【杂谈】 【History】 法国,标志,雪铁龙 美国,通用集团,有别克(GL8),凯迪拉克,雪佛兰,福特 福特旗下,曾有捷豹,路虎,阿斯顿马丁,沃尔沃,四大天王 捷克,斯柯达(大众) 意大利,布加迪(跑车,最快,大众) 英国,阿斯顿马丁 英国,宾利(被劳斯莱

Locality-aware subgraphs for inductive link prediction in knowledge graphs
Locality-aware subgraphs for inductive link prediction in knowledge graphs a b s t r a c t 最近的知识图(KG)归纳推理方法将链接预测问题转化为图分类任务。 他们首先根据目标实体的 k 跳邻域提取每个目标链接周围的子图,使用图神经网络 (GNN) 对子图进行编码,然后学习将子图结构模式映射到链接存在的函
创新5 – 如何激励知识工作者 (knowledge workers)
先考大家一个IQ问题: 你坐在木墙旁边的一张桌子旁,实验者给你如下所示的材料:一支蜡烛,一些图钉和一些火柴。 请您利用上面的东西,把蜡烛接连到墙上,但不能让融化的蜡滴到桌子上。想一下你该如何解决这个问题? 直接用图钉把蜡烛钉在墙上? 点燃一根火柴,融化蜡烛的一边,然后试着把它粘在墙上? 请拿一张白纸,把你的答案画出来,也算算总共花多少分钟? =
论文阅读——Bayesian Knowledge Fusion(贝叶斯知识融合)
该篇论文解决了不确定环境中的信息融合问题。想象一下,有多位专家针对同一情况构建概率模型,我们希望汇总他们提供的信息。直接合并每个信息可能会遇到几个问题。例如,专家们可能不同意某个事件发生的概率,或者他们可能不同意两个事件之间因果关系的方向(例如,一个人认为 A 导致 B,而另一个人认为 B 导致 A)。他们甚至可能不同意概率网络中一组变量之间的整个依赖结构。文章将概率模型表示为贝叶
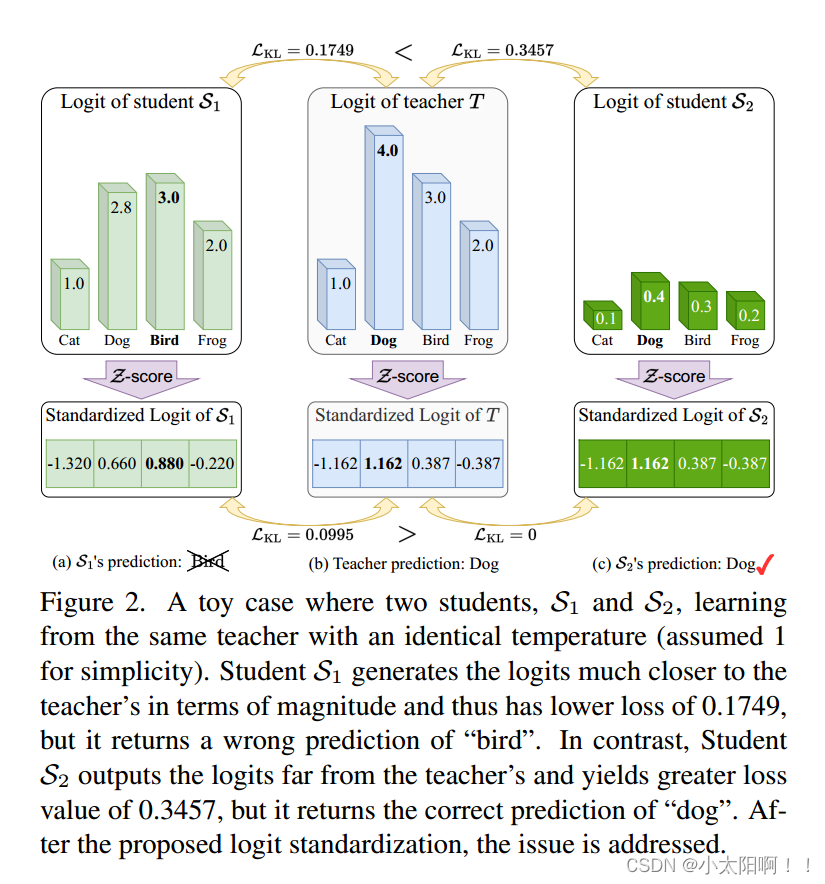
Logit Standardization in Knowledge Distillation 知识蒸馏中的logit标准化
摘要 知识蒸馏涉及使用基于共享温度的softmax函数将软标签从教师转移到学生。然而,教师和学生之间共享温度的假设意味着他们的logits在logit范围和方差方面必须精确匹配。这种副作用限制了学生的表现,考虑到他们之间的能力差异,以及教师天生的logit关系足以让学生学习。为了解决这个问题,我们建议将温度设置为logit的加权标准差,并在应用softmax和KL散度之前进行logit标准化的即

知识驱动对话-Learning to Select Knowledge for Response Generation in Dialog Systems-阅读笔记
今日看了一篇文章《Learning to Select Knowledge for Response Generation in Dialog Systems》,以知识信息、对话目标、对话历史信息为基础,进行端到端的对话语句生成。期间做了一些笔记,还有个人想法。大家一起进步! 时刻记着自己要成为什么样的人!
EMNLP2019 | Knowledge-Aware Graph Networks
论文标题:KagNet: Knowledge-Aware Graph Networks for Commonsense Reasoning KagNet: Knowledge-Aware Graph Networks for Commonsense Reasoningarxiv.org Authors: Bill Yuchen Lin, Xinyue Chen, Jamin Chen
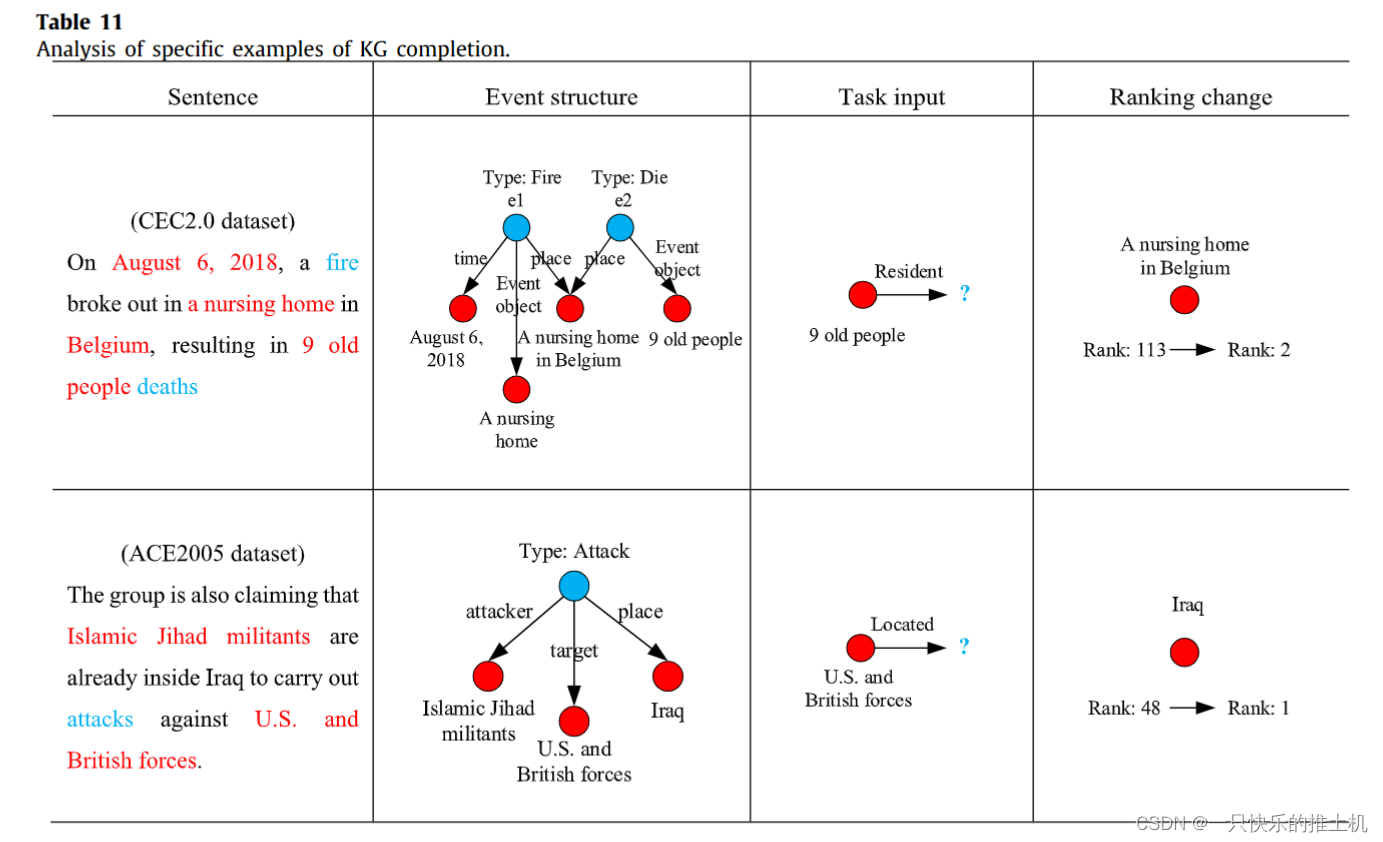
事件知识图谱 - EventKGE_Event knowledge graph embedding with event causal transfer
EventKGE: Event knowledge graph embedding with event causal transfer 作者:Daiyi Li(南航) 来源:2023 Knowledge-Based Systems(中科院一区,影响因子8.8) 论文:[ScienceDirect] 代码:[暂无] 引用数:2 参考:[] 关键词:事件因果转移、事件知识图谱 数据集
Notes for the missing semester. Useful and basic knowledge about Linux.
The Shell Contents The first course is to introduce some simple commands. I’ll list some commands that I’m not familiar with: # --silent means don't give log info,# --head means we only want the

Overview of knowledge reasoning for knowledge graph
摘要 知识图是影响知识表示的大规模语义网络。从现有数据中挖掘隐藏知识,包括三元组知识推理,是知识图的主要目标。随着神经网络(NN)和深度学习(DL)的发展,三元组知识推理的可解释性逐渐降低;此外,机器学习的不是实际的推理,而是数字推理的捷径。为了解决这个问题,需要在知识图中引入更多的背景知识:因果图可以为推理提供有价值的因果逻辑知识;时间四重组可以提供基本的时间分布细节;而常识性图表可以提供
Semantic Web and Peer-to-Peer : Decentralized Management and Exchange of Knowledge and Information
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Just like the industrial society of the last century depended on natural resources, todays society depend

Object-Oriented Design Knowledge: Principles, Heuristics And Best Practices
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp In order to properly understand a field, a researcher has to first understand the accumulated knowledge
High Performance Web Sites: Essential Knowledge for Front-End Engineers [ILLUSTRATED]
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Want your web site to display more quickly? This book presents 14 specific rules that will cut 25% to 5