本文主要是介绍Machine Learning Week2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Matlab for MAC 下载 address:ClickHere
Matlab for MAC 学习地址:ClickHere
Multivariate Linear Regression
当有更多信息提供来预测时用multivariate linear regression :
n: 有多少已知信息(feature)
x^(i): 第i 个training example的已知信息(指第i行的全部关于已知信息的数据)[i:index]
x^(i)j:在第i行的第j个value
例子:
x^(3) = [1,2,3,4]
x^(2)3 = 2
Hypothese:
x: 表示第x个feature(已知信息)
i : theta
h i(x)= (i0) + (i1*x1) + (i2*x2) + (i3*x3) + (i4*x4)
且,x0 = 1是恒定的(start from 0,i0*x0)
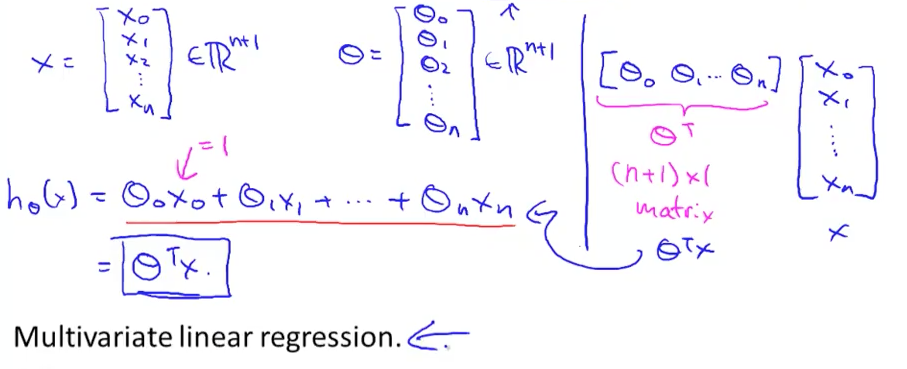
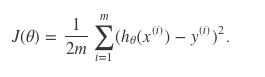
等于

当n=1 Vs. 当n>=1:
[都需要同时更新training example,区别在于右边的]

Gradient Descent – Feature Scaling
(1)确保feature都在差不多的计量维度,即x取值的区间要小,参考” -1<= xi <= 1 ” (太大或太小都不行)
(2)使用平均值作图使路径汇集(converge)更快, 找global mini(最中心的地区)也快
Mean Normalisation (由2改进版):
把 xi 换成 xi - ui
注意!!:不采用x0 = 1,因为这样平均值会得零
x1 = (各个feature的值 -feature的平均值)/ 最大- 最小

Gradient Descent – Learninf Rate
*用x轴的点来校正rate alpha
*gradient的线段越平行x轴,说明gradient descent越converge,因为没有太大变化。
*各种machine learning问题有各种learning rate, 和converge的范围,所以需要画出Number of iteration的图像。
*两种converge的算法:
-画梯度图像,观察趋于平行区域
-自动化converge test


Features & Polynomial Regression
Normal Equation
用matrix[x0 到 xn](新增x0 = 1)与vector[y]来表达
x = m*(n+1) y = m*1 theta(dimension) = number of column(n+1)
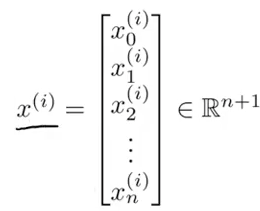
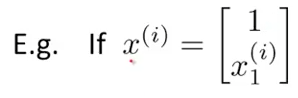
Theta:公式:
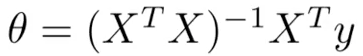
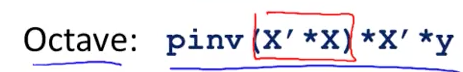
选择feature scale(gradient descent) 或 normal equation 做。
normal equation不用担心x feature的取值范围。
m: training examples n:features
Gradient Descent
-好处
(1)当n 越大,运行越好
-坏处
(1)选择alpha(learning rate)
(2)需要好多重复(itaration)
Normal Eqaution
-好处
(1)不需要选择alpha(learning rate)
(2)不需要重复(itaration)
-坏处
(1)需要计算(X^TX)^(-1)
(2)当n 越大,运行越慢(大部分用时O^3,从n=10w开始慢下来)
Normal Equation - Noninvertibility
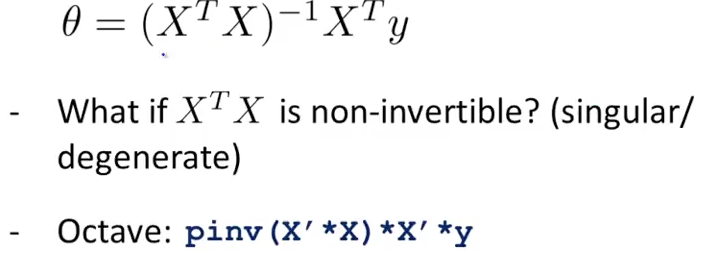
产生Non-invertible的原因:
(1)多余的features(linear dependent)
- 如x1 = in m^2
- x2 = in feet^2
- 其实两者都是面积且互相可以换算
(2)太多features
- 如:m <= n, 解决办法:删除一些features,或regulation[pinv(): pseudo inverse function]使用不同线性代数的库的方法叫违逆[pseudo-inverse]
- 即使x’x的结果non-inverse,但算法过程依然正确,出现non-inverse matrix 情况极少, 所以可以忽略在线性回归[linear regretion]过程里的non-inverse问题
Quiz 1
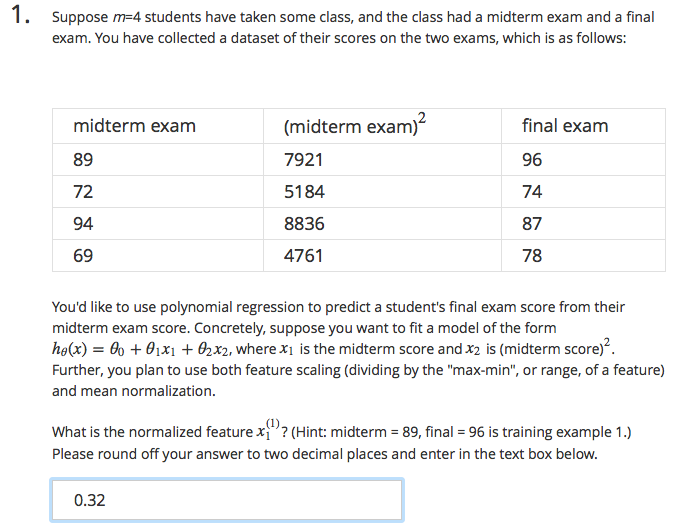



Quiz 2

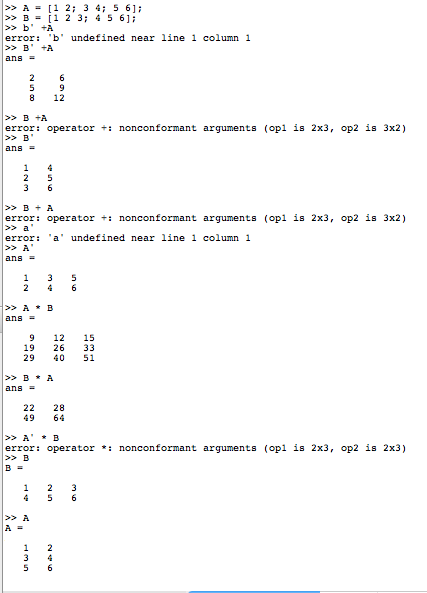


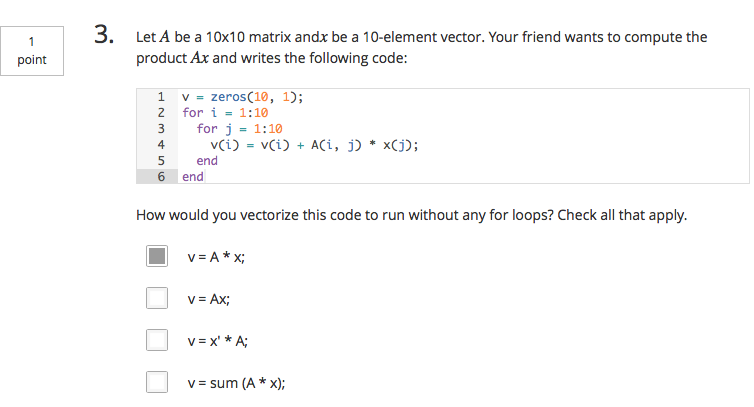
第三题解答:[Click Here]



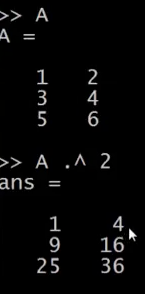
A = log(x);

这篇关于Machine Learning Week2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









