本文主要是介绍Improving Diffusion Models for AuthenticVirtual Try-on in the Wild # 论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
URL
https://arxiv.org/pdf/2403.05139
主页:https://arxiv.org/pdf/2403.05139
TL;DR
24 年 3 月韩国的一篇文章,用 reference net 做换装

Model & Method
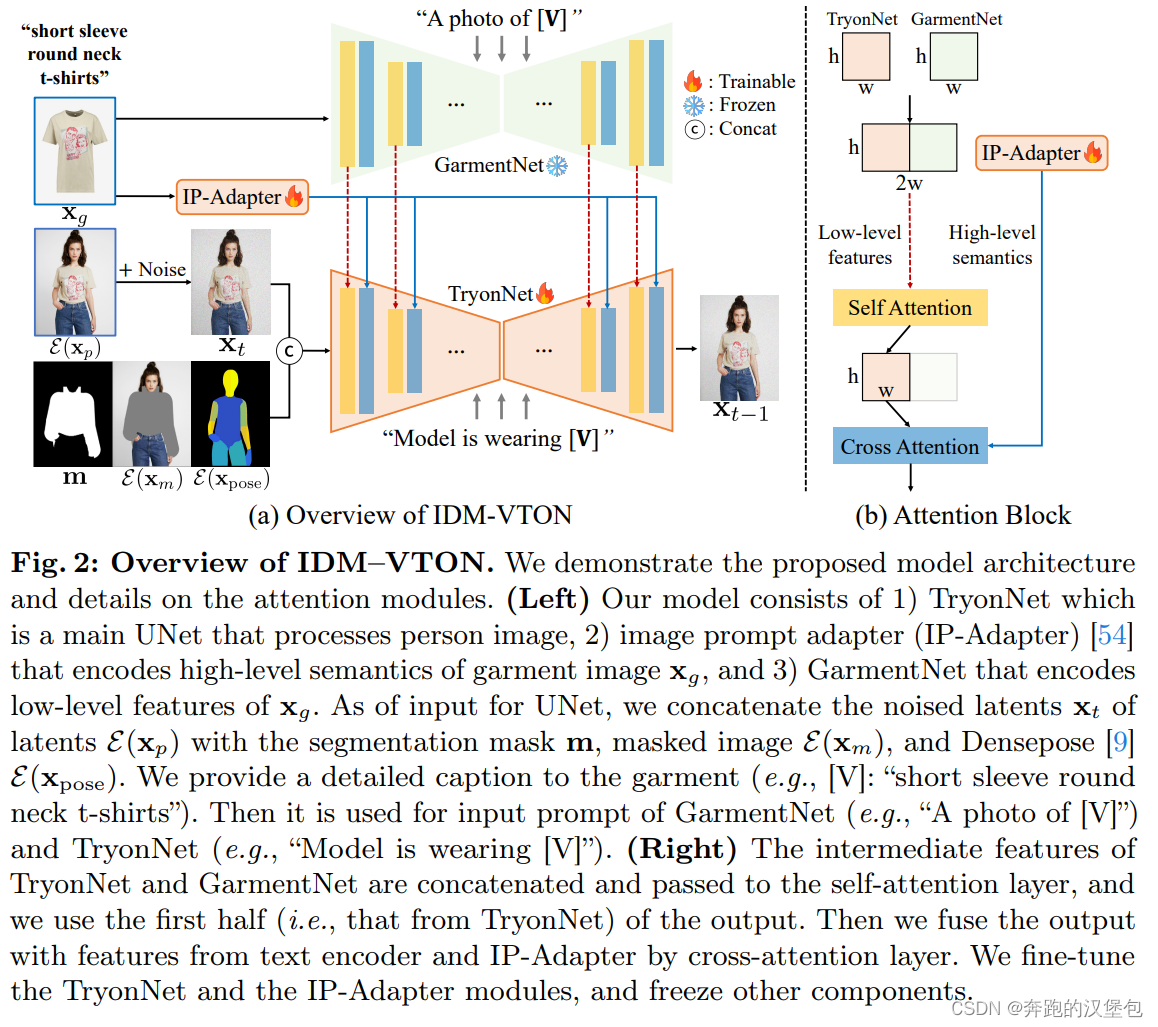
ppl 如下图,和之前认知的 reference net 的区别是,本文训练的是 denoising unet 而不是 reference net。
- 待替换的服装 + 该服装详细的 caption 作为 reference net 的输入,提取 feature 之后通过 self attn 注入 denoising net 中。
- 参考人物图提取衣服的前背景 + 3dmm 之后,concat 到一起送入到 denoising unet 里。
- 同时要替换的服装也会通过 ipdapter + cross attn 提取语义特征注入到 denoising unet 内。
- 两个 unet 的 text prompt 是不同的
Dataset & Results
Thought
- 思路反过来了,不训练 reference net,训练 denoising net。这样的话可以让 reference net 发挥想要的作用吗?
- 分治的思路值得参考:
- id 和物体特征信息分别通过 cross attn、self-attn 方式注入。
- 物体特征信息又细分了 semantic、fine-grained 特征,通过不同网络提取出来 concat 到一起去,然后注入 self-attn
这篇关于Improving Diffusion Models for AuthenticVirtual Try-on in the Wild # 论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
