wild专题
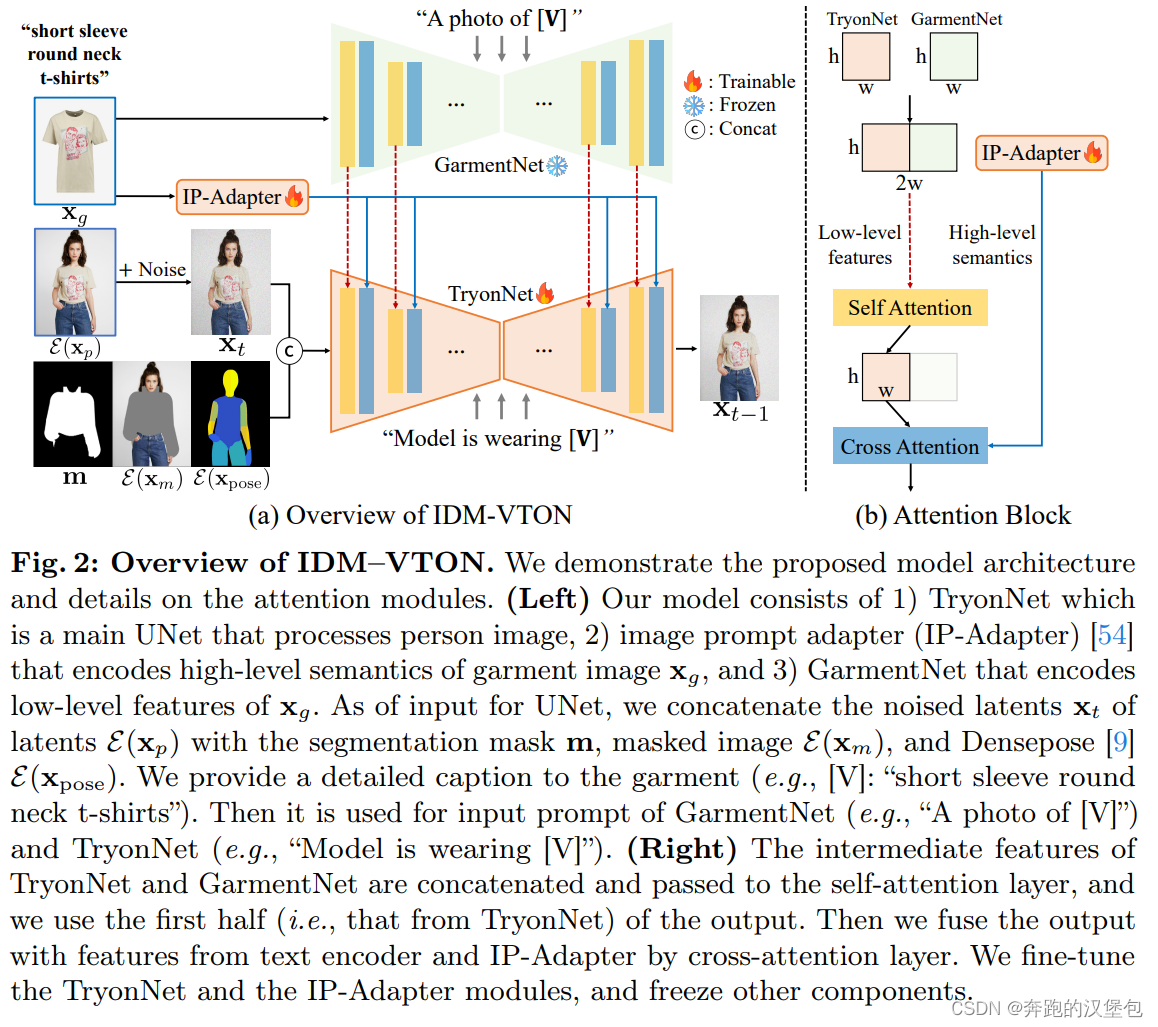
Improving Diffusion Models for AuthenticVirtual Try-on in the Wild # 论文阅读
URL https://arxiv.org/pdf/2403.05139 主页:https://arxiv.org/pdf/2403.05139 TL;DR 24 年 3 月韩国的一篇文章,用 reference net 做换装 Model & Method ppl 如下图,和之前认知的 reference net 的区别是,本文训练的是 denoising unet 而不是 refe

NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections(野外的 NERF: 用于无约束照片采集的神经辐射场) Abstract 我们提出了一种基于学习的方法来合成新的视图的复杂场景使用只有非结构化的收集野生照片。我们建立在神经辐射场(neRF)的基础上,它使用多层感知机的权重来模拟场景的密度和颜色
![[MGK∗19] 《Neural rerendering in the wild》(CVPR2019)阅读笔记 (完)](https://img-blog.csdnimg.cn/a67f573728b8426ea9803603d8bd9a5e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbGVlMjgxMw==,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
[MGK∗19] 《Neural rerendering in the wild》(CVPR2019)阅读笔记 (完)
一、文献拟解决的问题 提出了一个完整的场景捕捉框架,利用网络上的图片进行一个大型建筑的全景捕获——重建和渲染将输入的场景图像分解为视点,外观,语义标签,并依靠一个近似的几何代理,我们可以渲染出真实感的图像与过去的一些方法的比较,提高了结果的真实性 效果展示: 【Neural Rerendering in the Wild - CVPR 2019-哔哩哔哩】 二、分析的思路 (一)总览 首

小白的论文学习笔记《Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild》
这篇论文用百度翻译出来中文题目就是:从野外图像中无监督学习可能对称的可变形三维物体。 我本科是学机械的,然后现在研一转成了视觉方向,这也算是我第一次读三维视觉的文章,现在基础知识非常薄弱,所以有许多地方可能会有问题还希望各位能批评指正。 这篇文章主要写的是:从一幅图像中重建可变形物体实例的3D姿态、形状、反照率和光照,具有极佳的保真度。 文章提出了一种在没有外部监督的情况下,从原始单视角图像中学

Codeforces VK Cup 2015 Wild Card Round 1 (AB)
比赛链接:http://codeforces.com/contest/522 A. Reposts time limit per test:1 second memory limit per test:256 megabytes One day Polycarp published a funny picture in a social networ

【OpenAI使用问题记录】申请Wild Card时遇到的两个问题
项目场景: 在申请Open Ai时API时,需要付费调用API接口,国内通常来说是申请虚拟卡(其实是借记卡性质,,先充后用)。在申请虚拟卡后,远程登录环境时,遇到两个问题,记录一下,以备后查。 注册 WildCard 访问 WildCard | 一分钟开卡,轻松订阅海外软件服务 ,邀请码在最后五位,88折优惠。还是相当方便的。 进入之后,填写手机号,获取验证码,勾选同意和承诺,点击继续

vulnhub靶机之west-wild-1.1
扫描IP 扫描一下端口 在这里插入图片描述 然后看到了smb,http,ssh,咱们先看http ,然后扫描一下目录 在这里插入图片描述 发现没有东西,然后想到smb枚举,并登录然后看看有没有可用信息。 在这里插入代码片1.enum4liux 192.168.34.1582.smbclient -L \\192.168.34.158 3.smbclient //192.168.

Robot Operating System 2: Design, Architecture, and Uses In The Wild
Robot Operating System 2: Design, Architecture, and Uses In The Wild (机器人操作系统 2:设计、架构和实际应用) 摘要:随着机器人在广泛的商业用例中的部署,机器人革命的下一章正在顺利进行。即使在无数的应用程序和环境中,也存在机器人共享的组件的通用词汇——需要模块化、可扩展且可靠的架构;传感;规划;流动性;
![[HackMyVM]靶场 Wild](https://img-blog.csdnimg.cn/direct/b4c47be59eff48bd8e18ff09c60609e3.png)
[HackMyVM]靶场 Wild
kali:192.168.56.104 主机发现 arp-scan -l # arp-scan -l Interface: eth0, type: EN10MB, MAC: 00:0c:29:d2:e0:49, IPv4: 192.168.56.104Starting arp-scan 1.10.0 with 256 hosts (https://github.com/royhill
wild card matching
题目描述 (http://www.leetcode.com/onlinejudge 倒数第三题) Implement wildcard pattern matching with support for '?' and '*'. '?' Matches any single character.'*' Matches any sequence of characters (incl
POJ 1816 Wild Words(trie 树上的DFS)
Wild Words Time Limit: 2000MS Memory Limit: 65536KTotal Submissions: 4377 Accepted: 1142 Description A word is a string of lowercases. A word pattern is a string of lowercases, '?'s an

EraseNet:End-to-End Text Removal in the wild
整篇文章比较经典,是金连文实验室发的,是文本擦除工作,金老师在这个领域也是收获颇多,数据集和baseline都给了,算是挖了个坑。我们从网络结构和loss这两个层面来看重点。model是一个大的gan结构,loss中包括了gan损失,mask的定位损失,粗输出和精细输出的重建损失,风格和内容损失。 1.introduction 在隐私保护,虚拟现实翻译和图像编辑方面有应用,端到

Text Recognition in the Wild: A Survey
论文地址:https://arxiv.org/pdf/2005.03492.pdf 这是来自华南理工2020年的一篇survey,主要讨论的是场景文本识别(scene text recognition,STR)领域的现状与一些发展方向。 文中提到了他们建立的一个资源库,里面有数据集、现有算法等丰富资源,值得一看:GitHub - HCIILAB/Scene-Text-Recognition

41、Hallucinated Neural Radiance Fields in the Wild
简介 主页:https://rover-xingyu.github.io/Ha-NeRF/ 从(a)一组具有可变外观和复杂遮挡的旅游图像中恢复(b)幻觉神经辐射场(Ha-NeRF)。可以始终如一地呈现©自由遮挡视图,产生不同的外观。 论文提出了一个appearance hallucination(外观幻觉)模块,一个基于cnn的外观编码器和一个视图一致的外观损失,以转移一致的光度外观在不同的

读论文——(Styletext)Editing Text in the Wild
文章目录 1.1 🙄摘要1.2 😎其他部分1.2.1 Introduction部分1.2.2 Related Word部分1.2.3 Methology1.2.4 Experiments Style-Text数据合成工具是基于百度和华科合作研发的文本编辑算法《Editing Text in the Wild》https://arxiv.org/abs/1908.03047结

【论文阅读】Learning High-Speed Flight in the Wild
Learning High-Speed Flight in the Wild:Science Robotics,2021,苏黎世大学 主要内容 提出了一种端到端的方法,通过纯机载传感器和计算,能够在复杂的自然和人造环境中高速自主驾驶四旋翼飞机。该方法可以使无人机以10m/s在复杂的环境下高速飞行,且高速时的故障率降低10倍。 核心工作 该论文认为现有的自主飞行系统是高度设计和模块化的。导航

2016-CVPR-FCN in the Wild 论文学习笔记
目录 1.介绍 2.详解 (1)Lda: (2)Lmi: ①存在约束: ②大小约束: 3.代码(待填坑) 《Fcns in the wild:pixel-level adversarial and constraint-based adaption》 1.介绍 这篇文章发表于 2016 年cvpr,是最早把域自适应⽤到语义分割当中的论文。文章主要针对domain

Reading Text in the Wild with Convolutional Neural Networks
引言: 自然场景图像文本的定位与识别和基于文本的图像检索,该系统基于两个机制,检测方面是region proposal mechanism,识别方面是cnn 1. 介绍 文本检测方法: Edge Box Proposal与Aggregate channel features detector结合,先检测出大量的文字区域的 candidate word bounding boxesFalse-ne

Domain Adaptive Faster R-CNN for Object Detection in the Wild
参考 Domain Adaptive Faster R-CNN for Object Detection in the Wild - 云+社区 - 腾讯云 目录 摘要 1、简介 2、相关工作 3、预热 3.1、Faster R-CNN 3.2、用H散度分布排列 4、目标检测的域适配 4.1、概率观点 4.2、域适配组件 4.3、网络预览 5、实验 5.1、实验设置

论文笔记-Learning from Synthetic Data for Crowd Counting in the Wild 人群计数新方法
Hello, 今天是论文阅读计划的第11天啦。 今天介绍的这篇论文是CVPR 2019的一篇论文,是关于在室外拥挤的人群中的人群计数问题。哈哈,这是我在看别人整理的CVPR论文合集的时候,发现了这篇论文,然后对这个任务有点好奇,所以就下载来看看学习下了。 附上别人整理资料: CVPR 2020 论文开源项目合集:https://github.com/amusi/CVPR2020-Code E

EnsNet: Ensconce Text in the Wild 论文笔记
[2019 AAAI] EnsNet: Ensconce Text in the Wild 文章 https://arxiv.org/pdf/1812.00723代码 https://github.com/HCIILAB/Scene-Text-Removal (MXNet) 论文提出了一种去除自然场景下的图像中的文本的方法。主要解决了两个问题:1.准确定位到图像中的文本位置;2.将文本区
Nerf-Wild神经辐射场论文学习笔记 Neural Radiance Fields for Unconstrained Photo Collections
前言: 本文为记录自己在Nerf学习道路的一些笔记,包括对论文以及其代码的思考内容。 公众号: AI知识物语 B站后续同步更新讲解 本篇文章主要针对其数学公式来学习其内容,欢迎批评指正!!! (代码下篇出) 1:摘要 提出基于学习(learning-based)方法,使用野外照片的非结构化集合(unstructured collections of in-the-wild photogra

【论文阅读-姿态估计】CVPR2021_CanonPose: Self-Supervised Monocular 3D Human Pose Estimation in the Wild
本文将介绍一篇基于自监督的3D人体姿态估计方法,作者来自德国汉诺威大学和加拿大英属哥伦比亚大学。 论文链接:https://arxiv.org/abs/2011.14679 代码链接: 尚未公开 主要思想: 本文提出了一个利用多视角2D图像估计3D人体姿态的模型,主要框架如下图所示。 首先将同一姿态不同视角下的图像分别输入两个共享权重的Lifting网络,这部分网络输出为两个分支,一个分支输出

3D Clothed Human Reconstruction in the Wild论文笔记
3D Clothed Human Reconstruction in the Wild 论文地址:https://arxiv.org/pdf/2207.10053.pdf 作者:Moon, Gyeongsik, Nam, Hyeongjin, Shiratori, Takaak 发表:CVPR 2022 链接:https://github.com/hygenie1228/ClothWild

【文字超分辨率】TextZoom: Scene Text Image Super-Resolution in the Wild 阅读笔记
🌟Paper: Scene Text Image Super-Resolution in the Wild 🌟Code: TextZoom 📖Abstract 低分辨率文本图像经常出现在自然场景中,例如手机拍摄的文档。 识别低分辨率的文本图像具有挑战性,因为它们通常丢失了详细的内容信息,从而导致识别精度较差。一个直观的解决方案是引入超分辨率(SR)技术作为预处理手段。 但是,以前的单
Robot Operating System 2: Design, Architecture, and Uses In The Wild
Robot Operating System 2: Design, Architecture, and Uses In The Wild (机器人操作系统 2:设计、架构和实际应用) 摘要:随着机器人在广泛的商业用例中的部署,机器人革命的下一章正在顺利进行。即使在无数的应用程序和环境中,也存在机器人共享的组件的通用词汇——需要模块化、可扩展且可靠的架构;传感;规划;流动性;