本文主要是介绍EraseNet:End-to-End Text Removal in the wild,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
整篇文章比较经典,是金连文实验室发的,是文本擦除工作,金老师在这个领域也是收获颇多,数据集和baseline都给了,算是挖了个坑。我们从网络结构和loss这两个层面来看重点。model是一个大的gan结构,loss中包括了gan损失,mask的定位损失,粗输出和精细输出的重建损失,风格和内容损失。
1.introduction
在隐私保护,虚拟现实翻译和图像编辑方面有应用,端到端的场景文本擦除面临三个问题:1.端到端文本擦除不需要提供文本位置信息,2.文本被擦除且用合理的背景进行填充,3.非文本区域和背景不能变。论文提了新数据集,scut-enstext,这个数据集质量比较高,gt是人工用ps改的,但是需要申请。
另外本文强调了和图像修复的不同,有点类似图像修复任务,两者都考虑了目标区域的恢复,但是图像修复在训练和推理阶段都需要输入缺失区域或者mask,端到端文本修复在推理时仅需要图。图像修复缺失区域恢复主要基于周边的纹理,场景文本擦除,文本区域的背景是主要目标。
2.model
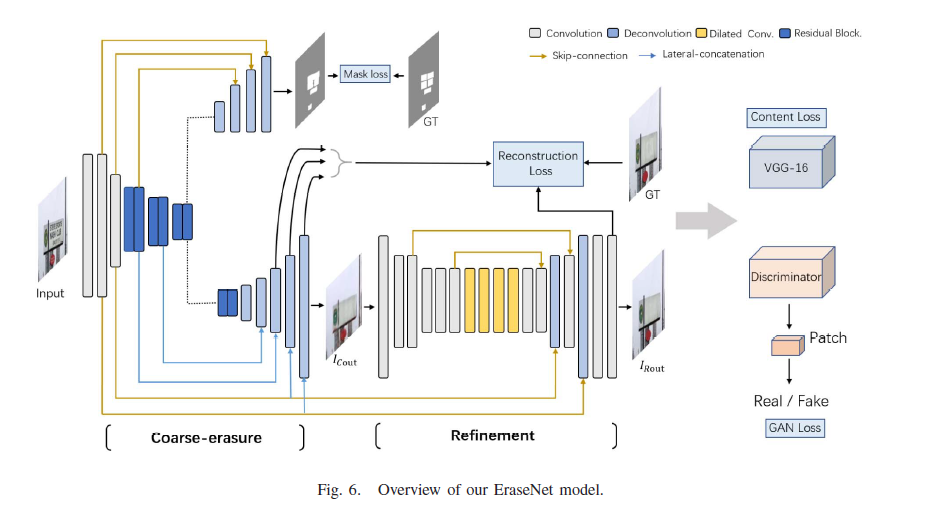
model层面的输入是原图,gt和mask,gt是用ps修复的图。从图上看,backbone之后接了两个分支,最上面的分支是mask分支,dice loss,这个分支最大的作用是判定mask的位置,用mask标签来约束,在推理时不需要,第二个分支是上采样的粗网络分支,这个分支输出去除文字区域的原图,不过是粗略输出,粗略擦除之后接一个精细擦除的refinement网络,这个网络在粗分的基础上做精细擦除,网络做了很多残差的连接和融合。本身是一个gan框架,下面是判别器的网络。

判别器考虑了全局和局部特征,全局特征是除了text mask的其他区域,局部特征是text mask的生成区域,两者做了融合。
3.loss
损失函数是本文的关键,erasenet有很多损失,第一个是mask分支的dice loss,

第二个损失gan loss,

第三个损失是local-aware reconstruction loss

第四个损失是content loss

第五个损失是style loss

代码如下:
class LossWithGAN_STE(nn.Module):def __init__(self, logPath, extractor, Lamda, lr, betasInit=(0.5, 0.9)):super(LossWithGAN_STE, self).__init__()self.l1 = nn.L1Loss()self.extractor = extractorself.discriminator = Discriminator_STE(3) ## local_global sn patch ganself.D_optimizer = torch.optim.Adam(self.discriminator.parameters(), lr=lr, betas=betasInit)self.cudaAvailable = torch.cuda.is_available()self.numOfGPUs = torch.cuda.device_count()self.lamda = Lamdaself.writer = SummaryWriter(logPath)def forward(self, input, mask, x_o1, x_o2, x_o3, output, mm, gt, count, epoch):self.discriminator.zero_grad() # 输入gt和原图可以得到文字区域D_real = self.discriminator(gt, mask) # real,输入gt就多了,让模型关注去掉文字区域,让其生成的更加真实一点D_real = D_real.mean().sum() * -1D_fake = self.discriminator(output, mask) # fakeD_fake = D_fake.mean().sum() * 1D_loss = torch.mean(F.relu(1. + D_real)) + torch.mean(F.relu(1. + D_fake)) # SN-patch-GAN lossD_fake = -torch.mean(D_fake) # SN-Patch-GAN lossself.D_optimizer.zero_grad()D_loss.backward(retain_graph=True)self.D_optimizer.step()self.writer.add_scalar('LossD/Discrinimator loss', D_loss.item(), count)output_comp = mask * input + (1 - mask) * output# mask*input:其他区域,1-mask * output:生成出来的文字区域,output_comp:输入的其他区域和生成出来的文字区域的组合# import pdb;pdb.set_trace()# local-aware reconstruction loss, 将输出的文字区域给予更高的权重,非文字区域权重低# 精细阶段的输出重建损失holeLoss = 10 * self.l1((1 - mask) * output, (1 - mask) * gt) # 1-mask文字区域,文字区域的重建损失validAreaLoss = 2 * self.l1(mask * output, mask * gt) # 非文字区域的重建损失### MSR loss #### x_o1/x_o2/x_o3:粗略输出的三张图masks_a = F.interpolate(mask, scale_factor=0.25)masks_b = F.interpolate(mask, scale_factor=0.5)imgs1 = F.interpolate(gt, scale_factor=0.25)imgs2 = F.interpolate(gt, scale_factor=0.5)msrloss = 8 * self.l1((1 - mask) * x_o3, (1 - mask) * gt) + 0.8 * self.l1(mask * x_o3, mask * gt) + \6 * self.l1((1 - masks_b) * x_o2, (1 - masks_b) * imgs2) + 1 * self.l1(masks_b * x_o2, masks_b * imgs2) + \5 * self.l1((1 - masks_a) * x_o1, (1 - masks_a) * imgs1) + 0.8 * self.l1(masks_a * x_o1, masks_a * imgs1)mask_loss = dice_loss(mm, 1 - mask) # 数据集中文字部分是黑色,值为0,其余为白色,值为1,论文是反过来的,因此1-mask,让模型关注文字部分feat_output_comp = self.extractor(output_comp) # 混合形式的特征feat_output = self.extractor(output)feat_gt = self.extractor(gt)# vgg特征提取的三个特征图prcLoss = 0.0for i in range(3):prcLoss += 0.01 * self.l1(feat_output[i], feat_gt[i])prcLoss += 0.01 * self.l1(feat_output_comp[i], feat_gt[i])styleLoss = 0.0for i in range(3):styleLoss += 120 * self.l1(gram_matrix(feat_output[i]), # 用特征图构建了一个gram矩阵,集中在恢复的文本擦除区域的视觉表示上gram_matrix(feat_gt[i]))styleLoss += 120 * self.l1(gram_matrix(feat_output_comp[i]),gram_matrix(feat_gt[i]))""" if self.numOfGPUs > 1:holeLoss = holeLoss.sum() / self.numOfGPUsvalidAreaLoss = validAreaLoss.sum() / self.numOfGPUsprcLoss = prcLoss.sum() / self.numOfGPUsstyleLoss = styleLoss.sum() / self.numOfGPUs """self.writer.add_scalar('LossG/Hole loss', holeLoss.item(), count)self.writer.add_scalar('LossG/Valid loss', validAreaLoss.item(), count)self.writer.add_scalar('LossG/msr loss', msrloss.item(), count)self.writer.add_scalar('LossPrc/Perceptual loss', prcLoss.item(), count)self.writer.add_scalar('LossStyle/style loss', styleLoss.item(), count)GLoss = msrloss + holeLoss + validAreaLoss + \prcLoss + styleLoss + \0.1 * D_fake + 1 * mask_lossself.writer.add_scalar('Generator/Joint loss', GLoss.item(), count)return GLoss.sum()
这篇关于EraseNet:End-to-End Text Removal in the wild的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!