本文主要是介绍Reading Text in the Wild with Convolutional Neural Networks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言:
自然场景图像文本的定位与识别和基于文本的图像检索,该系统基于两个机制,检测方面是region proposal mechanism,识别方面是cnn
1. 介绍
文本检测方法:
Edge Box Proposal与Aggregate channel features detector结合,先检测出大量的文字区域的 candidate word bounding boxes
False-negative候选词边框使用随机森林分类器过滤掉非文字的proposal
其余的proposal使用CNN训练来回归边界框坐标进行调整
文本识别方法:
将整张图像读进 CNN 网络,直接一次性的完成文字识别过程,用90k的字典对单词进行分类
model完全根据合成数据训练的,该数据集没有人为标记,采用增量学习的方法训练多类模型
视频文本的大规模视觉检索
2. 方法概述
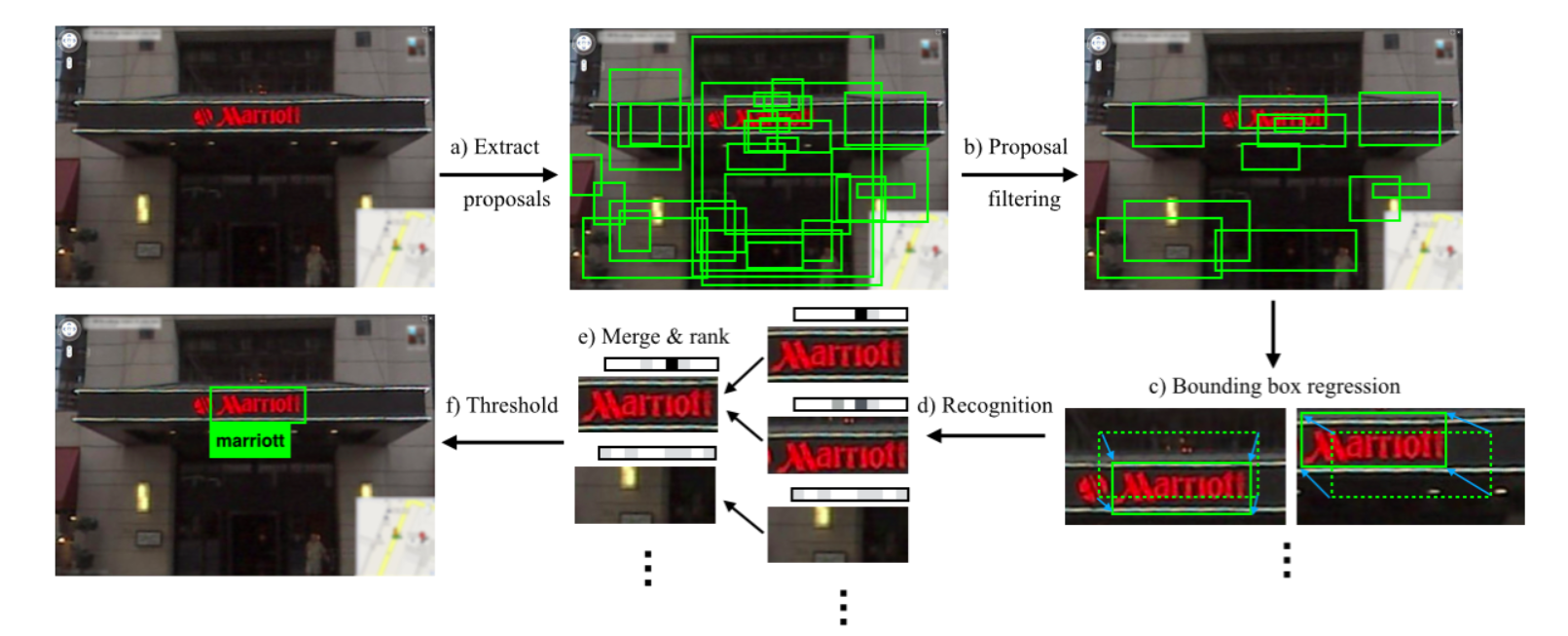
1.给出许多预测框(用训练过的聚合通道特征检测器来生成候选边界框)
2.采用随机森林分类器过滤
3.CNN进行检测框坐标回归
4.CNN进行文本识别(全词识别方法,将模型识别任务作为一个跨越90k个可能单词的字典的多方向分类任务,由于这种规模的分类任务需要大量训练数据,这些数据都是从合成数据训练出来的,合成的数据引擎能够渲染足够真实和可变的单词图像样本)
5.不断采用greedy NMS+CNN调整bounding box坐标合并检测部分,并打分
6.对检测进行阈值设置,最终得到文本检测结果
3. 传统工作
分别是文本检测,文本识别
3.1 文本检测方法
基于字符区域/滑动窗口
基于字符区域方法如下:
- 由像素分割成字符,然后将字符组成单词
- 输入图像中笔画宽度恒定的区域
- 通过合成CNN分类器来找最大稳定极值区域
基于滑动窗口方法如下:
- 经过训练的字符分类器CNN可以作为有效的滑动窗口分类器,通过训练有/无文本分类进行滑动窗口评估,还使用CNN进行单字符和双字符分类来进行单词识别
- 所有CNNs中对于不同的分类任务中使用特征共享可以训练出更强的分类器
3.2 文本识别方法
提取一个单词的裁剪图像,并识别所描述的单词,方法分为基于字符的识别和基于全词的识别
基于字符的识别方法如下:
- 依赖于单个字符分类器来进行每个字符的识别,然后该分类器集成到整个单词图像中来生成完整的单词识别
- 使用CNNs作为字符分类器,然后通过无监督二值化技术或者监督分类器将单词分割成潜在的字符区域
- 分割校正和字符识别CNNs与具有固定词典的HMM的组合来生成识别结果
- 使用神经网络分类器作用于段的HOG特征作为score,然后使用beam search(包含一个强的N-gram模型)来找到最佳组合片段
基于全词的识别方法如下:
- 在进行单词分类之前将整个单词子图像的特征池化
- 生成模型已知,使用具有多个位置敏感字符分类器输出的CNN
- 生成模型未知,合成训练数据可以用于真实世界的数据
4. Proposal Generation
region proposal methods,生成具有高召回率的目标region proposal,缺点是大量false-positive检测。文中结合了边缘盒region proposal算法和弱聚合通道特征检测器
4.1 Edge Boxes
想法:图像中的物体都是 self contained,那么一个 bounding box 中包含的这种完全自闭合的边界的数目,代表了这个 bounding box 包含物体的可能性。
用了文献 Structured Forests for Fast Edge Detection、Fast Edge Detection Using Structured Forests提出的 Structured Edge detector 来检测得到边缘响应图(Edge response map)同时,检测出来的 boxes 都带有一个 score,代表了可能性的大小。之后,进行了NMS(非极大值抑制) 去除交叉面积太大的 boxes:对上面的每一个 boxes 按 score 的大小排序,进行非极大值抑制,最后得到单词的一组候选框 Be
4.2 Aggregate Channel Feature Detector
Aggregate Channel Feature(聚合通道特征,ACF)检测器的作用是用于检测框架的计算速度。
使用:基于ACF特征的滑动窗口检测器,采用AdaBoost训练
对每一副图像I,计算若干通道特征C,其中Ω是通道特征提取函数
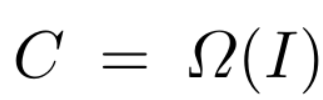
使用以下通道:归一化梯度幅度,定向梯度直方图(6通道),原始灰度输入。对每个通道C平滑处理,划分为块,对每个块中的像素summed and smoothed again,最后得到聚合的通道特征。
多尺度检测需要我们在许多不同尺度上提取特征—特征金字塔,在每个尺度上对特征进行重新采样和重新计算的计算代价很大
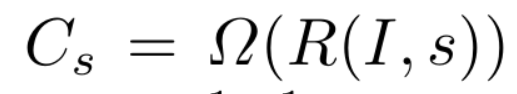
论文中提出可以通过在不同尺度上对特征进行重采样来近似s尺度上的通道特征,λΩ:是通道特定的幂律因子
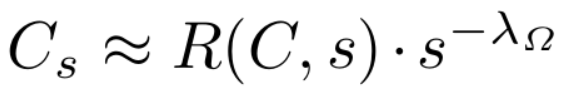
我们在特征金字塔的每个聚合通道特征块中评估此分类器,并重复这一步骤,以多种高宽比解释不同长度的单词,并为每个框打分,最后得到 Bd
论文表示:Edge Box和ACF检测器结合,可以达到很高的召回率,因此,将两个候选框并起来 B = { Be ∪ Bd }
5. Filtering & Refinement
- 如何将上一步骤中产生的大量的false-positive bounding boxes去除
- 与ground truth重叠度低,优化bounding boxes的位置
5.1 Word Classfication
对于每一个bounding box proposal,重采样裁剪后的固定大小的图像,提取HOG特征,得到描述符h,用随机森林分类器进行分类,小于阈值的去除,得到过滤后的bounding-boxes,即 Bf
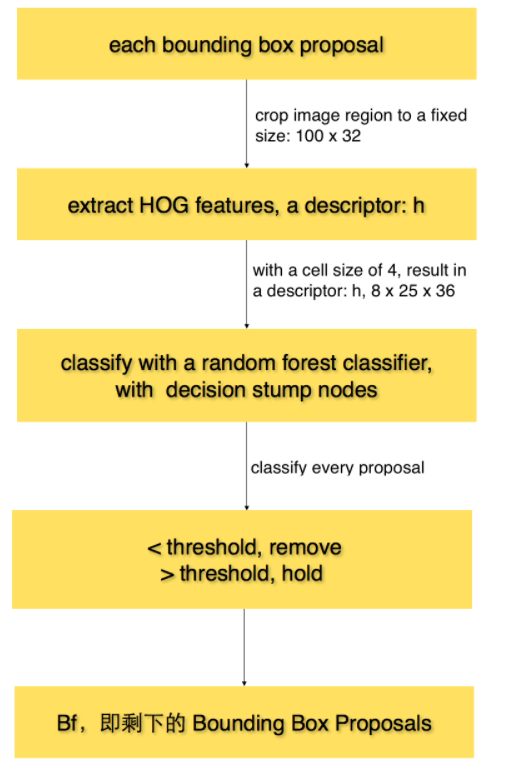
5.2 Bounding Box Regression
因为两个proposals都包含文本,所以没有被有词/无词分类器过滤,但由于文字区域不完全,所以在 recognition 阶段很难被正确识别出来

解决办法:通过训练一个 CNN 网络(regression framework)来调整 bounding boxes 的边界

训练数据中每张图像也给了每一个 groundtruth 的坐标以及内容。用左上角、右下角的坐标来表示,作为训练这个CNN的label。此处每个方案的cropping region proposal设为2倍,也就是将W,h设置为2W,2h
训练过程最小化L2损失
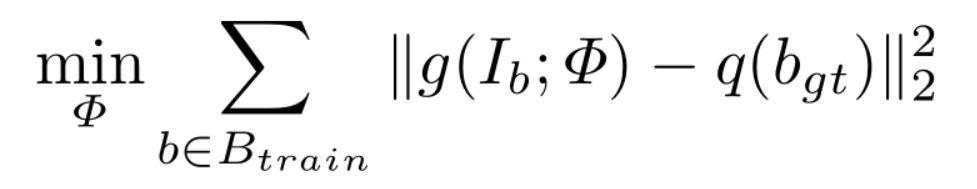
这个 CNN 网络的目的就是在于通过输入的bounding boxes,以及其ground truth的label,训练这个网络,使得每个bounding box 尽可能的拉到ground truth 的区域上
6. Text Recognition
在识别时,采用的是直接将整个region of the word输入进CNN 中。CNN产生字典中所有单词的概率分布,概率最大的单词作为识别结果。以分类的方式进行识别
由于需要扩展到90K的字典,需要收集不同可能单词的训练样本,采用合成训练数据的方式
6.1 Synthetic Training Data
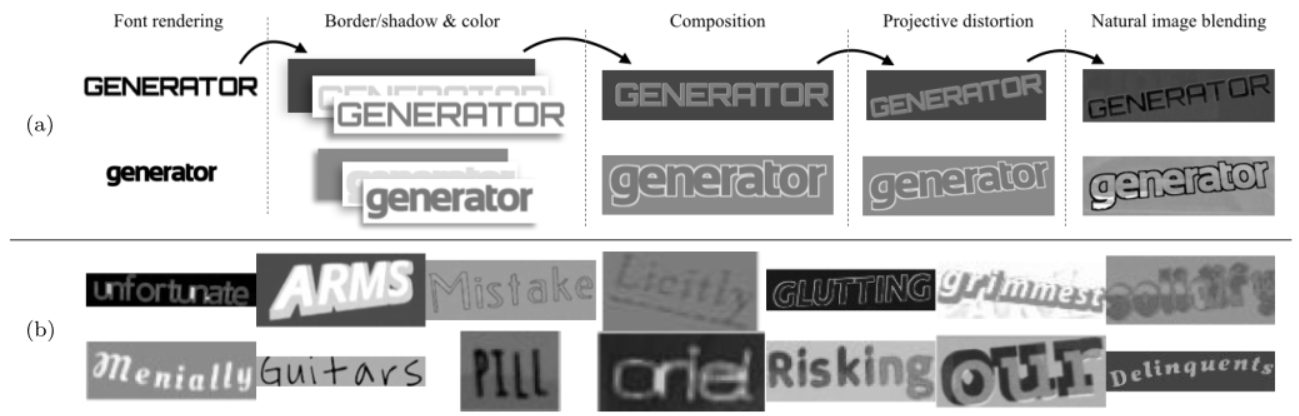
需求:执行的是基于整个单词图像的识别,而不是字符识别,且不需要人工标记数据集
- 1.背景图像层
- 2.前景图像层
- 3.可选边界/阴影图像层
包括以下几个步骤:
- 1. 字体渲染:
字体是从从谷歌字体下载的1400多种字体中随机选择的。字距、权重、下划线和其他属性随任意定义的分布而随机变化。单词通过水平底部文本线或随机曲线渲染到前景图像层的alpha通道上。
- 2.边框/阴影渲染
可以从前景渲染具有随机宽度的插入边框、起始边框或阴影。
- 3. 基础颜色
三个图像层中的每一层都填充了从自然图像上的簇中采样的不同均匀颜色。聚类是通过将训练数据集的每个图像的RGB分量聚类为三个聚类而形成的。
- 4. 投影失真
前景和边界/阴影图像层通过随机、全投影变换,模拟3D世界
- 5. 自然数据混合
每个图像层与来自ICDAR 2003和SVT训练数据集的随机采样图像片段混合。混合和alpha混合模式的数量(正常、添加、倍增、燃烧、最大值等)由随机过程决定,这将创建一个折衷的纹理和构图范围。这三个图像层也以随机方式混合在一起,以获得单个输出图像。
- 6. 噪声
类似于弹性失真、高斯噪声、模糊、重采样噪声和JPEG压缩伪影被引入图像。
6.2 CNN Model
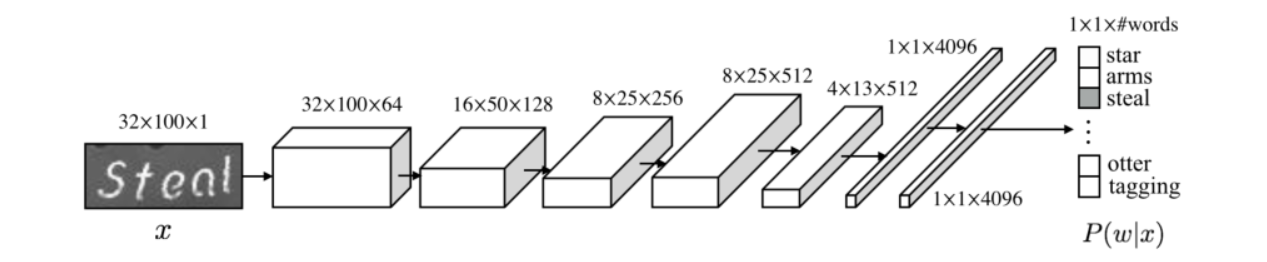
一词一类,多元分类问题,其中单词w被限制在预定义的字典W(90K)中选择
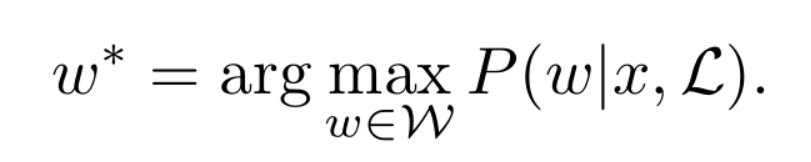
w*:识别结果
x:输入图像
L:限定语言
由x独立于L,可以将上式转换为下式,其中第一项可以由CNN的全连接层softmax输出,第二项可以由先验计算得出(词典或频率进行建模计数)
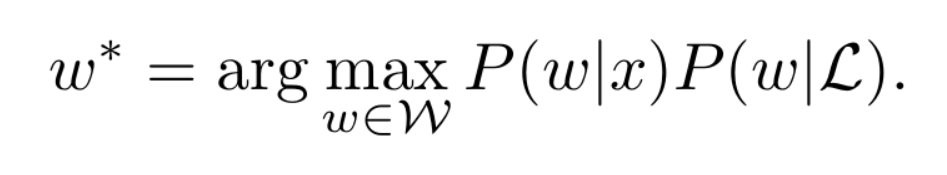
对于此CNN网络的限制,输入x必须是固定大小,图片的高度可以定,但是宽度取决于字符数(1~23个字符长度),简单地将单词图像重采样到固定长度和高度
7.Merging & Ranking
检测器b是过滤后的检测器,在此检测器中我们输出xb图像中的w的概率分布来筛选,然而依旧会有false-positive和重叠检测,提出两个方案text spotting和text based image retrieval
7.1 text spotting
每个word需要bounding box标签,每个bounding box需要text标签,b∈Bf,给出bounding box的标签wb 以及 score sb
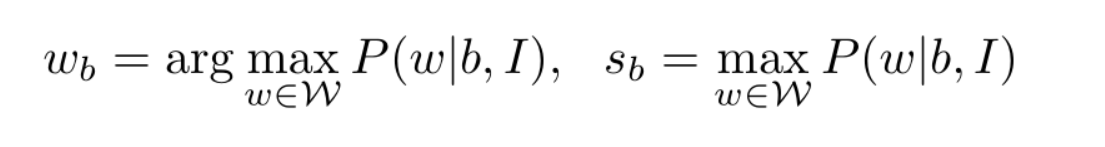
为了聚类相同单词实例的重复检测,对具有same word label的检测器实行greedy NMS

如图,为了改善检测结果的重叠,进行CNN的多轮边界框回归和上述NMS,在每个回归之间执行NMS会导致在最近一轮回归后变得相似的边界框被分组为单个检测
由元组(b、wb、sb)给出的优化结果,根据其得分sb进行排序,阈值决定最终的文本定位结果
7.2 text based image retrieval
检索包含给定查询词的图像列表

检索框架处理由单个查询到多个查询
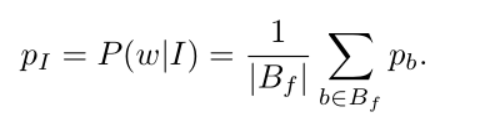
首先离线预处理出PI,表示每张图片的概率分布(即图片I产生w的概率分布,即单词分布/Bf数量),然后计算出反向索引,由单词w映射到PI,即word对应的image
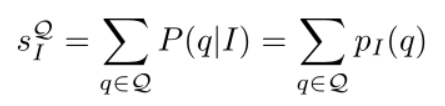
那么对于iamge I的一组查询计算score,可以由words{q1,q2,q3,q4.....}快速查询

相关文章:
这篇关于Reading Text in the Wild with Convolutional Neural Networks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




