本文主要是介绍41、Hallucinated Neural Radiance Fields in the Wild,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
主页:https://rover-xingyu.github.io/Ha-NeRF/
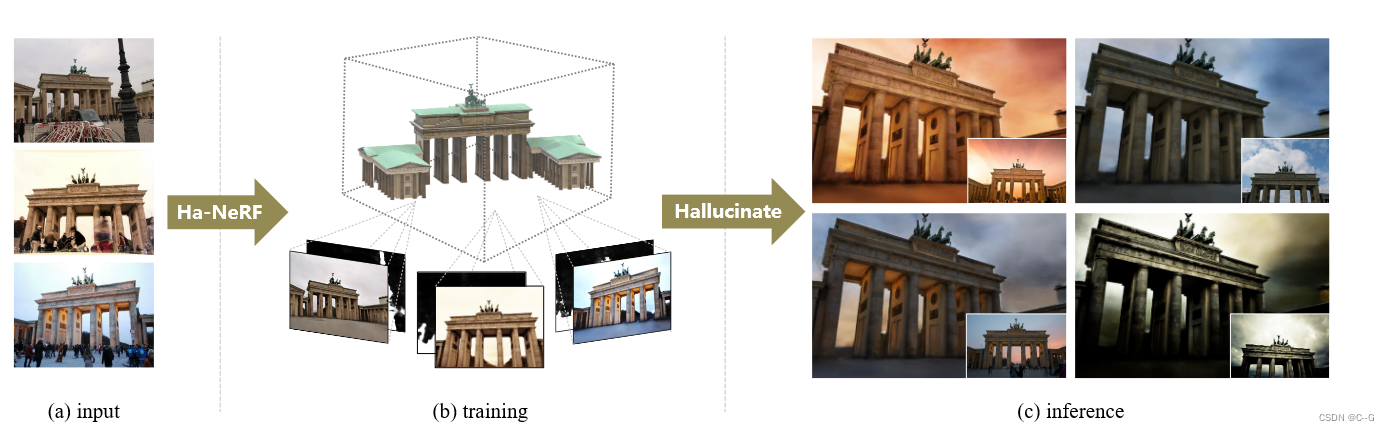
从(a)一组具有可变外观和复杂遮挡的旅游图像中恢复(b)幻觉神经辐射场(Ha-NeRF)。可以始终如一地呈现©自由遮挡视图,产生不同的外观。
论文提出了一个appearance hallucination(外观幻觉)模块,一个基于cnn的外观编码器和一个视图一致的外观损失,以转移一致的光度外观在不同的观点,并将它们转移到新的视图,并针对旅游图像遮挡复杂的问题,利用MLP学习具有抗遮挡损失的图像相关2D可见遮罩,可以在训练过程中自动分离高精度的静态组件
NeRF-W通过训练样本的优化嵌入实现了一个可控的外观(appearance embedding | latent code),这使得它在给定新图像时需要优化嵌入,并且不能产生来自其他数据集的外观幻觉
NeRF-W试图以transient volume作为输入,为每个输入图像优化瞬态体,由于瞬态遮挡的随机性,这是高度不适定的,导致了对场景的不准确的分解,进一步导致了表象和遮挡的纠缠,例如导致了瞬态量来记住晚霞。
创新点
- 提出了用Ha-NeRF方法从一组具有可变外观和遮挡物的图像中恢复外观幻觉辐射场
- 设计了外观幻觉模块,将视觉一致的外观转换为新的外观
- 建立了独立于图像的抗遮挡模块来感知光线可见性
实现流程
原始NeRF公式
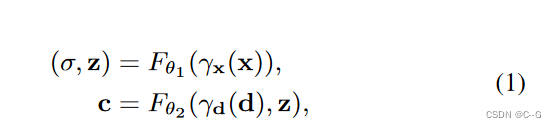
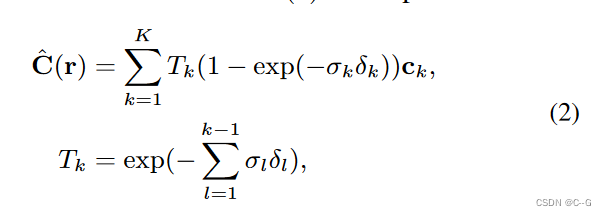
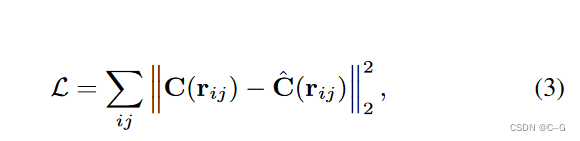
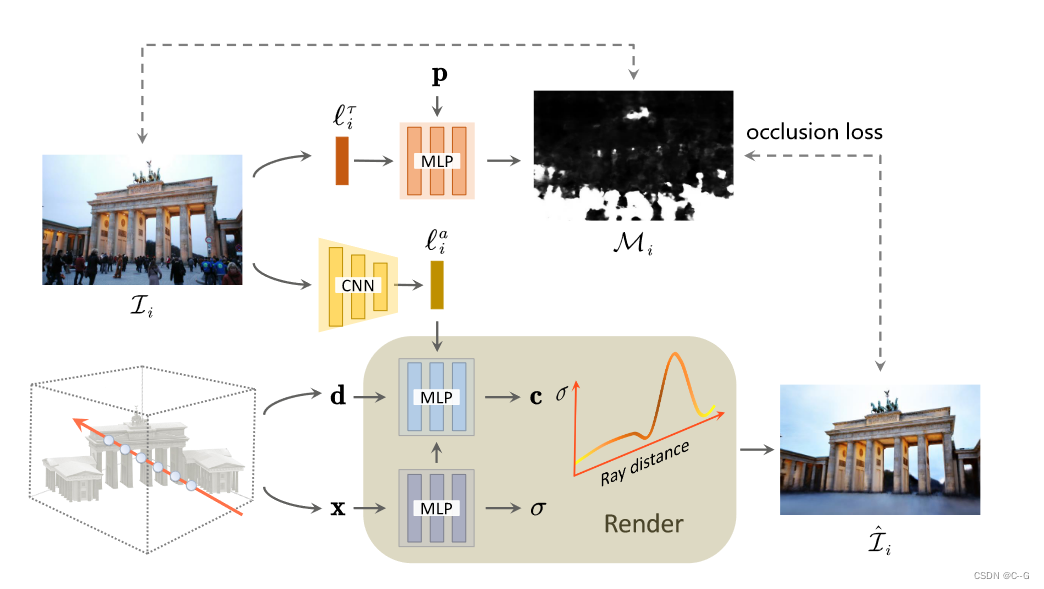
给定图像 L i L_i Li,使用CNN将其编码为一个外观潜在向量 L i a L^a _i Lia 。通过采样位置 x 和观察相机射线的方向 d 合成图像,将它们与 L i a L^a _i Lia 输入 MLPs,产生颜色 c 和体积密度 σ,并呈现重建图像 L ^ i \hat{L}_i L^i。给定一个依赖于图像的瞬态嵌入 L i r L^r_i Lir ,使用MLP将像素位置 p 映射到可见的可能性 M i M_i Mi,这样就可以在遮挡损失的情况下解纠缠图像的静态和瞬态现象。
View-consistent Hallucination
如何从不同外观输入的新镜头中实现三维场景的幻觉,核心问题是如何将场景几何与外观分离,如何将新外观转换到重建的场景中
NeRF-W使用一个优化的外观嵌入来解释输入中依赖于图像的外观,这种嵌入需要在训练过程中进行优化,这使得它需要优化嵌入,使其在训练样本之外产生新镜头的场景,而不能产生来自其他数据集的外观
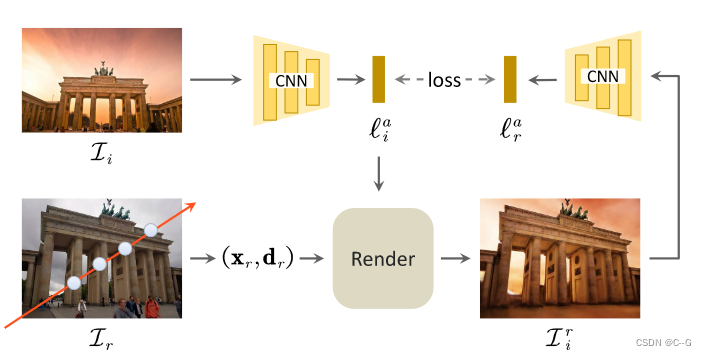
论文使用基于卷积神经网络的编码器 E ϕ E_\phi Eϕ 来学习解错的外观表示,其中的参数 ϕ \phi ϕ 考虑输入中不断变化的照明和光度学后处理, E ϕ E_\phi Eϕ 将每个图像 L i L_i Li 编码为一个外观潜在向量 L i a L^a_i Lia,将公式1中的辐亮度 c 推广到一个依赖于外观的辐亮度 c L i a c^{L^a_i} cLia,引入了对发射颜色的外观潜向量 L i a L^a_i Lia 的依赖
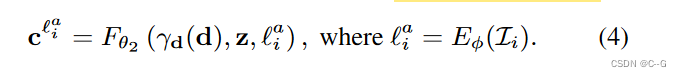
用未配对的图像将外观与观看方向解缠的问题本质上是不适当的,需要额外的约束,论文利用潜在回归损失来鼓励图像空间和潜在空间之间的可逆映射,使用视图一致的损失 L v L_v Lv,通过从外观编码器 E ϕ E_\phi Eϕ 中取一个外观向量 L i ( a ) L^{(a)}_i Li(a),并试图在不同的视图中重构它来实现外观和视图的解纠缠
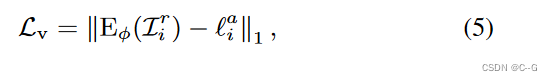
L i r L^r_i Lir为渲染图像,其视图是随机生成的,外观以图像 L i L_i Li 为条件,假设重构的外观向量 E ϕ E_\phi Eϕ 应该与原始外观向量 L i a L^a_i Lia 相同,因为外观向量是跨不同视图的全局表示
利用视点一致性损失(viewconsistent loss)方法防止将图像几何内容编码到外观向量中,该方法将不同视图(也就是内容)的渲染图像编码到同一个向量中,并将体积条件设置在同一个向量上
为提高效率,在训练过程中对光线网格进行采样,并将它们组合为图像 L i r L^r_i Lir,而不是渲染整个图像,这基于一个加色:使用随机网格采样后,图像的全局外观向量将保持不变
Occlusion Handling
论文使用与图像相关的2D可见性图来消除瞬变现象,这种简化能够更准确地分割静态场景和瞬态目标,为了对映射进行建模,使用一个隐式连续函数 F ψ F_\psi Fψ,该函数将一个2D像素位置 p = (u, v) 和一个依赖于图像的瞬态嵌入 L i r L^r_i Lir 映射到一个可见的可能性 M
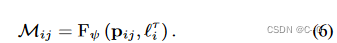
以一种无监督的方式,表示来自静态场景的光线的可见性,用遮挡损失 L o Lo Lo 来解纠缠图像的静态和瞬态现象
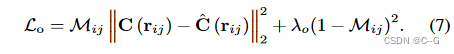
第一项是考虑到被渲染的像素和地面真实颜色之间的像素可见性的重建误差,假设一个像素属于静态现象,可见可能性M值越大,其重要性越高
第一项由第二项平衡,它对应于一个正则化器,在不可见的概率上有一个 λ 乘法器,这阻止了模型对静态现象视而不见
Optimization
为了实现Ha-NeRF,结合上述约束条件,联合训练参数
( θ , ϕ , ψ ) (\theta,\phi,\psi) (θ,ϕ,ψ) 和逐像瞬态嵌入 { L i r } i = 1 N \{L^{r}_{i}\}^N_{i=1} {Lir}i=1N,以优化全目标:
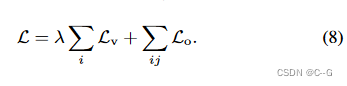
效果


这篇关于41、Hallucinated Neural Radiance Fields in the Wild的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






