本文主要是介绍读论文——(Styletext)Editing Text in the Wild,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.1 🙄摘要
- 1.2 😎其他部分
- 1.2.1 Introduction部分
- 1.2.2 Related Word部分
- 1.2.3 Methology
- 1.2.4 Experiments
- Style-Text数据合成工具是基于百度和华科合作研发的文本编辑算法《Editing Text in the Wild》https://arxiv.org/abs/1908.03047
- 结合github的文档去读论文(因为在实际使用中发现配置参数有些需要明白其物理意义,所以还是看看论文比较好):https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/StyleText/README_ch.md
1.1 🙄摘要
本文的研究对象是编辑自然图像中的文本,也就是在保持原图自然的背景下,用另一个词替换或者修改原图上的文本信息。
- 这个任务十分具有挑战性,因为这要求背景图和文本的风格都需要被保留,这样才能保证编辑后的图像看起来与原图风格无异。
- 此外,我们提出了一个端到端的可训练的风格保留网络(SRNet),其由三个模块组成,分别是:文本前景风格迁移模块;背景抽取模块;融合模块
- 文本迁移模块:将源图文本在保留风格的情况下替换为目标文本
- 背景抽取(背景修复)模块:擦除原来的文本,使用合适的纹理去填充被擦除的文本区域。(PS中的修复工具)
- 融合模块:将从前两个模块得到的信息进行组合,产生编辑好的文本图像。
- 据我们所知,这项工作是首次在词语级别上进行自然图像上的文本编辑。
- 在合成数据集和真实数据集(ICDAR 2013)上的视觉效果和定量结果都充分证实了模块化分解的重要性和必要性。
- 我们也进行了大量的试验来验证我们的方法在多个现实领域的实用性,比如:文本图像合成、增强现实翻译AR,信息隐藏等。
所以明确一点,相比于TextRender,StyleText不仅保留背景的风格,同时也保留文字的风格,所以不需要知道字体。。。这也导致当识别出的文字风格不清晰时,产生的图像上文字也和期望的相差甚远。
如果使用场景是:字体已知,改变背景,融合二者。而不要求模仿字体的风格,那么不建议使用StyleText。可以使用它分离出背景,再使用TextRender等进行文字图像合成
1.2 😎其他部分
1.2.1 Introduction部分
Para1. 介绍了本文所述的课题—— 场景文本编辑(scene text editing)这一领域的背景
Para2. 这一课题目前有两个挑战:①文本风格迁移,②背景纹理修复。
- 其中,文本风格包括许多因素:语言、字体、颜色、朝向、线宽和空间透视,很难完全捕获原图完整的文本风格并据此对目标文本进行转换。
- 编辑后的背景一致性也很难得到保证,特别是当文本显示在一些比较复杂的场景时,比如:菜单和街道店铺招牌等。
- 另外,如果目标文本比原始文本短,则需要擦除字符的超过区域,并填充适当的纹理。
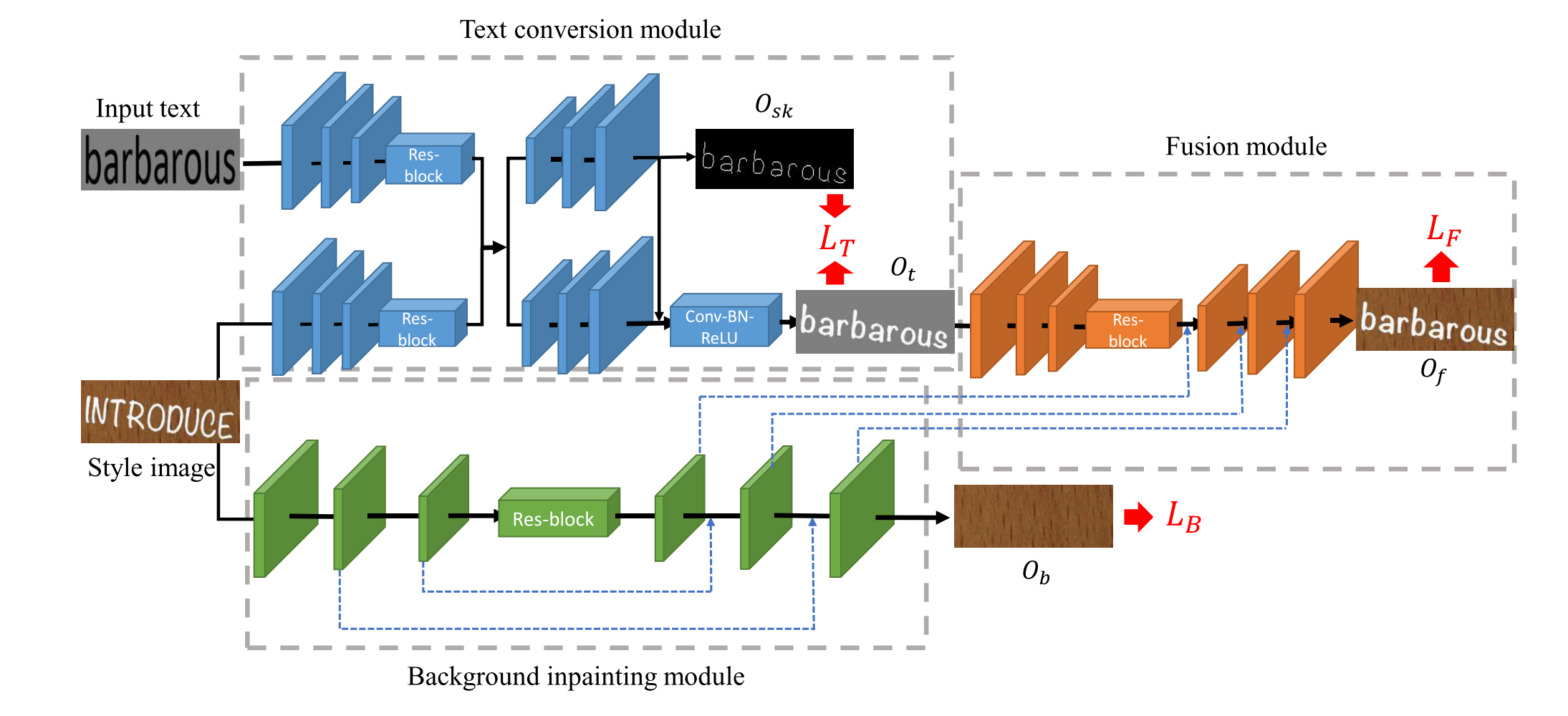
Para3. 为了应对上述挑战,提出了一个保留风格的网络SRN(style retention network),SRNet的核心思想在于将复杂的任务分解为几个简单的、模块化的、可联合训练的子网络:文本转换模块、背景修复模块和融合模块,如上图。
- 文本转换模块(Text conversion module,TCM)负责将原图的文本风格转移到目标文本上去,包括字体、颜色、位置以及规模大小。
使用了一种骨架引导的学习机制(skeleton-guided learning mechanism)- 背景修复模块( Inpaint(图片去水印工具))擦除原始文字笔画的像素,并以自底向上的特征融合方式填充适当的纹理。
遵循“U-Net”的一般架构- 融合模块,自动学习如何有效融合前景信息和背景纹理信息来生成编辑后的文本图像。
Para4
- 介绍GAN(Generative Adversarial Networks)网络;
- 我们不像以前使用GAN的工作一样使用单一的encoder-decoder架构,而是把复杂问题分解成几个模块化的子网络,近期一些工作都证明网络分解策略是有效的
- SRNet比pix2pix效果好
- 相比于字符替换的方式,我们的方法是基于词水平的,更有效。
- 此外,我们的方法不仅可以进行同语言的替换,还可以进行跨语言的文本替换/编辑。
Para5本文的主要贡献:①首个在词级别实现文本编辑的网络;②采用网络分解的方式,效果更好了;③在笔画骨架(字形)的引导下,尽可能保证生成字体的效果;④在多种场景文本编辑任务,如语言内文本图像编辑、增强现实翻译(跨语言)、信息隐藏(如词级别文本擦除)等方面表现出优异的性能。
1.2.2 Related Word部分
分别介绍了GAN,文本风格迁移以及文本擦除和编辑,这三个方面现有的工作,存在的问题,本文提出的框架相对于目前工作的优点。
没啥好看的,也是前面的重复,就是引用了一些可能有用的论文。
1.2.3 Methology
没多看,都是公式,只是注意到一些信息。

如图,每一组图片左侧是原图,右侧是生成的图像。不难发现:
- 我数了一遍,除了第三行的第二、三列图像中存在,原图词语长度<生成图长度,可以直接用背景纹理填充之外。其余情况都是原图词语长度=生成图对应部分词语长度。显然,是一个非常大的局限,生成图语料长度>原图长度,生成效果会不好。
- 丢进模型的可以不仅仅是文本行高度的图像,可以是任意含有文字的图像,这点与PaddleOCR的StyleText实施不太一样,
Style-Text生成的数据主要应用于OCR识别场景。基于当前PaddleOCR识别模型的设计,我们主要支持高度在32左右的风格图像。 如果输入图像尺寸相差过多,效果可能不佳。 - 仔细观察的话,可以看到第二行第一列的图像中,字符
Z.,这里前景色(字体颜色:白色)和背景色(混有白色的黄棕色)比较接近,同时字体轮廓不是非常清晰,效果就会不太好。这点可以在下方图得到验证

从上到下,依次是:原图,生成图,文字,文字骨架,背景图。
1.2.4 Experiments
没有关注和其他方法比较的内容,重点关注了4.8 Failure Cases,毕竟这才是对于工业使用最重要的部分。
当文本具有非常复杂的结构或罕见的字体形状时,效果可能会很差。
如下图,左侧是原图,右侧是合成结果。可以看到,
第一组:虽然前景文字风格转换的很好,但是背景的阴影还是原图的阴影。
第二组:没有提取出复杂空间结构的文字风格(有一定的透视效果),可以看到背景提取失败,直接融合前景和背景十分生硬。
第三组:围绕文本的边界没有被转移。
我们将这些失败案例归因于训练数据中这些样本的不足,因此我们假设可以通过增加更多字体效果的训练集来缓解这些问题。

总结
- 有阴影的文本,
- 原图有透视(非水平/平面正对效果的)的,
- 有发光效果的,
- 字体轮廓不明晰,
- 前景色和背景色比较接近的,
- 都不太适合用这个模型去拟合!
这篇关于读论文——(Styletext)Editing Text in the Wild的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

