本文主要是介绍论文阅读:SDXL Improving Latent Diffusion Models for High-Resolution Image Synthesis,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SDXL Improving Latent Diffusion Models for High-Resolution Image Synthesis
论文链接
代码链接
介绍
- 背景:Stable Diffusion在合成高分辨率图片方面表现出色,但是仍然需要提高
- 本文提出了SD XL,使用了更大的UNet网络,以及增加了一个Refinement Model,以进一步提高图片质量。
提高SD的措施
- 用户偏好调查比较
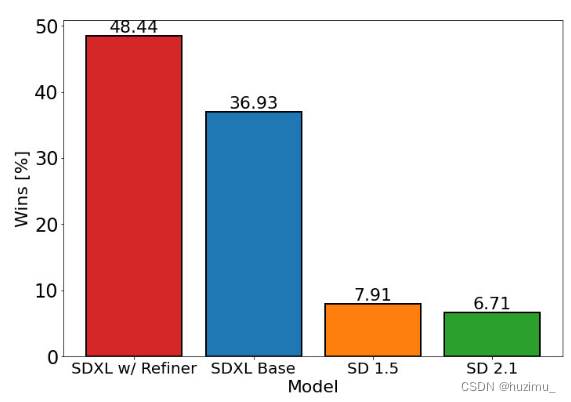
可以看到,在不增加Refiner模型的情况下,SD XL的效果已经比SD 1.5和2.1好很多了。 - SD XL的模型结构
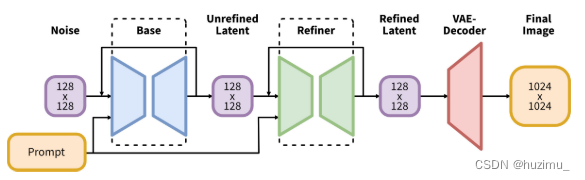
可以看到,SD XL由一个SD base模型和一个Refiner模型组成,二者共用一个提示词输入,前者的输出同时也是后者的输入。Refiner模型其实是一个图片编辑模型。
-
Architecture & Scale

- transformer block方面,忽略高层级的块,而使用低层级的2和10特征块(不懂)
- 使用两个Text Encoder并将它们的输出特征拼接到一起
- 额外使用了Pooled text emb作为条件输入(不懂)
-
Micro-Conditioning
-
Conditioning the Model on Image Size:过去的方法要么选择忽略小于特定尺寸的图片,要么选择放缩图片,前者忽略了大量的图片,后者可能造成图片模糊。SD XL中,将图片尺寸也当做条件输入,这样在推理阶段,用户就可以指定生成图片的尺寸,如图5所示。

-
Conditioning the Model on Cropping Parameters
由于SD 1和2系列使用了图片裁剪的方式进行数据增强,导致了生成的图片中有些物体只展现了一部分,如图4所示。SD XL通过将左上方 的裁剪坐标当做条件输入,让模型学到了裁剪坐标的信息。在推理的过程中,将裁剪坐标条件输入设置为(0,0)即可输出物体在图片中间的图片。


-
-
Multi-Aspect Training
常见情况下SD模型的输出是一个方形的图片,但是在实际应用中,图片的尺寸比例会有不同的要求。为了适应这一需求,SD XL将训练图片按照长宽比划分为不同的数据桶。在训练过程中,每个batch中的图片都来自同一个桶,每个训练步数中的数据在不同桶中之间交替选择。此外,桶的中数据的尺寸也被作为条件输入。 -
Improved Autoencoder
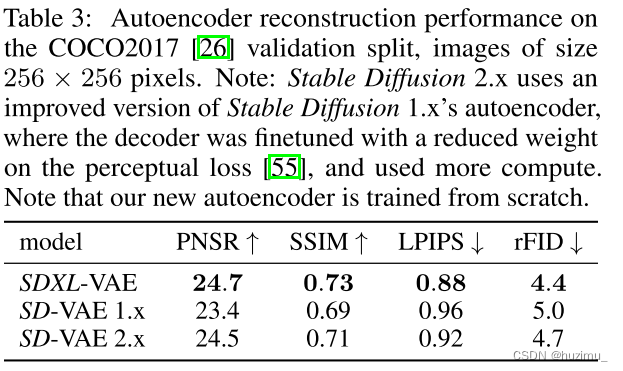
SD XL重新训练了一个更大的autoencoder,可以提高生成图片的局部高频细节。从表3中可以看到,使用提升后的autoencoder后,SD XL的重构性能在多个方面都比SD 1和2有所提高。
-
Putting Everything Together
最终的SD XL是使用前面的所有策略共同训练得到的。
Refinement Stage:使用上述方法训练的模型有些时候仍然会生成低质量的图片,因此为了提高生成高分辨率的图片的能力,SD XL使用图片编辑技术,添加了一个Refiner模型,这个模型是可选的。
未来的工作
作者认为未来还值得研究方向如下:
- 单阶段:SD XL是一个两阶段的模型,时间和空间开销更大。研究一个同样效果或更好效果的单阶段模型很有必要。
- 文本合成:SD XL中采用了更多和更大的text encoder,也取得了更好的效果。使用byte-level tokenizers [52, 27]或者只是使用更大规模的文本编码器是提高SD XL文本处理能力的可能途径。
- 结构:作者们尝试过一些Transformer-based的模型,比如UViT [16] and DiT [33],但是没有发现好的效果。然而,作者们仍然认为,Transformer为主的模型是一个方向。(新的Stable Diffusion 3正是采用了DiT [33]的技术,说明作者们坚持的优化方向是正确的)
- 蒸馏:使用模型蒸馏技术,减小模型的体积,减少空间和时间开销。事实上,SD系列一直有蒸馏版本的模型,比如SD XL Turbo。
- SD XL是在离散时间模式下训练的,需要偏移噪声预测以生成美观的图片。EDM-framework是一个很有潜力的工作,其支持连续时间,可以提高采样灵活性而不需要噪音校对。(不是很懂)
其它
- 重要的相关工作
- 图片编辑模型:SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
这篇关于论文阅读:SDXL Improving Latent Diffusion Models for High-Resolution Image Synthesis的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)