sdxl专题

「ComfyUI」增强图像细节只需要一个节点,SD1.5、SDXL、FLUX.1 全支持,简单好用!
前言 前 言 今天听雨给小伙伴们介绍一个非常简单,但又相当好使的一个插件。 功能很简单,就是增加或者减少图像的细节,节点也很简单,就一个节点,只需要嵌入我们的 ComfyUI 的基础工作流中就可以了,随插随用。 而且该插件不仅支持 SD1.5 和 SDXL,甚至最新出的 FLUX.1 模型也是支持的哦! 好了,话不多说,我们直接开整。 我们先来看效果,这里使用的是 FLUX.

Stable diffusion的SDXL模型,针不错!(含实操)
与之前的SD1.5大模型不同,这次的SDXL在架构上采用了“两步走”的生图方式: 以往SD1.5大模型,生成步骤为 Prompt → Base → Image,比较简单直接;而这次的SDXL大模型则是在中间加了一步 Refiner。Refiner的作用是什么呢?简单来说就是能够自动对图像进行优化,提高图像质量和清晰度,减少人工干预的需要。 简单来说,SDXL这种设计就是先用基础

实战经验分享之移动云快速部署Stable Diffusion SDXL 1.0
本文目录 前言产品优势部署环境准备模型安装测试运行 前言 移动云是中国移动面向政府、企业和公众的新型资源服务。 客户以购买服务的方式,通过网络快速获取虚 拟计算机、存储、网络等基础设施服务;软件开发工具、运行环境、数据库等平台服务;以及ERP、 CRM等应用产品服务。 同时,移动云针对电子政务、金融、教育、医疗、互联网等不同行业特点提供行业 云、混合云等定制化解决方案。

AI绘画Stable Diffusion:为什么生成的图片总是糊的,如何使用SDXL模型精准生图教程
大家好,我是设计师阿威 最近有不少小伙伴刚入门AI绘画的小伙伴,总是说自己生成的图片总是糊的,那么今天就教大家怎么让避免生成模糊的图片,精准生成高清大图 我们先看一下出图时模糊的图片效果。 我相信很多初学者在开始绘图的时候经常会碰到这种情况。当然我自己也曾经碰到过,我总结了一下,一般有以下几种情况。 第一种情况: 大模型使用的是SDXL大模型,VAE模型选择了vae-ft-mse-8

【深度学习】SDXL中的Offset Noise,Diffusion with Offset Noise,带偏移噪声的扩散
https://www.crosslabs.org//blog/diffusion-with-offset-noise 带有偏移噪声的扩散 针对修改后的噪声进行微调,使得稳定扩散能够轻松生成非常暗或非常亮的图像。 作者:尼古拉斯·古藤伯格 | 2023年1月30日 马里奥兄弟使用稳定扩散挖掘隧道。左图显示了未使用偏移噪声的原始结果,右图使用偏移噪声显示了更丰富的黑色调。 稳定扩散在使用偏移

【深度学习】【Lora训练2】StabelDiffusion,Lora训练过程,秋叶包,Linux,SDXL Lora训练
文章目录 一、如何为图片打标1.1. 打标工具1.1.1. 秋叶中使用的WD1.41.1.2. 使用BLIP21.1.3. 用哪一种 二、 Lora训练数据的要求2.1 图片要求2.2 图片的打标要求 三、 Lora的其他问题qa1qa2qa3qa4qa5 四、 对图片的处理细节4.1. 图片尺寸问题4.2. 图片内容选取问题4.3. 什么是一张合适的图?4.3.1. 解决水印问题——in
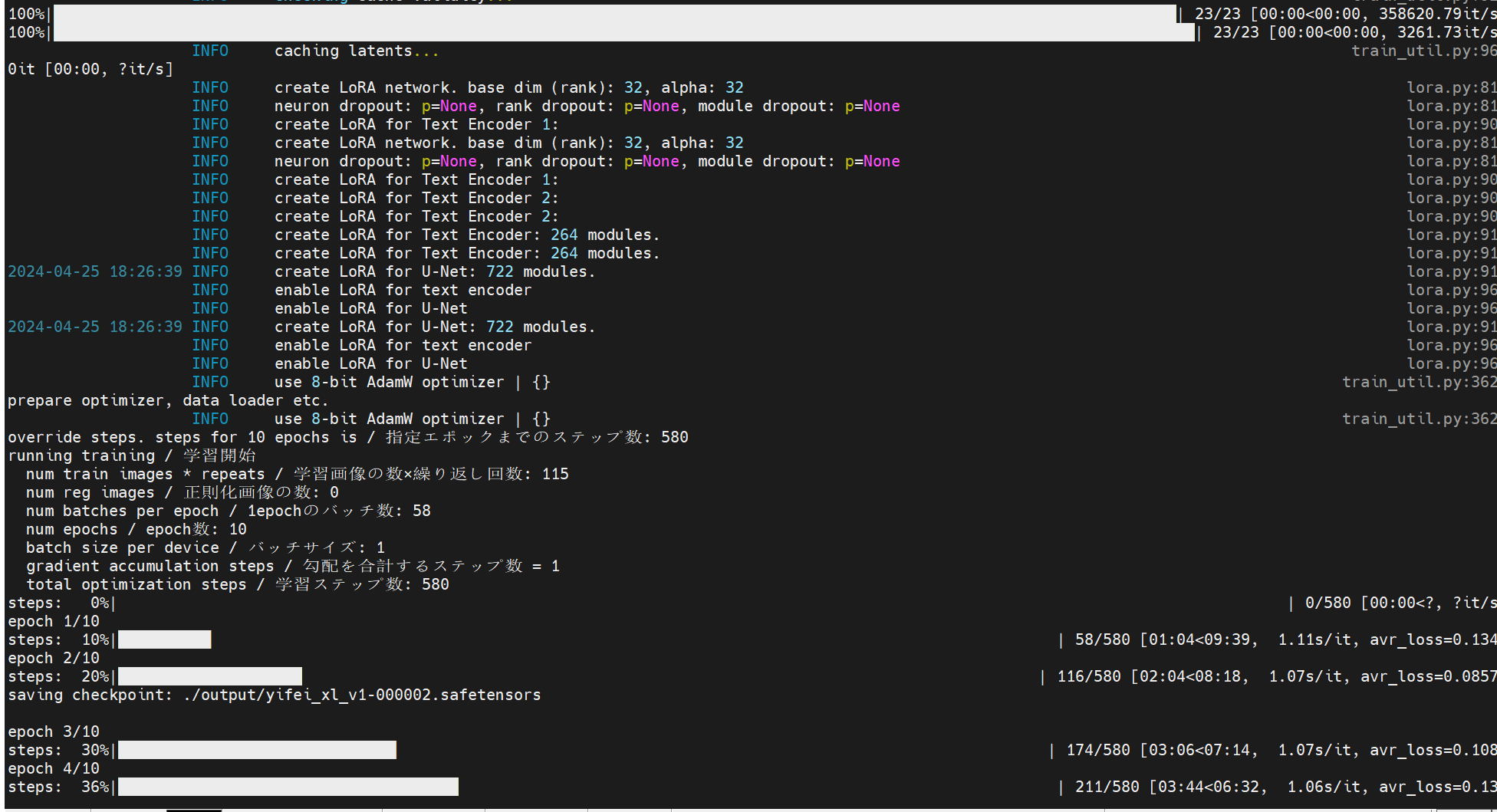
【深度学习】StabelDiffusion,Lora训练过程,秋叶包,Linux,SDXL Lora训练
文章目录 一、环境搭建指南二、个性化安装流程三、启动应用四、打开web五、开始训练 19.27服务器 一、环境搭建指南 打造一个高效且友好的开发环境,我们推荐使用以下简洁明了的中文资源: 项目源码获取: 通过以下命令轻松克隆项目及所有子模块至您的Linux系统: git clone --recurse-submodules https://github.com/Ake

SDXL_webUI_controlnet使用depth_zoe错误解决
diffusers/controlnet-zoe-depth-sdxl-1.0 RuntimeError: Error(s) in loading state_dict for ZoeDepth:Unexpected key(s) in state_dict: 解决措施: Installing the right version of timm did the trick for me p

AIGC——ComfyUI SDXL多种风格预设提示词插件安装与使用
概述 SDXL Prompt Styler可以预先给SDXL模型提供了各种预设风格的提示词插件,相当于预先设定好了多种不同风格的词语。使用这个插件,只需从中选取所需的风格,它会自动将选定的风格词汇添加到我们的提示中。 安装 插件地址:https://github.com/AlekPet/ComfyUI_Custom_Nodes_AlekPet.git git安装 在ComfyUI/cos

AIGC——ComfyUI使用SDXL双模型的工作流(附件SDXL模型下载)
SDXL算法概述 SDXL(Stable Diffusion XL)是Stable Diffusion公司发布的一款图像生成大模型。在以往的模型基础上,SDXL进行了极大的升级,其base模型参数数量达到了35亿,refiner模型参数数量达到了66亿。SDXL与之前的版本最大的不同之处在于它由base基础模型和refiner优化模型两个模型构成,使得用户可以在base模型的基础上再利用优化模型

字节跳动的 SDXL-LIGHTNING : 体验飞一般的文生图
TikTok 的母公司字节跳动推出了最新的文本到图像生成人工智能模型,名为SDXL-Lightning。顾名思义,这个新模型只需很轻量的推理步骤(1,4 或 8 步)即可实现极其快速且高质量的文本到图像生成功能。与原始 SDXL 模型相比,这是一个重大突破,原始 SDXL 模型需要超过 25 个步骤才能达到同等质量。 SDXL-LIGHTNING 简介 虽然 Diffusion 模型在生成

Stable Diffusion 模型分享:DucHaiten-AIart-SDXL(动漫、3D、逼真)
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。 文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八 下载地址 模型介绍 这是一个丰富多彩的 SDXL 模型,可以绘制动漫、3D、科幻、真实等类型的图片。 条目内容类型大模型基础模型SDXL 1.0来源CIVITAI作者DucHaiten文件名称duchaitenAiartSDXL_
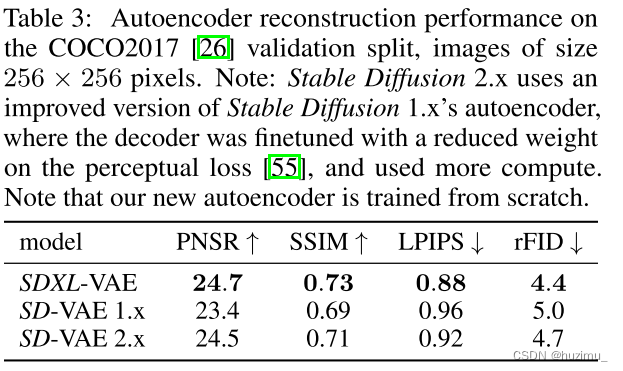
论文阅读:SDXL Improving Latent Diffusion Models for High-Resolution Image Synthesis
SDXL Improving Latent Diffusion Models for High-Resolution Image Synthesis 论文链接 代码链接 介绍 背景:Stable Diffusion在合成高分辨率图片方面表现出色,但是仍然需要提高本文提出了SD XL,使用了更大的UNet网络,以及增加了一个Refinement Model,以进一步提高图片质量。 提高SD的
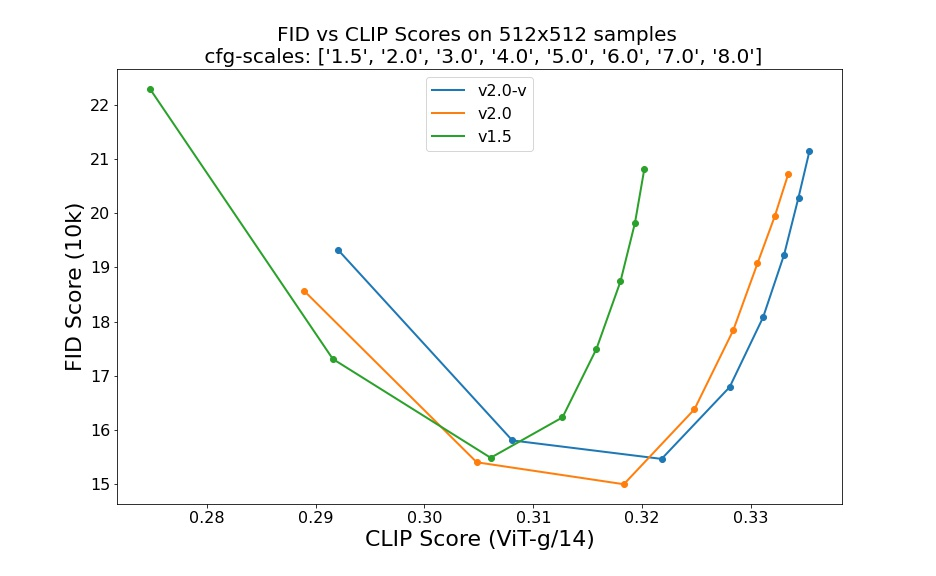
Stable Diffusion ———LDM、SD 1.0, 1.5, 2.0、SDXL、SDXL-Turbo等版本之间关系现原理详解
前言 2021年5月,OpenAI发表了《扩散模型超越GANs》的文章,标志着扩散模型(Diffusion Models,DM)在图像生成领域开始超越传统的GAN模型,进一步推动了DM的应用。 然而,早期的DM直接作用于像素空间,这意味着要优化一个强大的DM通常需要数百个GPU天,而推理成本也很高,因为需要多次迭代。为了在有效的计算资源上训练DM,并保持其质量和灵活性,作者提出将DM应用于强大

字节跳动发布SDXL-Lightning模型,支持WebUI与ComfyUI双平台,只需一步生成1024高清大图!
字节跳动发布SDXL-Lightning模型,WebUI与ComfyUI平台,只需一步生成1024高清大图,需要的步数比 LCM 更低了! 什么是SDXL-Lightning: SDXL-Lightning 是一种快速的文本到图像生成模型。SDXL-Lightning模型的核心优势在于其创新的蒸馏策略,它可以通过几个步骤生成高质量的 1024px 图像。 开源项目地址: htt

实时文字to图:SDXL Turbo 和 LCM-LoRA
参考文章: SDXL Turbo: Real-time Prompting - Stable Diffusion Art 根据目前的实际使用情况 sdxl-turbo 速度更快sdxl 有时候出的人脸会变形

sdxl-turbo、playground文生图模型diffusers使用案例
1、sdxl-turbo SDXL-Turbo是一种快速生成的文本到图像模型,可以在单个网络评估中从文本提示合成逼真的图像。 参考:https://huggingface.co/stabilityai/sdxl-turbo 对比效果相比PixArt模型差很多,参考https://blog.csdn.net/weixin_42357472/article/details/135520142
sdxl-turbo、playground文生图模型使用案例
1、sdxl-turbo SDXL-Turbo是一种快速生成的文本到图像模型,可以在单个网络评估中从文本提示合成逼真的图像。 参考:https://huggingface.co/stabilityai/sdxl-turbo 对比效果相比PixArt模型差很多,参考https://blog.csdn.net/weixin_42357472/article/details/135520142

Stable Diffusion 模型下载:Samaritan 3d Cartoon SDXL(撒玛利亚人 3d 卡通 SDXL)
文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十 下载地址 模型介绍 由“PromptSharingSamaritan”创作的撒玛利亚人 3d 卡通类型的大模型,该模型的基础模型为 SDXL 1.0。 条目内容类型大模型基础模型SDXL 1.0来源CIVITAI作者PromptSharingSamaritan文件名称samaritan3

AI绘画与多模态原理解析:从CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM
前言 终于开写本CV多模态系列的核心主题:stable diffusion相关的了,为何执着于想写这个stable diffusion呢,源于三点 去年stable diffusion和midjourney很火的时候,就想写,因为经常被刷屏,但那会时间错不开去年11月底ChatGPT出来后,我今年1月初开始写ChatGPT背后的技术原理,而今年2月份的时候,一读者“天之骄子呃”在我这篇Chat
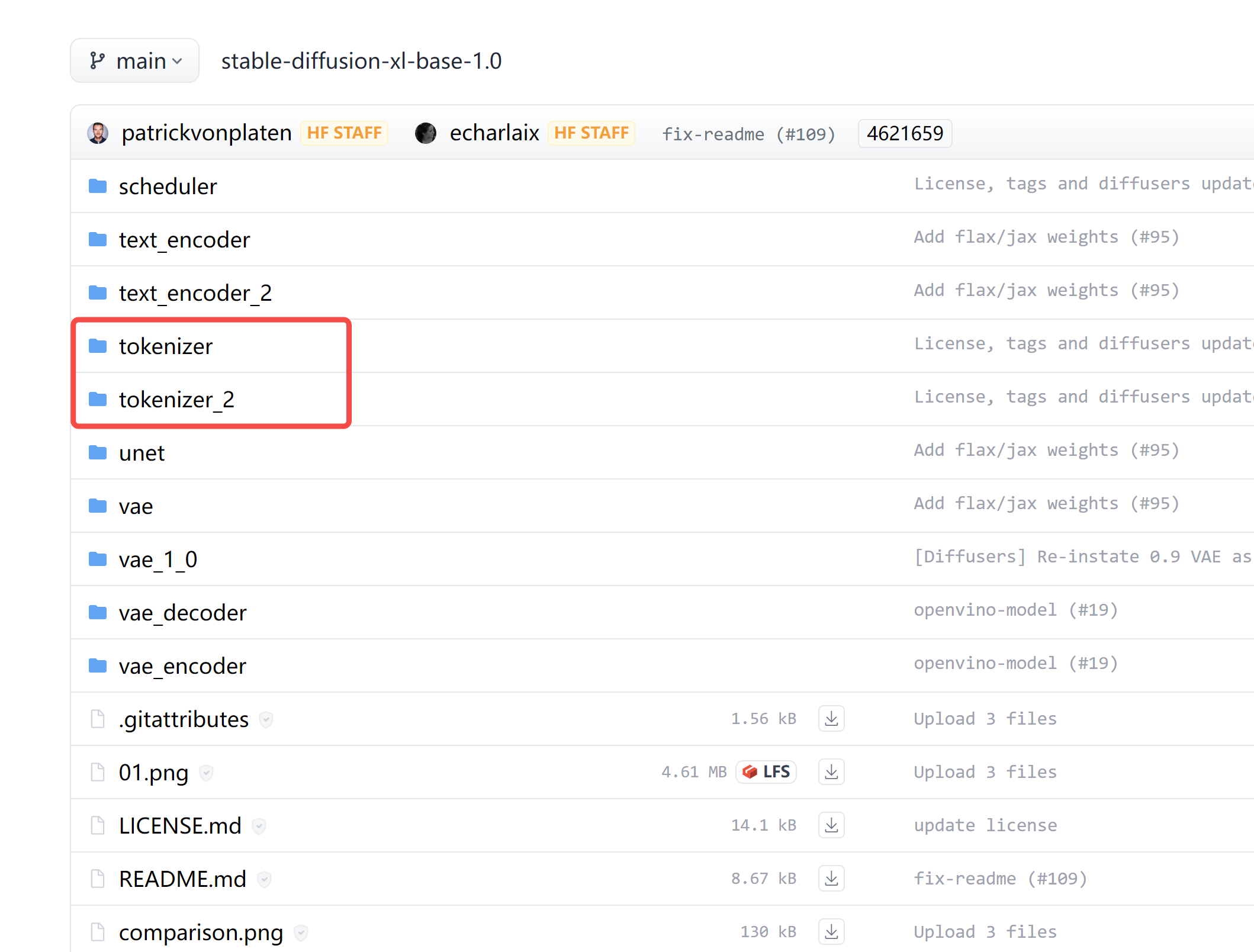
【深度学习】sdxl中的 text_encoder text_encoder_2 区别
镜像问题是:https://editor.csdn.net/md/?articleId=135867689 代码仓库: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main 截图: 为什么有两个CLIP编码器 text_encoder 和 text_encoder_2 ? 在仔细阅读这些代
【深度学习】sdxl中的 tokenizer tokenizer_2 区别
代码仓库: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main 截图: 为什么有两个分词器 tokenizer 和 tokenizer_2? 在仔细阅读这些代码后,我们了解到 tokenizer_2 主要是用于 refiner 模型的。 # Load text tokenizer(s)i
AI绘画与多模态原理解析:从CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo
前言 终于开写本CV多模态系列的核心主题:stable diffusion相关的了,为何执着于想写这个stable diffusion呢,源于三点 去年stable diffusion和midjourney很火的时候,就想写,因为经常被刷屏,但那会时间错不开去年11月底ChatGPT出来后,我今年1月初开始写ChatGPT背后的技术原理,而今年2月份的时候,一读者“天之骄子呃”在我这篇Chat
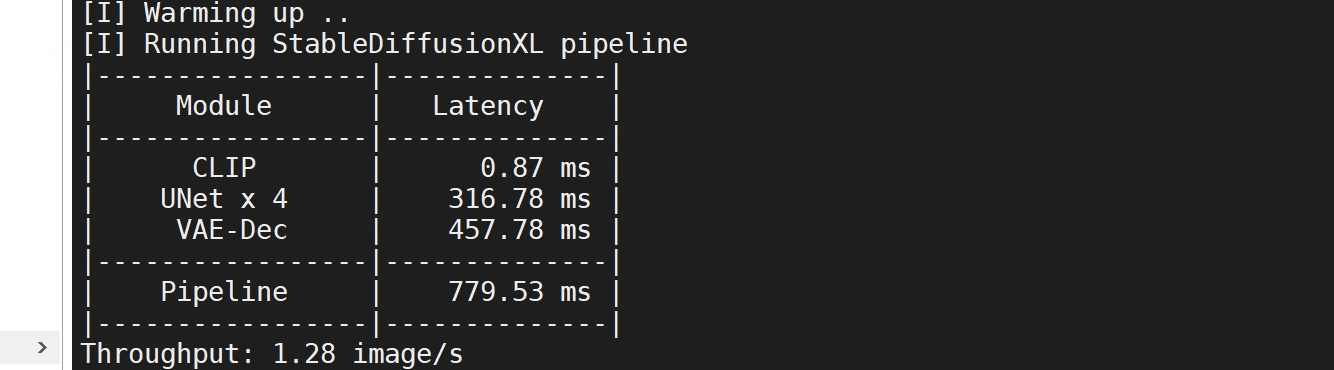
【深度学习】SDXL tensorRT 推理,Stable Diffusion 转onnx,转TensorRT
文章目录 sdxl 转 diffusers转onnx转TensorRT sdxl 转 diffusers def convert_sdxl_to_diffusers(pretrained_ckpt_path, output_diffusers_path):import osos.environ["HF_ENDPOINT"] = "https://hf-mirror.com" #

以对象为中心的视频编辑;SDXL高质量缩小版;Transformer在FPGA上实现12.8倍速度提升;深入研究ViT固有问题
本文首发于公众号:机器感知 以对象为中心的视频编辑;SDXL高质量缩小版;Transformer在FPGA上实现12.8倍速度提升;深入研究ViT固有问题 VASE: Object-Centric Appearance and Shape Manipulation of Real Videos 现有方法通过文生图模型来做视频编辑任务,然而这些方法大多使用文本编辑整个视频帧,其只专注于
【深度学习】SDXL tensorRT 推理
stabilityai/stable-diffusion-xl-1.0-tensorrt 项目:https://huggingface.co/stabilityai/stable-diffusion-xl-1.0-tensorrt TensorRT环境: git clone https://github.com/rajeevsrao/TensorRT.gitcd TensorRTgit