synthesis专题
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 精读
1 传统视图合成和NeRF(Neural Radiance Fields) 1.1 联系 传统视图合成和NeRF的共同目标都是从已有的视角图像中生成新的视角图像。两者都利用已有的多视角图像数据来预测或合成从未见过的视角。 1.2 区别 1.2.1 几何表示方式 传统视图合成:通常使用显式几何模型(如深度图、网格、点云)或其他图像处理方法(如基于图像拼接或光流的方法)来生成新的视图。这些

CSS 的font-synthesis属性与中文体验增强
CSS的font-synthesis属性与中文体验增强的关系主要体现在字体样式的合成与控制上。然而,需要注意的是,font-synthesis属性主要是用来控制浏览器是否应该合成缺少的粗体、斜体等字体样式的,它并不直接针对中文体验的优化,但它对于确保中文文本在字体样式不足时能够有更好的展示效果具有一定的作用。 font-synthesis属性的基本作用 font-synthesis属性用于指定
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 翻译
NeRF:将场景表示为用于视图合成的神经辐射场 引言。我们提出了一种方法,该方法通过使用稀疏的输入视图集优化底层连续体场景函数来实现用于合成复杂场景的新视图的最新结果。我们的算法使用全连通(非卷积)深度网络来表示场景,其输入是单个连续的5D坐标(空间位置(x,y,z)和观察方向(θ,φ)),其输出是该空间位置处的体积密度和与观察相关的发射辐射。我们通过查询沿着相机光线的5D坐标来合成视图,并使用
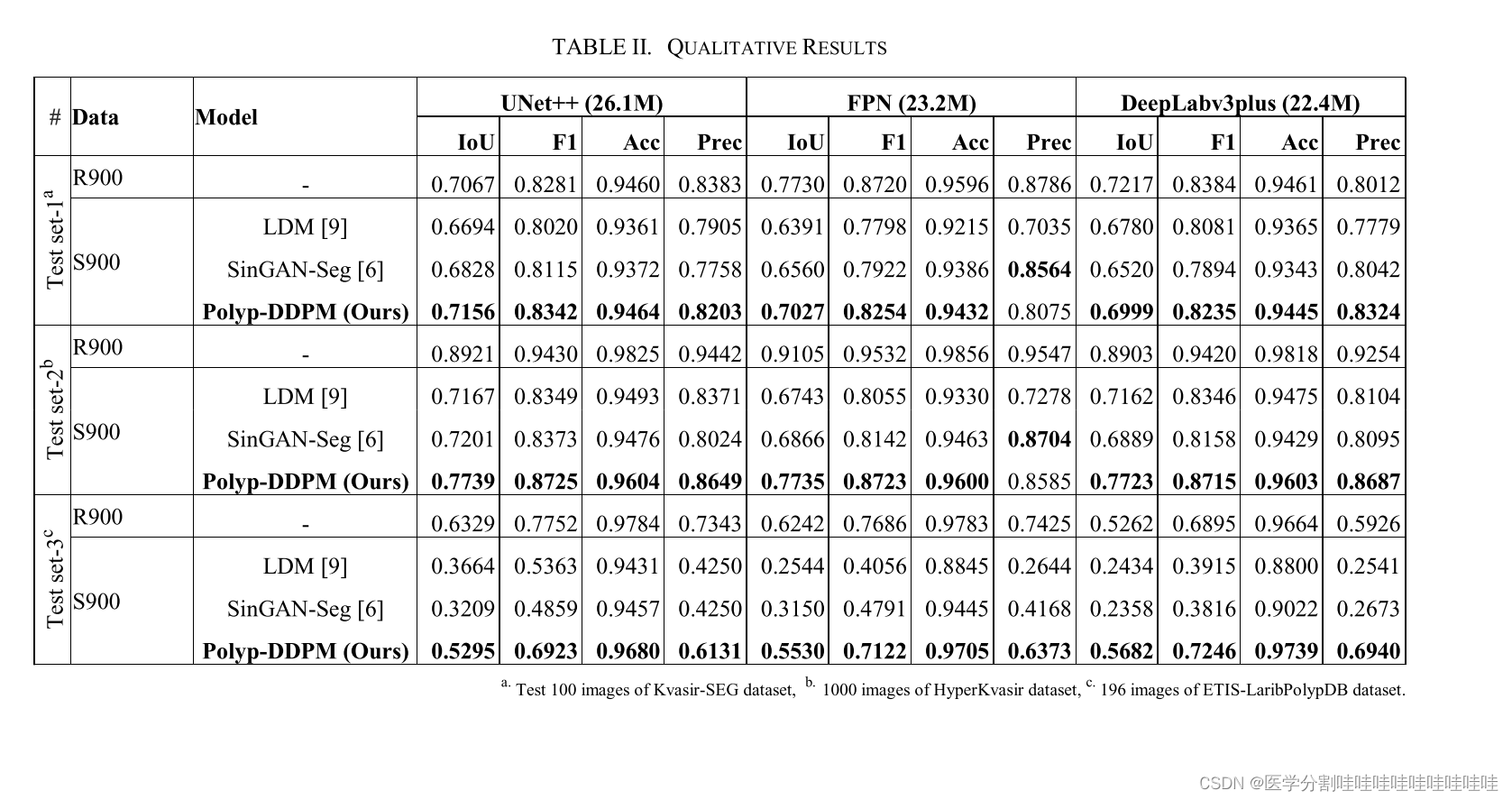
Polyp-DDPM: Diffusion-Based Semantic Polyp Synthesis for Enhanced Segmentation
Polyp- ddpm:基于扩散的语义Polyp合成增强分割 摘要: 本研究介绍了一种基于扩散的方法Polyp-DDPM,该方法用于生成假面条件下息肉的逼真图像,旨在增强胃肠道息肉的分割。我们的方法解决了与医学图像相关的数据限制、高注释成本和隐私问题的挑战。通过对分割掩模(代表异常区域的二进制掩模)的扩散模型进行调节,poly - ddpm在图像质量(实现fr起始距离(FID)得分为78.47
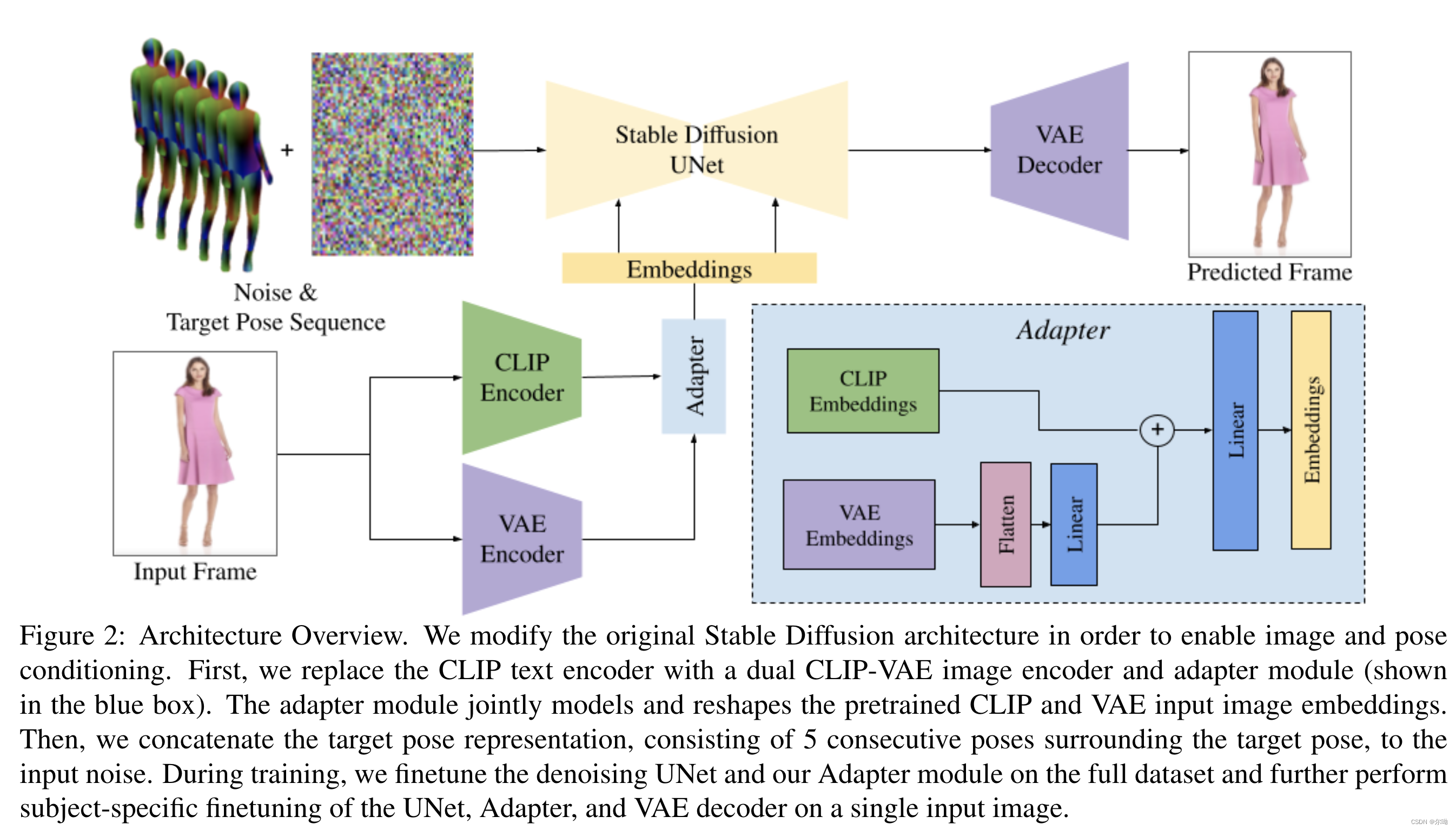
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
UW&UCB&Google&NVIDIA ICCV23https://github.com/johannakarras/DreamPose?tab=readme-ov-file 问题引入 输入参考图片 x 0 x_0 x0和pose序列 { p 1 , ⋯ , p N } \{p_1,\cdots,p_N\} {p1,⋯,pN},输出对应视频 { x 1 ′ , ⋯ , x N ′ }
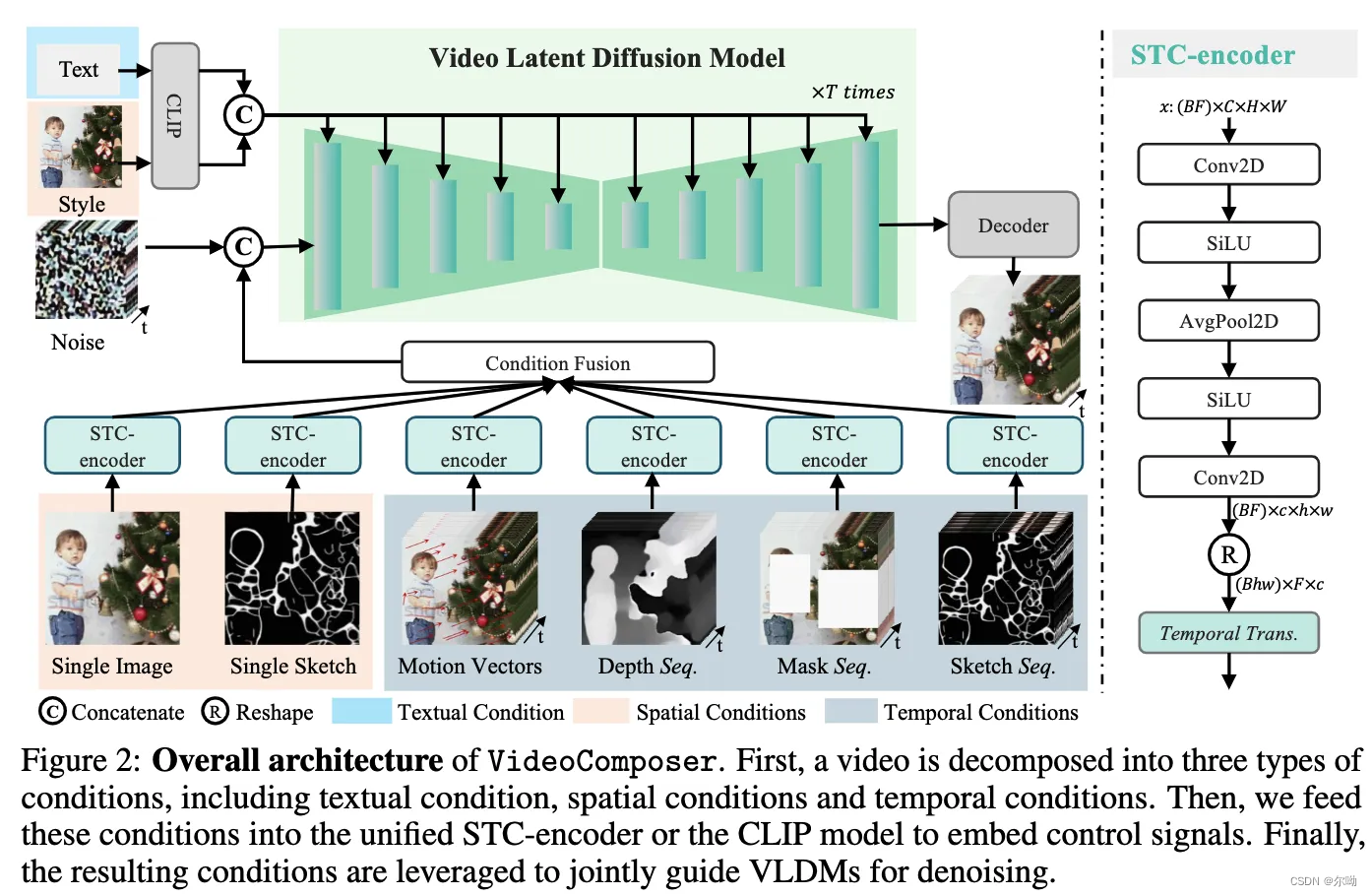
VideoComposer: Compositional Video Synthesis with Motion Controllability
decompose videos into three distinct types of conditions: textual conditions, spatial conditions, temperal conditions 条件的内容: a. textual condition: coarse grained visual content and motions, 使用opencl
![[Classifier-Guided] Diffusion Models Beat GANs on Image Synthesis](https://img-blog.csdnimg.cn/direct/f1a1051fbfb7497890b2f36e6e3ec2e9.png)
[Classifier-Guided] Diffusion Models Beat GANs on Image Synthesis
1、介绍 针对diffusion models不如GAN的原因进行改进: 1)充分探索网络结构 2)在diversity和fidelity之间进行trade off 2、改进 1)在采样步数更少的情况下,方差设置为固定值并非最优。需要将表示为网络预测的v
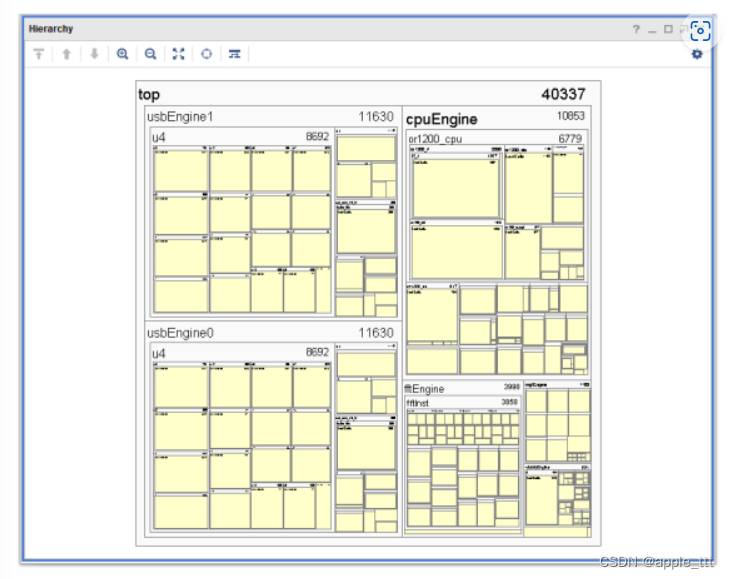
Vivado使用(5)——使用块综合策略(Block Synthesis)
目录 一、概述 1.1 使用块级综合的优势 1.2 注意事项 二、设置一个块级综合流程 三、块级综合选项 一、概述 在 AMD Vivado™ 综合中,有许多策略和全局设置可供你自定义设计的综合方式。下图展示了综合设置中可用的预定义策略。而“Vivado 预配置策略表”给出了各种预设策略的横向比较。 你可以使用 RTL 或 XDC 文
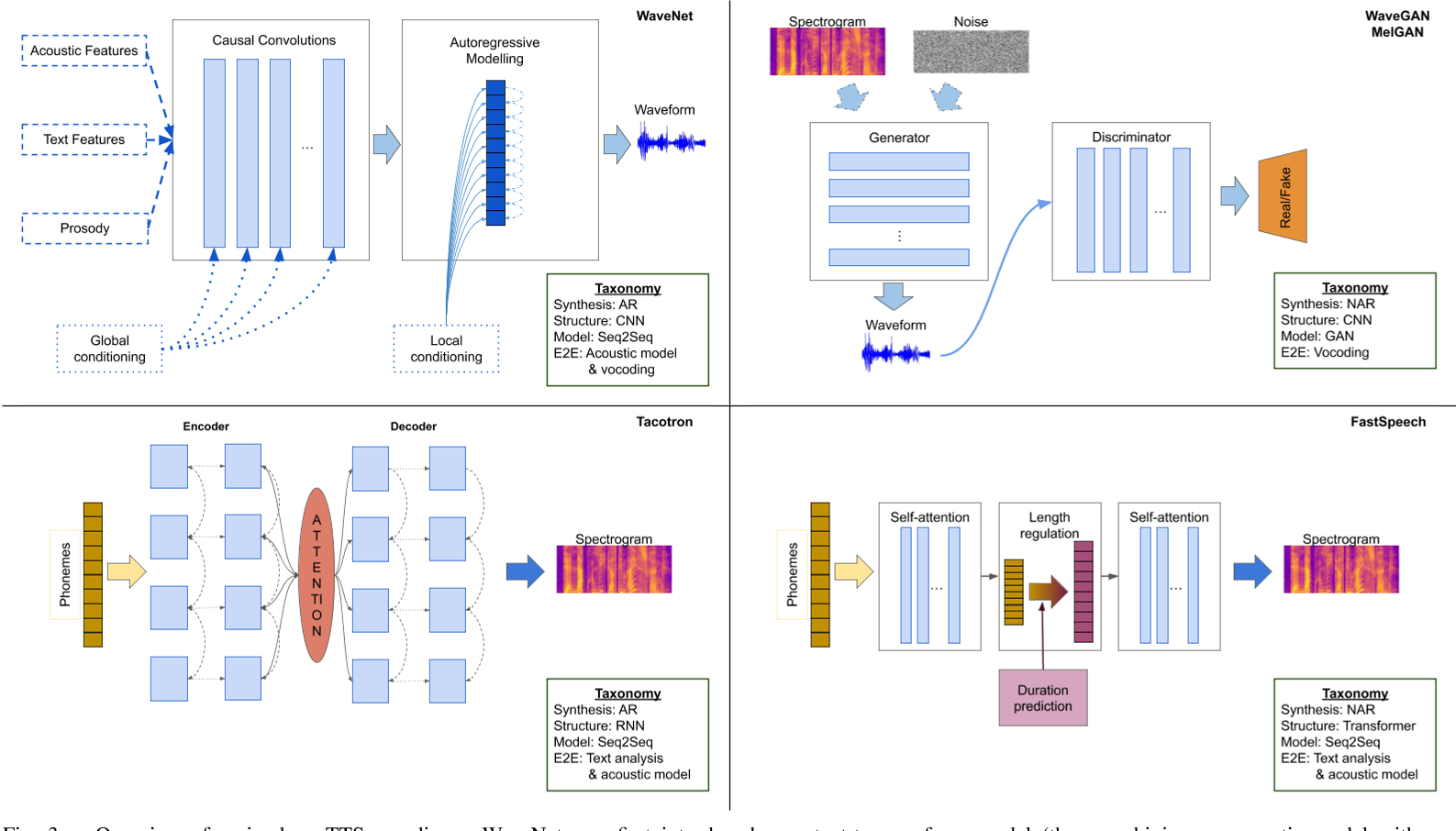
语音合成综述Speech Synthesis
目录 语音合成概述语音信号基础语音特征提取音库制作和文本前端声学模型声码器 一、语音合成概述 语音信号的产生分为两个阶段,信息编码和生理控制。首先在大脑中出现某种想要表达的想法,然后由大脑将其编码为具体的语言文字序列,及语音中可能存在的强调、重读等韵律信息。经过语言的组织,大脑通过控制发音器官肌肉的运动,产生出相应的语音信号。其中第一阶段主要涉及人脑语言处理方面,第二阶段涉及语音信号产生的生
web Speech Synthesis 文字语音播报,Audio 播放base64提示音
SpeechSynthesisUtterance基本介绍 SpeechSynthesisUtterance是HTML5中新增的API,用于将指定文字合成为对应的语音.也包含一些配置项,指定如何去阅读(语言,音量,音调)等 SpeechSynthesisUtterance基本属性 SpeechSynthesisUtterance.lang 获取并设置话语的语言SpeechSynthesisUtt
【 WPF】使用 System.Speech.Synthesis 命名空间中的 SpeechSynthesizer 类来朗读文本
在 WPF 中,你可以使用 System.Speech.Synthesis 命名空间中的 SpeechSynthesizer 类来朗读文本。下面是一个简单的示例代码,演示了如何使用 SpeechSynthesizer 类来朗读文本: using System;using System.Windows;using System.Speech.Synthesis;namespace YourNa

语音合成综述——亚洲微软谭旭《A Survey on Neural Speech Synthesis》上篇
受老师关怀、同学帮助,研一磕磕绊绊也算过去了,回过头来总结一下这一年入门不知道入没入进去的语音合成,正好从这篇大佬的综述理一理脉络,也算是研一的一个总结吧。 下图是本篇论文的结构框架图 论文从两个角度去总结这些年TTS语音合成的发展史,key components和advanced topics,因为文章很长,且我的知识储备并不能覆盖所有的模型,所以我会按照我的进度(较为热门易懂的端到端模型)去
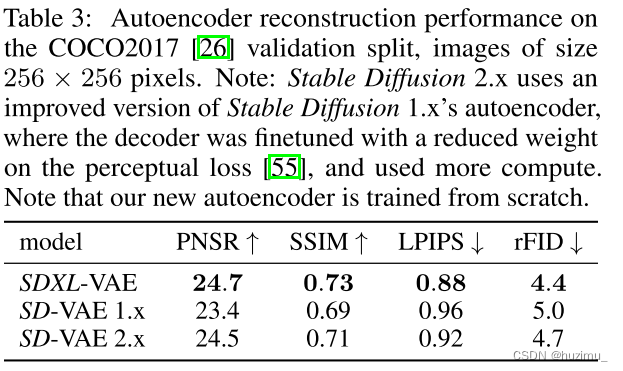
论文阅读:SDXL Improving Latent Diffusion Models for High-Resolution Image Synthesis
SDXL Improving Latent Diffusion Models for High-Resolution Image Synthesis 论文链接 代码链接 介绍 背景:Stable Diffusion在合成高分辨率图片方面表现出色,但是仍然需要提高本文提出了SD XL,使用了更大的UNet网络,以及增加了一个Refinement Model,以进一步提高图片质量。 提高SD的

【论文阅读】High-Resolution Image Synthesis with Latent Diffusion Model
High-Resolution Image Synthesis with Latent Diffusion Model 引用: Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//Proceedings of the IEEE/CVF c

论文阅读:《High-Resolution Image Synthesis with Latent Diffusion Models》
High-Resolution Image Synthesis with Latent Diffusion Models 论文链接 代码链接 What’s the problem addressed in the paper?(这篇文章究竟讲了什么问题?比方说一个算法,它的 input 和 output 是什么?问题的条件是什么) 这篇文章提出了一种合成高分辨率图片的潜在空间扩散模型(LDM

【论文阅读】An Introduction to Image Synthesis with Generative Adversarial Nets --- 文本to图像,图像to图像生成,图像合成
论文原文链接: 本博客根据博主对本论文的阅读和理解所写,重点关注个人理解方便,非逐句翻译,望周知。如需深入了解论文详情,请阅读原文。 作者:He Huang, Philip S. Yu (University of Illinois at Chicago) and Changhu Wang (ByteDance AI Lab); 发表位置:Arxiv 2018; 摘要:GAN在许多领域展现

torch运行synthesis的代码可能会遇到的问题及解决方案
如果想用cuda,一定要先装!!!! 1. 安装 cuda 和 cudnn http://blog.csdn.net/sun7_she/article/details/68946966 http://blog.csdn.net/iotlpf/article/details/54175064 想要运行代码,可能会遇到的问问题及解决方法: 2:安装 loadcaffe 会出现以

基于PaddlePaddle的飞桨论文解读:StarGAN v2: Diverse Image Synthesis for Multiple Domains
目录 摘要 StarGAN v2网络架构 实验 1.Baselines 2.数据集 3.评价指标 实验结果分析 1.个别成分分析 2.多种图像合成方法的比较 结论 模型代码(model.py) 主体代码(main.py) 总结 摘要 一个好的图像到图像的翻译模型应该学习不同视觉域之间的映射,同时满足以下特性:1)生成图像的多样性 2)多域的可伸缩性
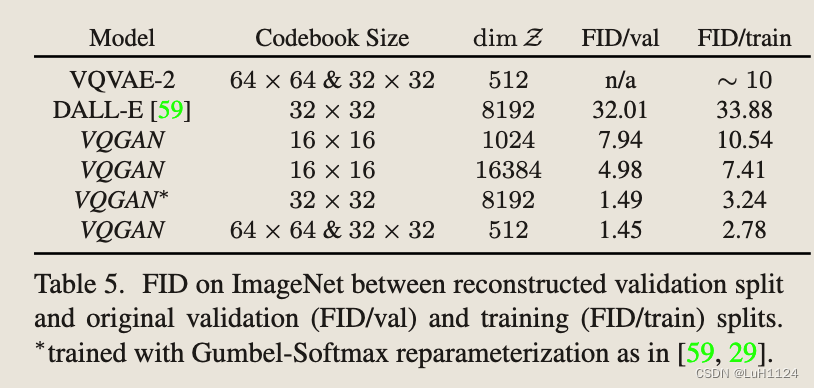
【论文阅读笔记】Taming Transformers for High-Resolution Image Synthesis
Taming Transformers for High-Resolution Image Synthesis 记录前置知识AbstractIntroductionRelated WorkMethodLearning an Effective Codebook of Image Constituents for Use in TransformersLearning the Composit

HTML5语音合成Speech Synthesis API简介
要在前端实现语音合成,即将文字讲述出来,一开始考虑用百度tts语音合成的方法,后来发现html5 本身就支持语音合成。就直接用html5的咯,百度的那个还有调用次数限制,配置还麻烦 一、关于HTML5语音Web Speech API HTML5中和Web Speech相关的API实际上有两类,一类是“语音识别(Speech Recognition)”,另外一个就是“语音合成(Speech Syn

Tortoise-tts Better speech synthesis through scaling——TTS论文阅读
笔记地址:https://flowus.cn/share/a79f6286-b48f-42be-8425-2b5d0880c648 【FlowUs 息流】tortoise 论文地址: Better speech synthesis through scaling Abstract: 自回归变换器和DDPM:自回归变换器(autoregressive transformers)是一种基于变换
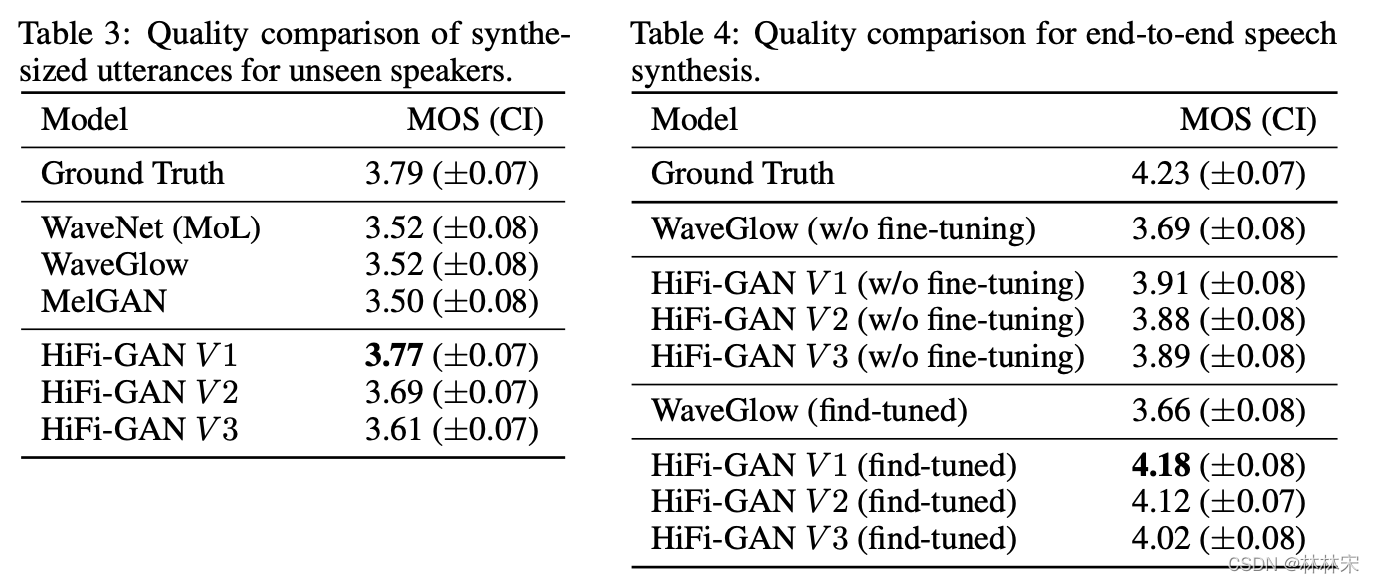
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
会议:2020 NIPS 单位:韩国KAKAO 作者:Jungil Kong, Jaehyeon Kim 文章主页 开源代码 使用心得: hifigan的收敛速度和效果都比PWG要好一点;hifigan预测真实值表现良好,但是和声学模型接在一起之后有电音(杂音),主要是两个系统的mismatch(真实mel-spec和预测的mel-spec之间的差异)2的解决方法:声学模型预测的更精准一些;vo

022_SSS_Novel View Synthesis with Diffusion Models
Novel View Synthesis with Diffusion Models 1. Introduction 本文利用diffusion模型,在给定参考图的条件下,生成指定pose的图像,作者称为3DiM。并且可以在给定一张特定视角的图的条件下,生成其他所有视角的图。 本文的主要贡献: 提出了3DiM模型,利用diffusion实现novel view synthesis。提出了s
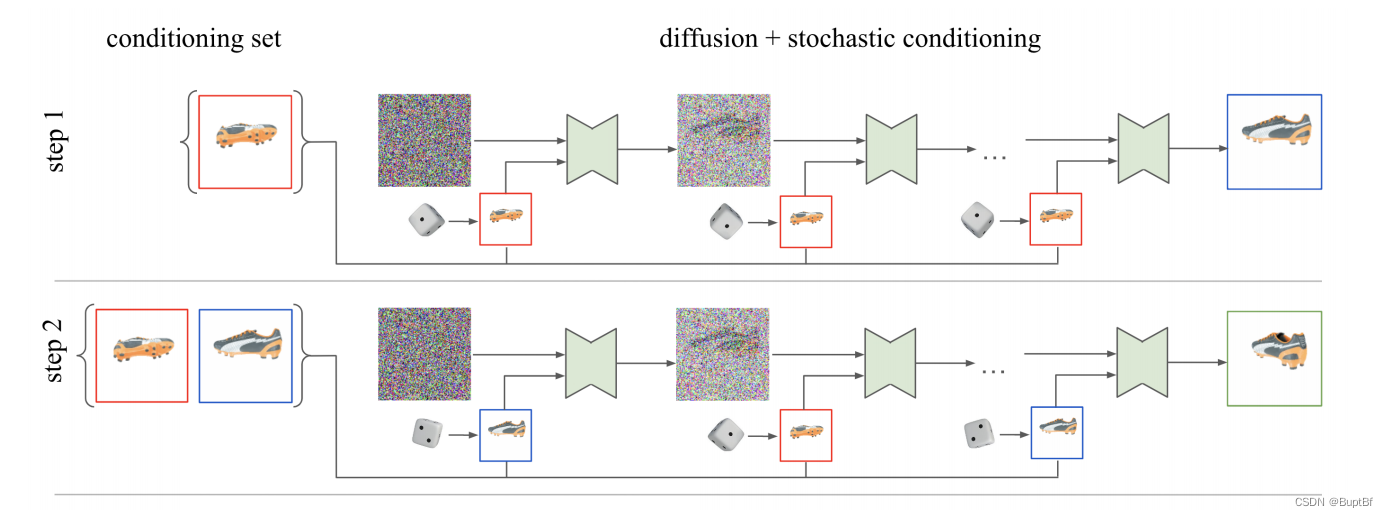
生成系列论文:基于diffusion的3d图像的生成:Novel View Synthesis with Diffusion Models(一)
Novel View Synthesis with Diffusion Models 文章的原地址为:https://arxiv.org/abs/2210.04628 想要直接生成一个3d图像比较困难 作者的研究动机主要是,在直接生成一个完整的3d空间点云的时候较为困难,于是作者想要转而寻求其他的方法,作者最终采用的方法是不断地生成3d图像的各个角度的视图,来完成最终的生成。也就是本文的最终目
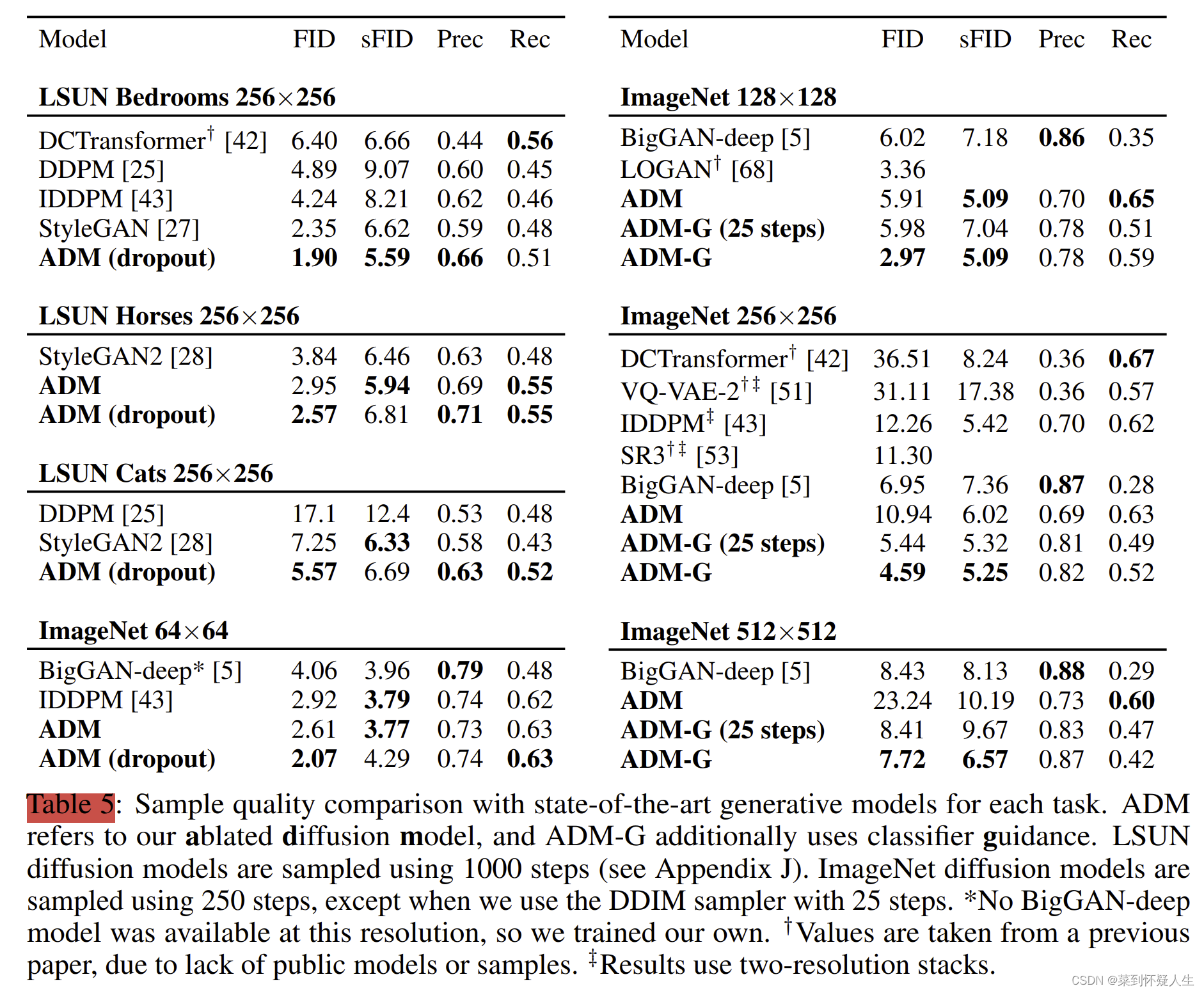
深度学习(生成式模型)——ADM:Diffusion Models Beat GANs on Image Synthesis
文章目录 前言基础模型结构UNet结构Timestep Embedding关于为什么需要timestep embedding global attention layer 如何提升diffusion model生成图像的质量Classifier guidance实验结果 前言 在前几篇博文中,我们已经介绍了DDPM、DDIM、Classifier guidance等相关的扩散模型
深度学习(生成式模型)——ADM:Diffusion Models Beat GANs on Image Synthesis
文章目录 前言基础模型结构UNet结构Timestep Embedding关于为什么需要timestep embedding global attention layer 如何提升diffusion model生成图像的质量Classifier guidance实验结果 前言 在前几篇博文中,我们已经介绍了DDPM、DDIM、Classifier guidance等相关的扩散模型